MIT 6.S978 Deep Generative Models 这门课最有价值的地方,不只是介绍了若干流行模型,而是给出了一条相当清楚的主线:生成模型并不是一组彼此无关的方法名词,而是在回答同一类问题时做出的不同建模选择。
如果只按模型名称去记忆,很容易把 VAE、PixelCNN、GAN、Diffusion、Flow Matching、Consistency Models 看成六种平行方案;但从第一性原理出发,它们其实都在回答四个问题:
- 数据分布如何表示?
- 训练时优化的对象是什么?
- 采样时如何从简单分布走到数据分布?
- 每一种方法解决了什么,又留下了什么问题?
这篇文章不再重复各单篇文章中的推导细节,而是尝试把整门课拉通成一张地图。理解这张地图之后,再回看每个模型的目标函数和代码实现,位置会清楚很多。
1. 一切问题的起点:如何学习一个高维数据分布
生成模型的目标,最朴素地说,就是学习数据分布 。如果训练集是图像,那么 是高维像素;如果训练集是文本,那么 是 token 序列。困难在于,这个分布通常非常复杂,无法直接写出,也无法直接采样。
因此,现代生成模型的发展可以理解为对同一个目标的几条不同路线:
- 有的路线显式写出概率分布,并尽量优化 likelihood。
- 有的路线不直接写出显式密度,而是学习一个可采样的生成过程。
- 有的路线先把问题拆成很多局部条件分布。
- 有的路线先人为构造一条从数据到噪声的简单路径,再学习它的逆过程。
这些路线的差别,本质上不是“谁更复杂”,而是“谁选择了怎样的分解方式”。
2. 第一条路线:先引入潜变量,再做近似推断
VAE 代表的是潜变量模型路线。它的基本设定是,观测数据 并不是直接产生的,而是先从一个简单先验 中采样潜变量 ,再由条件分布 生成出来:
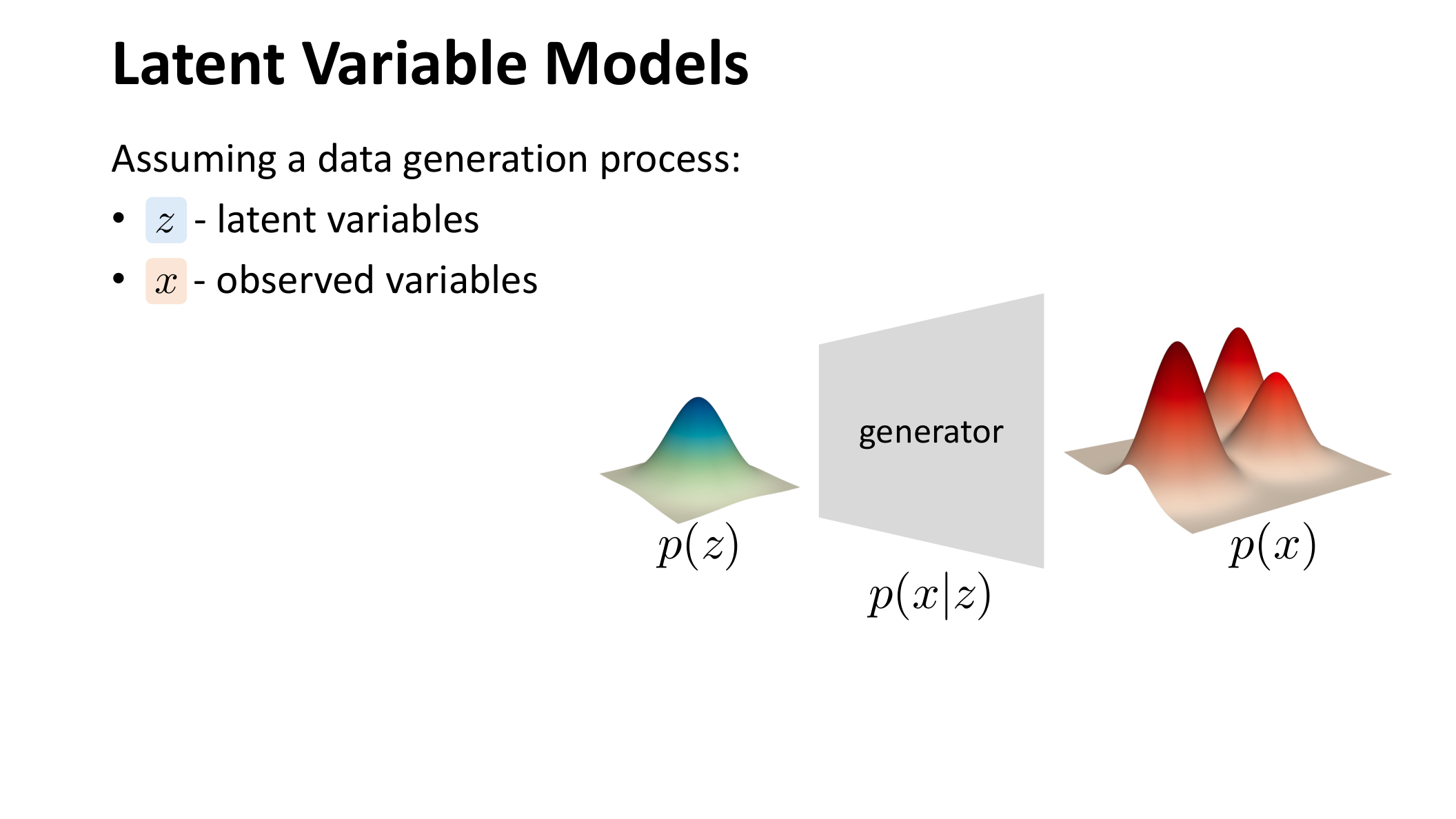
图:MIT 6.S978 lec2_vae.pdf 中对潜变量模型的示意。
这一路线的优点是结构清楚。模型显式假设:高维数据背后存在低维潜结构。但困难也很快出现了。为了优化 ,需要处理不可解的后验分布 ,于是课程自然引出变分推断与 ELBO。
从整门课的视角看,VAE 的重要性不在于今天样本质量最强,而在于它第一次把以下几件事放进了同一个框架:
- 概率建模
- 近似推断
- 神经网络参数化
- 可导采样
这条路线的核心思想是:如果直接建模太难,就引入一个隐藏层次,让复杂分布变成“简单先验 + 条件生成器”的组合。
它留下的问题也很明确:
- 需要近似后验,目标函数不是直接的对数似然,而是下界。
- 潜变量分布与解码器的选择会限制表达能力。
- 在高保真样本生成上,简单 VAE 往往不如后来的方法。
3. 第二条路线:不引入潜变量,直接分解联合分布
自回归模型走的是另一条完全不同的路。它不再假设一个显式潜变量,而是直接利用概率链式法则,把联合分布写成条件分布的乘积:

图:MIT 6.S978 lec3_ar.pdf 中对自回归分解的说明。
这条路线非常直接。既然高维联合分布难学,那就把它改写成一串一维或低维条件分布。只要每一步条件分布能学好,整体联合分布也就被确定了。
这正是 PixelCNN 以及后来的语言模型共同遵循的原则。两者在形式上不同,一个主要使用卷积和掩码结构,一个主要使用注意力机制,但本质是同一个分解:
- 训练时,给定真实前缀,预测下一个元素。
- 生成时,从左到右或按固定顺序逐步采样。

图:MIT 6.S978 lec3_ar.pdf 中对 teacher forcing 的说明。
这条路线的优点也非常突出:
- likelihood 明确,可直接优化。
- 概念简单,不需要变分推断。
- 在文本这类天然序列数据上尤其有效。
它的代价则在于:
- 采样天然是串行的。
- 对图像这类高维对象,顺序选择本身就会影响建模效率。
- 模型把联合分布拆得很细,虽然易训练,但生成速度常常受限。
如果说 VAE 是“通过隐藏结构简化分布”,那么自回归模型就是“通过顺序分解简化分布”。
4. 第三条路线:不强调显式密度,而是直接学习生成器
GAN 出现时,重点发生了变化。它不再把主要精力放在显式 likelihood 上,而是提出另一个问题:如果目标是生成看起来足够真实的样本,是否一定要先把密度写清楚?
GAN 的回答是否定的。它直接学习一个生成器 ,把简单先验分布映射到数据空间;与此同时,训练一个判别器 ,区分真实样本与生成样本。二者通过对抗博弈共同训练。
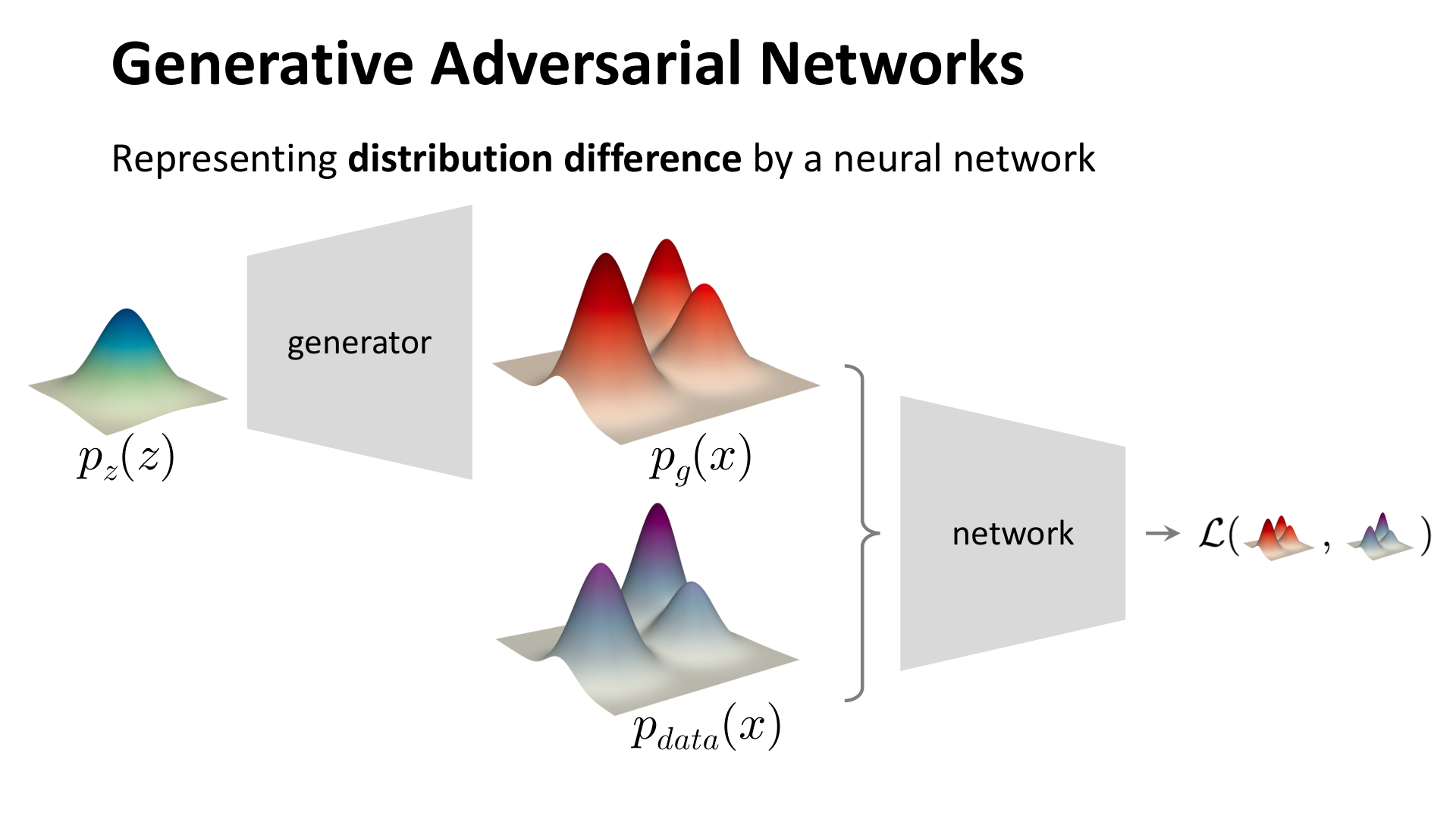
图:MIT 6.S978 lec4_gan.pdf 中对生成器与判别器结构的说明。
从整门课的脉络看,GAN 的历史作用是非常清楚的。它指出了一件事:生成模型不一定非要沿着显式密度建模这条路往前走。只要生成样本分布能够逼近真实数据分布,很多任务并不要求模型随时给出可计算的对数似然。
GAN 的贡献主要有两点:
- 直接把训练目标对准“生成样本与真实样本是否难以区分”。
- 在图像生成上显著推动了高保真样本质量的发展。
但它留下的问题同样成为后续发展的动力:
- 对抗训练不稳定。
- 模式崩塌较难彻底避免。
- 训练过程往往对结构、超参数与技巧较敏感。
因此,GAN 代表的不是“最终方案”,而是一种重要转向:从“拟合密度”部分转向“学习生成过程本身”。
5. 第四条路线:先设计一条从数据到噪声的路径,再学习逆过程
Diffusion 的核心想法,与前面三条路线都不同。它不是直接写一个复杂分布,也不是把联合分布拆成条件链,而是先人为构造一条简单而可控的前向过程:逐步向数据中加入噪声,直到分布接近标准高斯。然后再学习这条过程的逆向生成机制。
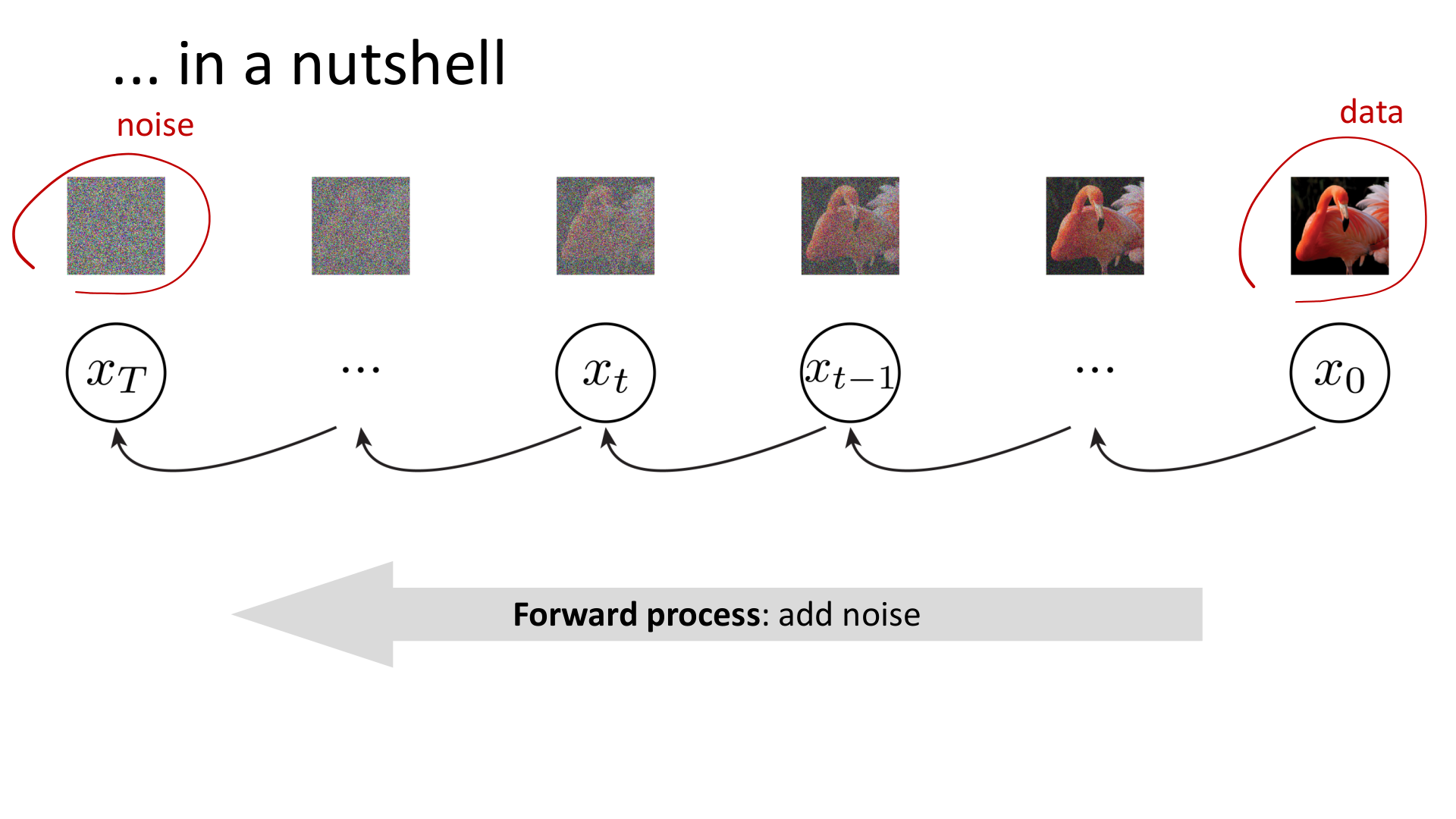
图:MIT 6.S978 lec5_diffusion.pdf 中的扩散模型总览。
这条路线最重要的思想是:如果直接从简单分布生成复杂分布太难,可以先人为设计一条“复杂到简单”的路径。因为前向加噪过程是已知的,于是问题被转化为学习逆过程。
课程在这里给出的逻辑非常关键:
- 固定前向加噪过程。
- 发现逆条件分布依赖数据分布,因此未知。
- 对逆过程做参数化近似。
- 把训练目标逐步化简为噪声预测。
- 再把噪声预测与 score matching 联系起来。
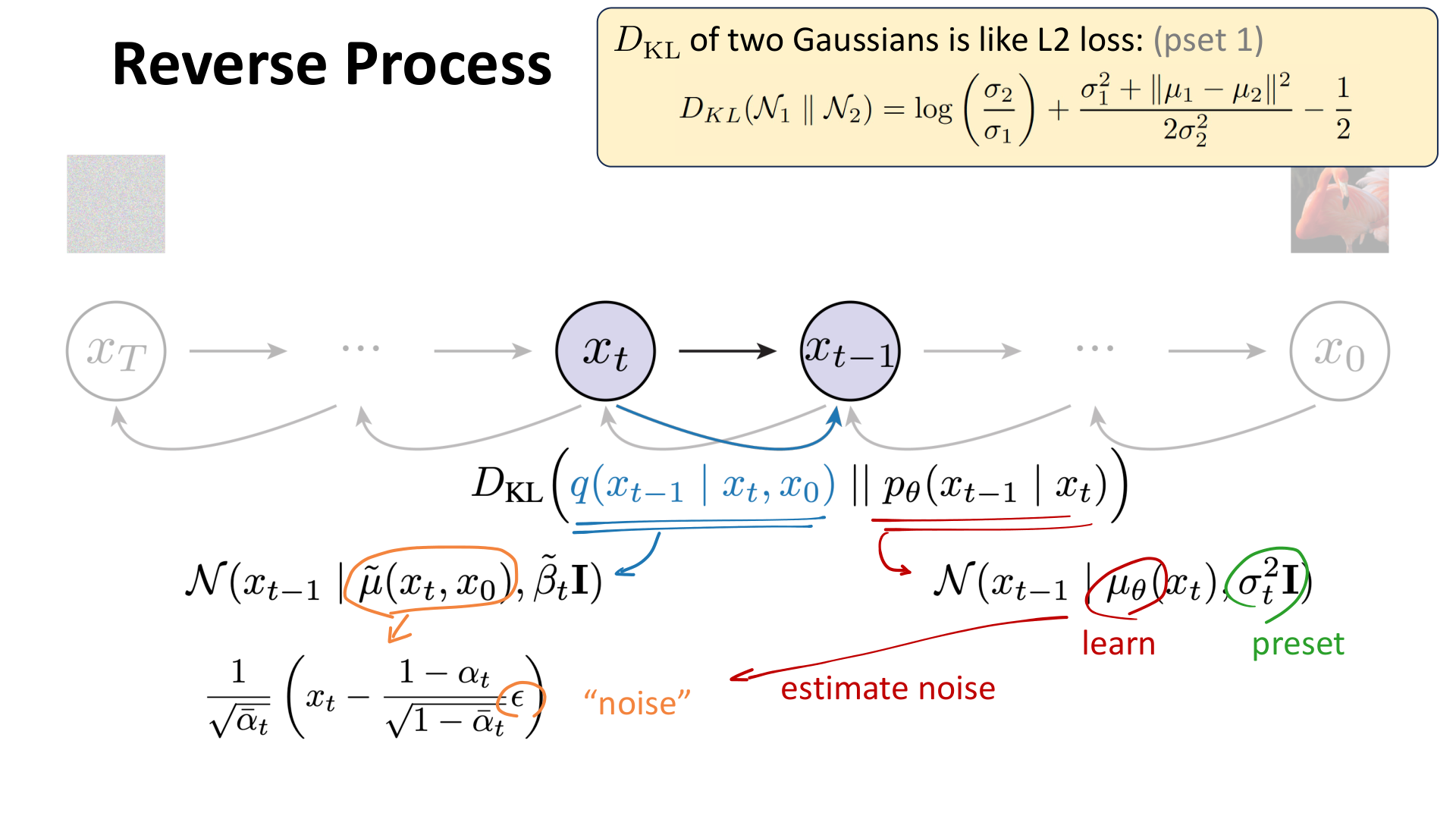
图:MIT 6.S978 lec5_diffusion.pdf 中对 DDPM 训练目标化简过程的总结。
这一点非常重要,因为它解释了为什么扩散模型最后看起来像是在做一个简单的均方误差回归,但本质上却仍然是一个严肃的概率建模问题。
Diffusion 的优势在于:
- 训练通常比 GAN 更稳定。
- 生成质量很高,尤其适合图像与多模态生成。
- 与 score matching、SDE/ODE 等视角自然相连,理论结构很丰富。
它的主要代价是:
- 采样通常较慢,需要多步迭代。
- 训练和推断都依赖一条较长的时间路径。
因此可以说,Diffusion 把生成问题重新组织成了“路径学习问题”。
6. 第五条路线:既然扩散可以看成连续路径,为何不直接学习速度场
当课程走到 Flow Matching 时,问题进一步收束。既然 Diffusion 和 score-based model 已经可以用连续时间与概率流来理解,那么是否有必要坚持“先加噪、再逆扩散”的离散叙事?是否可以直接学习一条把简单分布运输到数据分布的连续流?
Flow Matching 给出的答案是可以。它直接学习速度场 ,使样本沿着常微分方程演化:
与 Diffusion 相比,这里的重点不再是恢复每一步去噪条件分布,而是直接学习整条概率流的局部速度。
从课程脉络看,Flow Matching 并不是凭空出现的新方法,而是对前面连续时间理解的一次整理。它继承了扩散模型关于“从简单分布到复杂分布可以沿路径变形”的思想,但把建模对象从 score 或噪声,改成了速度场本身。
这条路线的价值在于:
- 解释上更接近连续动力系统与最优传输直觉。
- 可以摆脱某些离散扩散叙事带来的冗余。
- 与 ODE 求解器、更一般的概率流视角结合得更自然。
它说明课程已经从“具体算法”进一步推进到“统一连续时间视角”。此时不同模型之间的边界开始变得不那么绝对,关注点逐渐从“某个模型名字”转向“到底在学习哪种向量场或概率流”。
7. 第六条路线:如果生成路径已经学到,能否进一步压缩采样步数
Consistency Models 继续沿着“加速采样”这个方向向前走。Diffusion 与 Flow Matching 已经给出了高质量生成的路径建模方法,但它们普遍存在一个工程问题:推断通常需要多步迭代。
Consistency Models 抓住的关键点是:同一条生成轨迹上的不同噪声点,应该在某种意义下对应到同一个最终数据点或同一局部解。于是模型不再只学习局部去噪或局部速度,而是学习一种在不同时间层面上保持一致的映射。
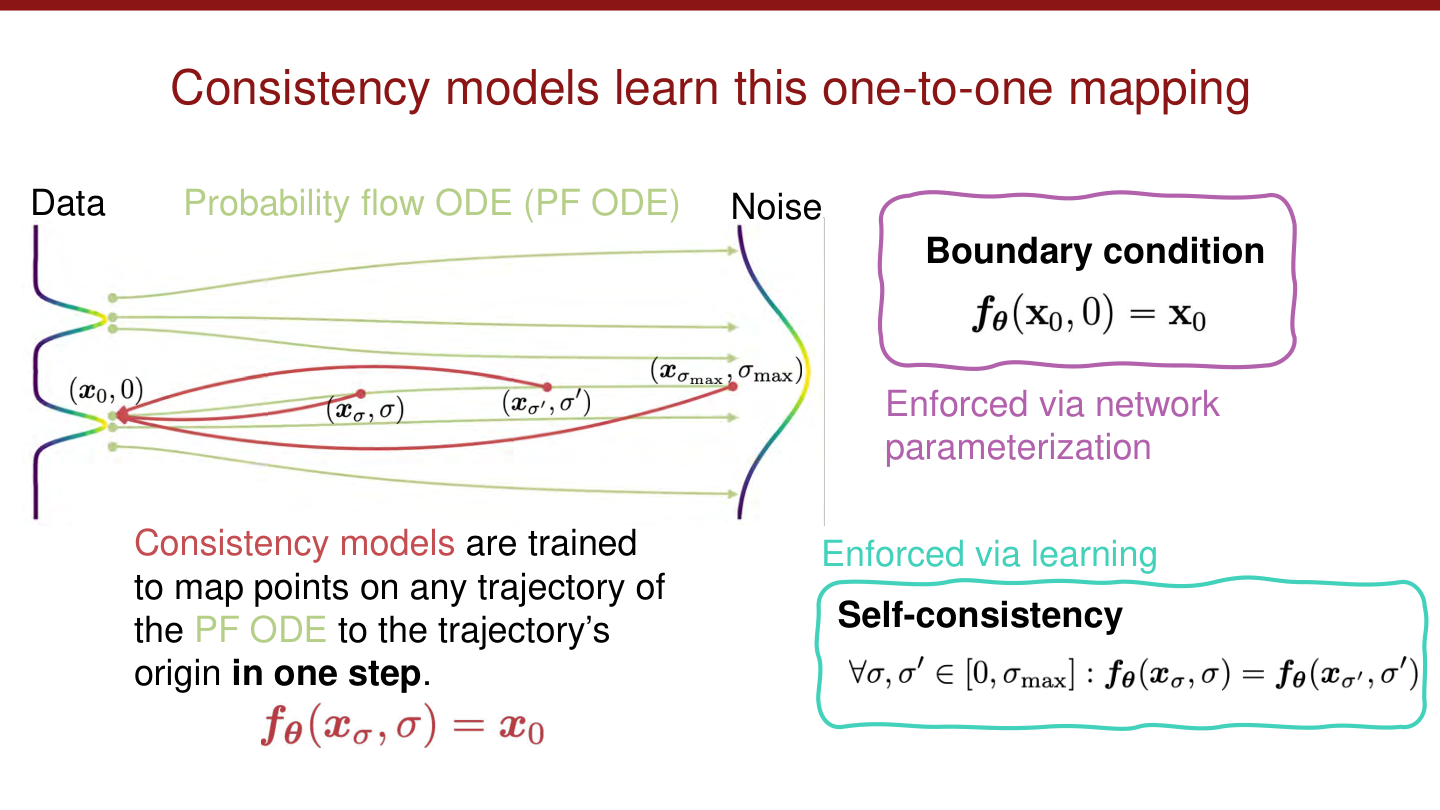
图:MIT 6.S978 CM_lecture.pdf 中对 consistency mapping 的示意。
这条路线的意义很清楚:
- 它不是在否定 Diffusion,而是在继承已有轨迹结构之后,进一步压缩采样成本。
- 它把重点从“怎样精细模拟整个逆过程”转向“怎样直接学到一个稳定的少步映射”。
因此,Consistency Models 可以看成生成模型中的一次再蒸馏:利用已有路径模型的知识,换取更快的推断效率。
8. 这六类模型其实在同一张坐标系里
如果把整门课重新压缩,可以得到一张更简洁的坐标图。
8.1 它们在“分布表示方式”上的差别
- VAE:用潜变量和条件生成分布来表示数据分布。
- Autoregressive:用链式法则分解联合分布。
- GAN:不强调显式密度,直接学习生成器诱导出的样本分布。
- Diffusion:通过一条已知的前向噪声路径与一条学习得到的逆路径来表示生成过程。
- Flow Matching:用连续时间速度场表示概率流。
- Consistency Models:用轨迹上一致的映射压缩生成路径。
8.2 它们在“训练目标”上的差别
- VAE 优化的是 likelihood 的下界。
- Autoregressive 直接优化条件概率的对数似然。
- GAN 优化的是生成器和判别器之间的对抗目标。
- Diffusion 优化的是与逆过程一致的噪声预测或 score 目标。
- Flow Matching 优化的是速度场匹配。
- Consistency Models 优化的是不同时间点之间的一致性约束,常常配合蒸馏。
8.3 它们在“采样方式”上的差别
- VAE:先采样潜变量,再解码。
- Autoregressive:按顺序逐步采样。
- GAN:一次前向映射直接生成。
- Diffusion:从噪声出发,多步逆推。
- Flow Matching:沿 ODE 或连续流演化采样。
- Consistency Models:用少步甚至一步映射加速生成。
8.4 它们的演化关系
如果只看历史先后,会得到一串方法列表;但如果看问题驱动,就会看到更清楚的继承关系:
- VAE 解决了潜变量生成与近似推断如何结合的问题。
- 自回归模型解决了怎样直接而精确地分解联合分布的问题。
- GAN 说明高质量生成可以不依赖显式 likelihood。
- Diffusion 用更稳定的路径学习替代了脆弱的对抗训练。
- Flow Matching 把扩散进一步统一到连续概率流视角。
- Consistency Models 则针对多步采样代价继续向前推进。
因此,课程不是在堆模型,而是在不断更换“把复杂分布变得可学、可采样、可计算”的方式。
9. 如何理解今天的生成式 AI 模型
如果把这门课放到当前生成式 AI 的背景中,可以得到一个相对稳定的判断。
第一,文本生成的主流路线依然是自回归。大语言模型之所以成功,并不是因为它们与早期自回归模型毫无关系,而是因为它们在大规模数据、模型容量和注意力结构上把这一路线推进到了极致。
第二,图像与视频生成的主流路线在很长一段时间里主要沿着 Diffusion 及其变体发展,因为这条路线在训练稳定性与生成质量之间找到了较好的平衡。
第三,Flow Matching 与 Consistency 这样的方向说明,现代生成模型的重点已经不只是“能不能生成”,而是“能否在统一理论下更快、更稳定、更少步地生成”。
第四,VAE 这样的模型虽然不再是主流大模型的唯一核心,但潜变量、编码器、变分近似这些思想并没有消失,而是不断以新的形式回到多模态建模、表示学习和 latent diffusion 等系统中。
也就是说,今天的生成式 AI 并不是某一种模型一统天下,而是不同任务上不同建模路线的组合:
- 文本更偏自回归
- 图像更偏扩散与流模型
- 高效推断更依赖蒸馏、少步采样与一致性方法
- 多模态系统常常同时混合潜变量、编码器与条件生成机制
10. 如果只保留一个理解框架,应该保留什么
读完这门课之后,最值得保留的不是若干公式,而是下面这个判断框架:
面对一个生成模型,先问四件事:
- 它如何表示数据分布?
- 它训练时实际优化的是什么?
- 它采样时如何从简单分布走到复杂分布?
- 它是为了解决上一代方法的什么困难?
只要这四个问题能答清楚,很多看起来很新的模型都会自动落位。
从这个意义上说,MIT 6.S978 Deep Generative Models 这门课真正提供的,不只是一些模型知识,而是一套理解现代生成模型的方法。它把生成问题从“记忆若干技术名称”重新变回“分析分布、目标与路径如何组织”的问题。
11. 相关阅读
本系列已经分别整理了六篇单独文章:
- MIT 6.S978 Deep Generative Models(一):从 AutoEncoder 到 Variational AutoEncoder
- MIT 6.S978 Deep Generative Models(二):从联合分布分解到 PixelCNN
- MIT 6.S978 Deep Generative Models(三):从 Density Ratio Estimation 到 GAN
- MIT 6.S978 Deep Generative Models(四):从 Diffusion 到 Score Matching
- MIT 6.S978 Deep Generative Models(五):从 Diffusion ODE 到 Flow Matching
- MIT 6.S978 Deep Generative Models(六):从 Diffusion Distillation 到 Consistency Models
参考资料
- MIT 6.S978 Deep Generative Models, Course Schedule
- MIT 6.S978 Deep Generative Models,
lec2_vae.pdf - MIT 6.S978 Deep Generative Models,
lec3_ar.pdf - MIT 6.S978 Deep Generative Models,
lec4_gan.pdf - MIT 6.S978 Deep Generative Models,
lec5_diffusion.pdf - MIT 6.S978 Deep Generative Models,
CM_lecture.pdf - Yang Song, Score-based generative modeling blog
- Cambridge MLG, Flow Matching for Generative Modeling