在上一篇关于 Diffusion 的文章里,生成过程被理解为一条逐步去噪的逆过程。Consistency Models 延续了这条路线,但切入点已经发生变化:
既然 Diffusion 的问题不在“能不能生成”,而在“生成要走很多步”,那么是否可以直接学习一个把噪声映射回数据的快速映射?
理解这类模型可以按五步展开:
- 先指出 Diffusion 的慢采样问题;
- 再把问题转到 probability flow ODE;
- 接着定义 consistency model 的边界条件与自一致性;
- 然后讲如何从预训练 diffusion model 蒸馏;
- 最后说明它也可以不依赖 diffusion,直接从数据训练。
1. 问题首先不是“能不能生成”,而是“生成太慢”
Diffusion 模型已经可以生成很高质量的样本,但它通常需要多步甚至上百步采样。模型质量越高,采样路径往往也越长。这使得它在需要快速推理的场景里受到限制。

图:MIT 6.S978 CM_lecture.pdf 一开始就把问题摆得很直接。Diffusion 的难点不再只是建模,而是采样速度。
这也是 Consistency Models 的出发点。它关心的不是重新发明一条全新的生成理论,而是回答一个非常具体的问题:
- 能否保留 diffusion 系方法的分布建模能力;
- 同时把多步采样压缩成一步或少步映射。
因此,Consistency Models 最重要的性质不是“它比 Diffusion 更根本”,而是“它试图把 Diffusion 的连续轨迹压缩成可直接调用的映射”。
2. 从 reverse process 转到 probability flow ODE
这一讲的关键转折是:Consistency Models 并不直接学习离散时间上的逐步逆扩散链,而是转向连续时间的 probability flow ODE 视角。
在连续时间 diffusion 中,同一个边缘分布演化既可以由随机微分方程描述,也可以由一个确定性的 ODE 描述。后者就是 probability flow ODE。它的意义是:
- 随时间变化的分布仍然与 diffusion 对应;
- 但单条样本轨迹本身变成确定性的;
- 因而更适合讨论“一条轨迹上的点是否应该被映射到同一个终点”。
Consistency Models 正是在这个视角下定义的。它不是要求网络预测下一步,而是要求网络满足:
也就是把位于同一条 probability flow ODE 轨迹上的任意点,直接映射回这条轨迹对应的数据端点。
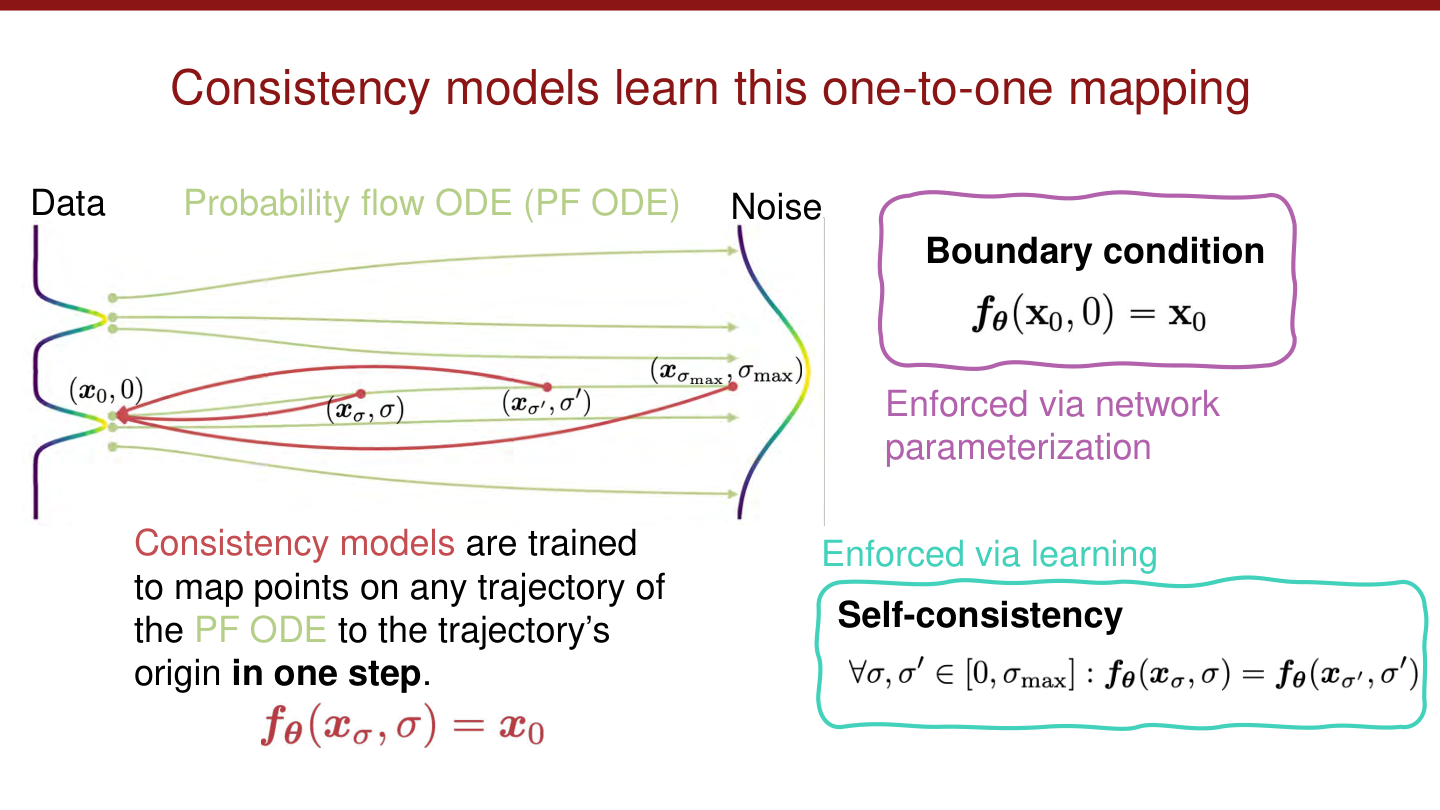
图:MIT 6.S978 CM_lecture.pdf 中对 Consistency Model 核心对象的概括。模型学习的不是“下一步怎么走”,而是“这条轨迹最终来自哪个数据点”。
这和 Diffusion 的差别很大:
- Diffusion 网络通常学习局部去噪量,例如噪声、score 或速度;
- Consistency Model 直接学习一个全局映射,把轨迹上的点拉回起点。
这也是它能够支持一步生成的根本原因。
3. 两个核心约束:边界条件与自一致性
如果一个模型真要把轨迹上的任意点映射回起点,那么至少要满足两个条件。
第一是边界条件:
这句话并不复杂,但非常重要。因为当噪声水平为零时,输入本身已经是数据点,模型不应该再去改动它。
第二是自一致性。对于同一条 probability flow ODE 轨迹上的任意两个点 和 ,都应该映射到同一个起点:
这就是 consistency 这个名字的来源。模型在同一条轨迹上给出的“答案”必须一致。

图:MIT 6.S978 CM_lecture.pdf 中对边界条件和自一致性的并列说明。前者是零噪声处的正确性,后者是整条轨迹上的一致性。
仅仅把这两个式子写出来还不够,真正的实现问题是:怎样把边界条件硬编码进网络结构里?
常用做法是使用 skip connection 形式的参数化:
并要求
这样在 时,模型自动退化为恒等映射。
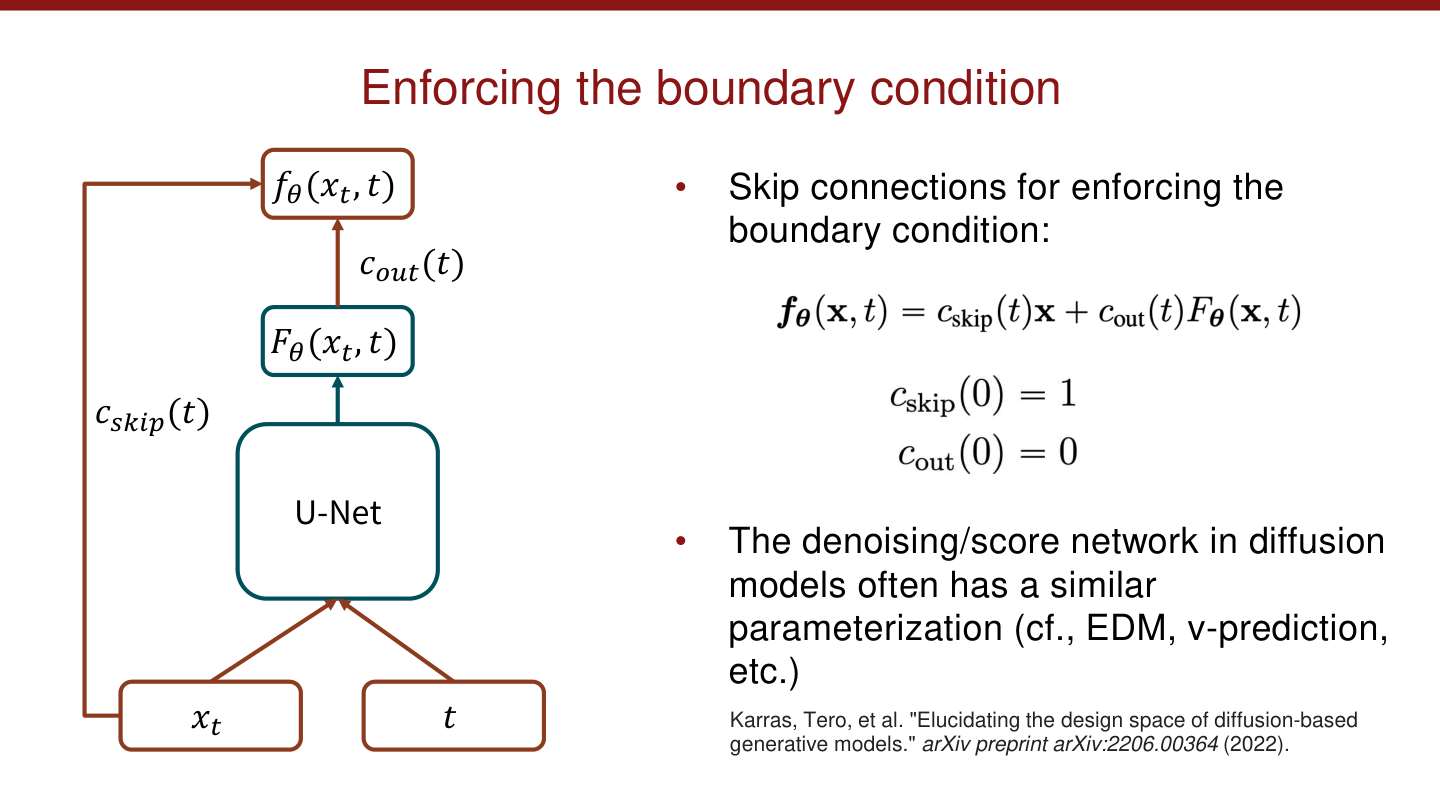
图:MIT 6.S978 CM_lecture.pdf 中关于边界条件参数化的结构图。这个技巧的意义在于,它把“希望模型满足边界条件”变成了“模型天然满足边界条件”。
4. 蒸馏训练:先借助一个预训练 diffusion model
先看 distillation 版本,因为这条路线最容易和已有的 diffusion 视角接起来。
假设已经有一个训练好的 diffusion 或 score model。它定义了一条 probability flow ODE。现在随机取这条轨迹上的一个点 ,再用 teacher 模型沿 ODE 往前走一步,到达更接近数据侧的点 。然后要求 student consistency model 在这两个点上的输出尽量一致:
这里有三个对象:
teacher diffusion model:提供 ODE 轨迹上的一步更新;student network:当前要训练的 consistency model;target network:通常用 student 的 EMA 参数构造,提供更稳定的目标。

图:MIT 6.S978 CM_lecture.pdf 中的 distillation 训练目标。它并不是直接拟合真实数据,而是在 teacher 给出的轨迹邻近点之间学习自一致性。
这一步的直觉可以表述为:
- teacher 告诉模型“这两个点在同一条 ODE 轨迹上,而且彼此很近”;
- consistency model 学习“既然它们来自同一条轨迹,就应该映射到同一个数据端点”。
因此,Consistency Distillation 不是在学习一个新的 teacher,而是在压缩 teacher 已经隐含定义好的生成轨迹。
5. 直接训练:不先训练 diffusion model 也可以
原始论文进一步说明,Consistency Models 不只是蒸馏工具,它也可以直接作为生成模型训练。
这时不再依赖预训练 diffusion model 去做 ODE 一步更新,而是直接从数据点 、噪声 和两个相邻噪声水平 构造训练目标:
这里的思想仍然没有变:
- 两个输入是同一数据点在两个相邻噪声层级下的扰动版本;
- 它们应当落在“近似相同”的生成轨迹附近;
- 因此模型输出也应当保持一致。

图:MIT 6.S978 CM_lecture.pdf 中对 direct consistency training 的概括。这里最重要的结论是:不必先预训练一个 diffusion model。
这一点让 Consistency Models 从“蒸馏方法”变成了“独立的生成模型家族”。可以把它概括为:
- 它天然支持一步生成;
- 它也允许多步采样,在速度和质量之间折中;
- 它既是一种 diffusion distillation 技术,也是一类新的生成模型。

图:MIT 6.S978 CM_lecture.pdf 末尾的总结。对初学者而言,这三点已经足够把它和单纯的“采样加速技巧”区分开来。
6. 连续时间版本说明了它和 Flow Matching 的联系
这一讲后半段继续往前推,讨论 continuous-time consistency training。这个版本的目标是减少离散时间网格带来的偏差,把 consistency 约束直接写到连续时间里。

图:MIT 6.S978 CM_lecture.pdf 中对连续时间目标的说明。这里的重点不是记住公式,而是看到训练目标已经从“离散相邻层级的一致性”走向“整条连续轨迹上的一致性”。
这也是它与 Flow Matching 逐渐靠近的地方。两者都在连续时间里讨论分布演化,只是关注对象不同:
- Flow Matching 学的是使分布流动起来的速度场;
- Consistency Model 学的是沿同一轨迹回到数据端点的映射。
还可以写成一个统一表达,说明 diffusion、PF-ODE 与 consistency model 之间可以放在同一个连续时间框架里理解。

图:MIT 6.S978 CM_lecture.pdf 后半段的统一公式。它提示了一个重要事实:Consistency Model 并不是与 diffusion 完全割裂的新对象,而是连续时间生成建模中的另一种参数化方式。
7. 代码中,Consistency Model 的关键思想体现在哪里
下面几段代码对应了四个关键结构。
7.1 噪声层级不是均匀划分,而是用 Karras 风格边界
def kerras_boundaries(sigma, eps, N, T):
return torch.tensor(
[
(eps ** (1 / sigma) + i / (N - 1) * (T ** (1 / sigma) - eps ** (1 / sigma)))
** sigma
for i in range(N)
]
)这段代码定义了一组离散噪声边界。训练时并不是在任意两个时间点之间随便比较,而是在这些噪声层级上采样相邻的 。
这对应的是“从有限个噪声层级出发,逐步逼近连续时间 consistency”的思路。
7.2 网络输出不是裸输出,而是满足边界条件的参数化
return c_skip_t[:, :, None, None] * x_ori + c_out_t[:, :, None, None] * x即使不展开 c_skip_t 和 c_out_t 的具体表达,这个返回式已经把 Consistency Model 最关键的结构写出来了。
它的作用正是:
- 保留输入的 skip 分支;
- 让网络只负责学习剩余修正项;
- 在
t = 0时自动退化为恒等映射。
这正对应上面的参数化:
是一一对应的。
7.3 训练里出现了一个 EMA target network
ema_model = ConsistencyModel(n_channels, n_feat=n_feat)
ema_model.to(device)
ema_model.load_state_dict(model.state_dict())
...
with torch.no_grad():
mu = math.exp(2 * math.log(0.95) / N)
for p, ema_p in zip(model.parameters(), ema_model.parameters()):
ema_p.mul_(mu).add_(p, alpha=1 - mu)这段代码对应 target network 的实现。当前模型参数不断更新,而 ema_model 用指数滑动平均的方式缓慢跟随,从而提供更稳定的一致性目标。
这也是 Consistency Models 和 BYOL、Mean Teacher 一类方法在训练结构上有相似之处的原因:目标网络通常不直接参与梯度更新,而是以更平滑的方式演化。
7.4 采样接口天然支持少步生成
xh = model.sample(
torch.randn_like(x).to(device=device) * 80.0,
list(reversed([5.0, 10.0, 20.0, 40.0, 80.0])),
)这里的接口已经显示出 Consistency Model 的使用方式和 DDPM 不同。它不是固定地走一个很长的离散去噪链,而是给定少量噪声层级,直接做一步或少步映射。
这也对应一个直接结论:
- 一步生成是它的原生能力;
- 多步生成只是为了在计算量和样本质量之间再做折中。
8. 应当怎样理解 Consistency Models
如果只看表面,Consistency Models 很容易被理解成“Diffusion 的快速采样补丁”。这个理解不完全错,但还不够。
更准确的说法是:
- 它继承了 diffusion 连续时间建模的背景,尤其是 probability flow ODE 的视角;
- 它把“逐步求逆”改写成“整条轨迹上的统一映射”;
- 它把生成问题重新表述成边界条件加自一致约束;
- 因而既可以做 diffusion distillation,也可以作为独立生成模型训练。
从第一性原理看,它回答的是这样一个问题:
如果一条生成轨迹上的所有点最终都对应同一个数据端点,那么模型是否可以直接学习这个“回到端点”的映射,而不必逐步模拟整条逆过程?
Consistency Models 给出的答案是可以,而且这条路线把生成建模、蒸馏和快速采样连接到了同一套语言里。
参考资料
- MIT 6.S978 Deep Generative Models,
CM_lecture.pdf - Yang Song, Prafulla Dhariwal, Mark Chen, Ilya Sutskever, Consistency Models, ICML 2023
- Yang Song, Prafulla Dhariwal, Improved Techniques for Training Consistency Models, 2023