从 Transformer 到 Decision Transformer:VLA 前置知识一文梳理
VLA 是 Vision-Language-Action 的缩写。这类模型同时处理三类信息:
- 视觉输入
- 语言指令
- 机器人动作
因此,真正进入 VLA 主线之前,先建立一套稳固的前置知识,通常会省掉很多不必要的困惑。
这篇文章沿着一条最实用的路径展开:
Transformer:理解序列建模ViT:理解图像如何进入 TransformerCLIP:理解图像和文本如何对齐BLIP-2:理解视觉信息如何接入大语言模型Decision Transformer:理解动作如何被写成条件序列预测
一条最实用的前置路径
进入 VLA 之前,最重要的不是把所有背景都学完,而是先搭出一条知识主线。
这条主线依次回答三个问题:
- 序列怎么建模?
- 图像和语言怎么放进同一系统?
- 动作怎么也进入统一框架?
按这个顺序理解,很多后面的设计都会自然很多。
Transformer:VLA 的总地基
Attention Is All You Need 的历史意义,在于它提出了一个非常强的前提:
最常见的 attention 公式是:
第一次看这个式子时,最容易被符号吓住。更实用的理解方式是:
- (Q):当前需要找什么信息
- (K):每个位置各自提供什么线索
- (V):一旦被选中,真正传回什么内容
这意味着 attention 本质上是一次“带权检索”。
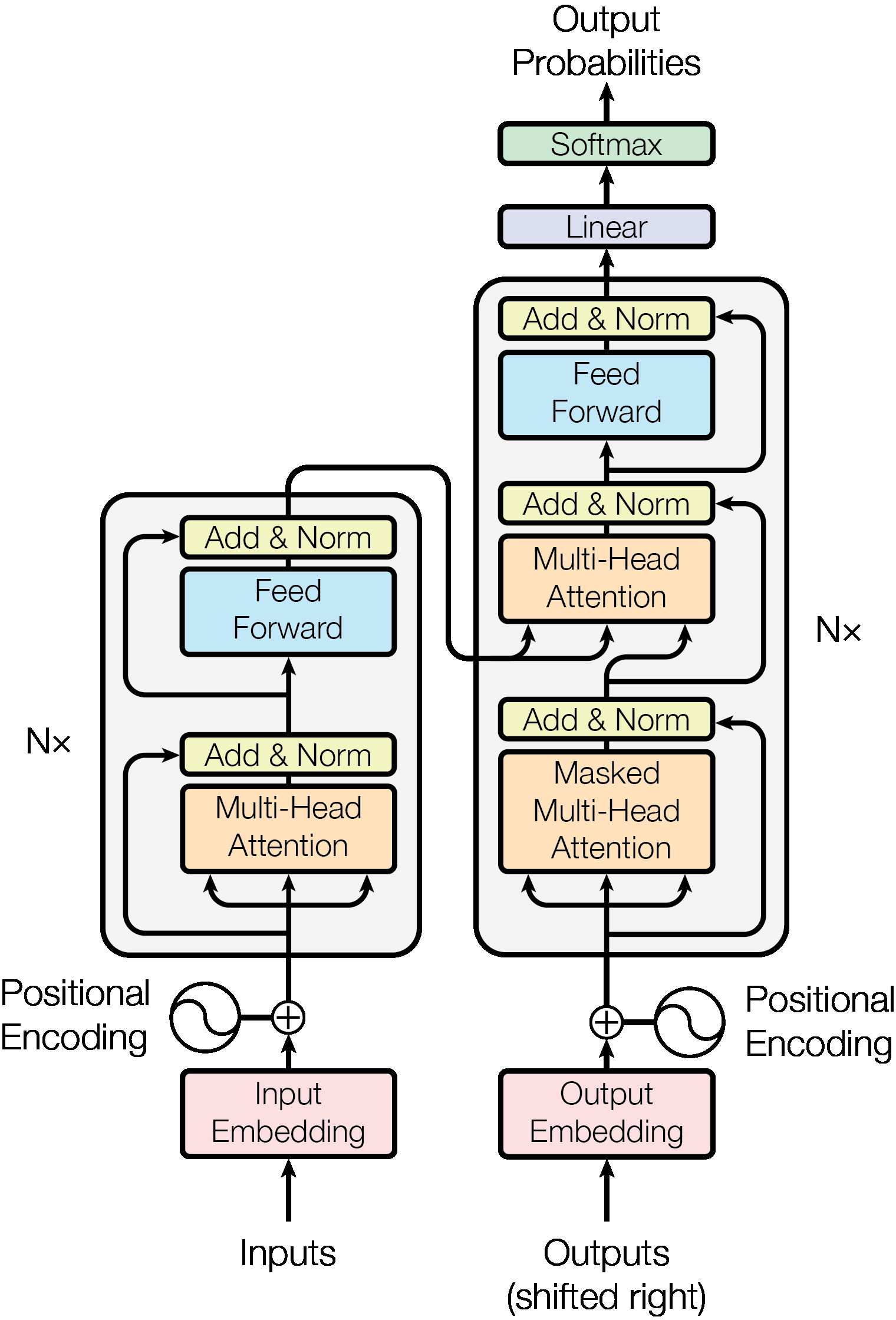
图:原始 Transformer 的 encoder-decoder 结构。后面的很多模型,即使任务完全不同,也仍然在复用这套“序列输入 + 注意力交互 + 条件生成”的骨架。
为什么它重要
只要一种输入能被表示成序列,理论上就能进入 Transformer 框架。
这句话是后面很多事情的前提:
- 文本能被 token 化
- 图像能被 patch 化
- 动作也能被 chunk 化或 token 化
对 VLA 而言,这个统一视角非常重要。
ViT:图像如何变成 Transformer 能处理的对象
ViT 的核心贡献不是“图像分类效果更高”,而是它证明了:
设图像为:
把图像切成大小为 (P \times P) 的 patch 后,patch 数量为:
每个 patch 被拉平,再经过线性映射,得到 patch embedding。于是图像进入 Transformer 之前,先完成了这样一次变换:
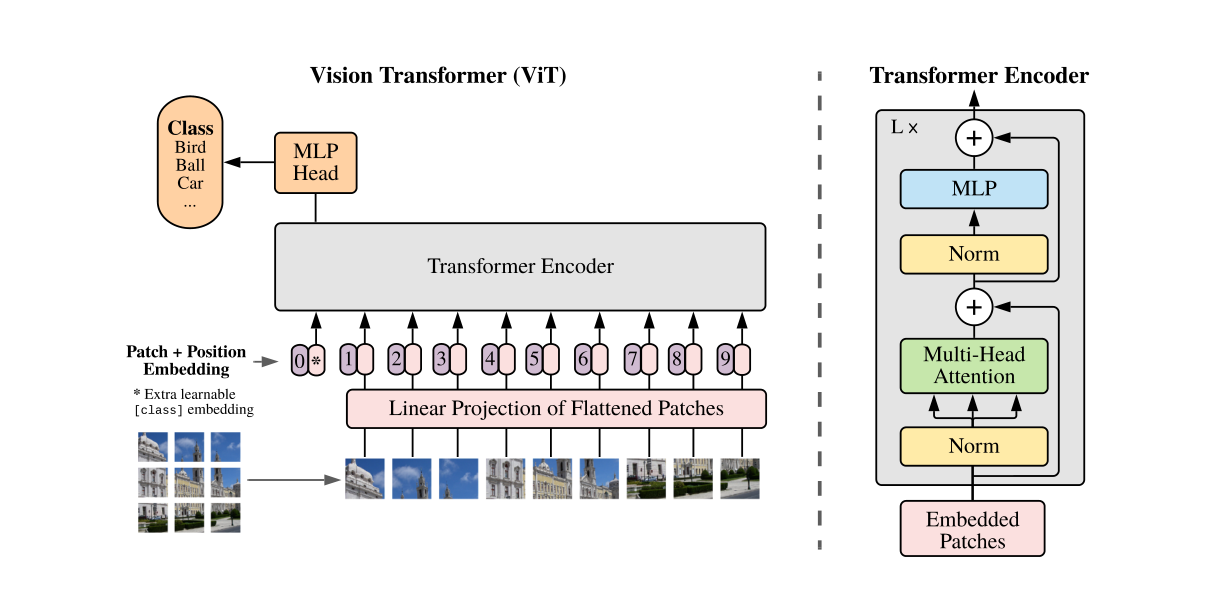
图:ViT 的核心非常直接。图像先切成 patch,再经过线性投影和位置编码,最后作为一串 token 输入 Transformer encoder。
一个容易混淆的点:embedding 和 projection
很多论文里,embedding 和 projection 看起来像在说同一件事。
比较顺手的区分方法是:
因此:
linear projection of patches描述的是操作patch embedding描述的是结果
这两个词经常会同时出现,并不矛盾。
对 VLA 的意义
ViT 之后,视觉输入不再只是 CNN 的专属领域,而是能被自然地转写成:
这为后面的 CLIP、BLIP-2 和 VLA 都打下了接口基础。
CLIP:图像和语言为什么能放进一个语义空间
CLIP 的核心不是“图文检索”,而是:
设图像编码器输出:
文本编码器输出:
训练目标是让匹配的图文对更接近,不匹配的图文对更远离。
最直白的理解就是:
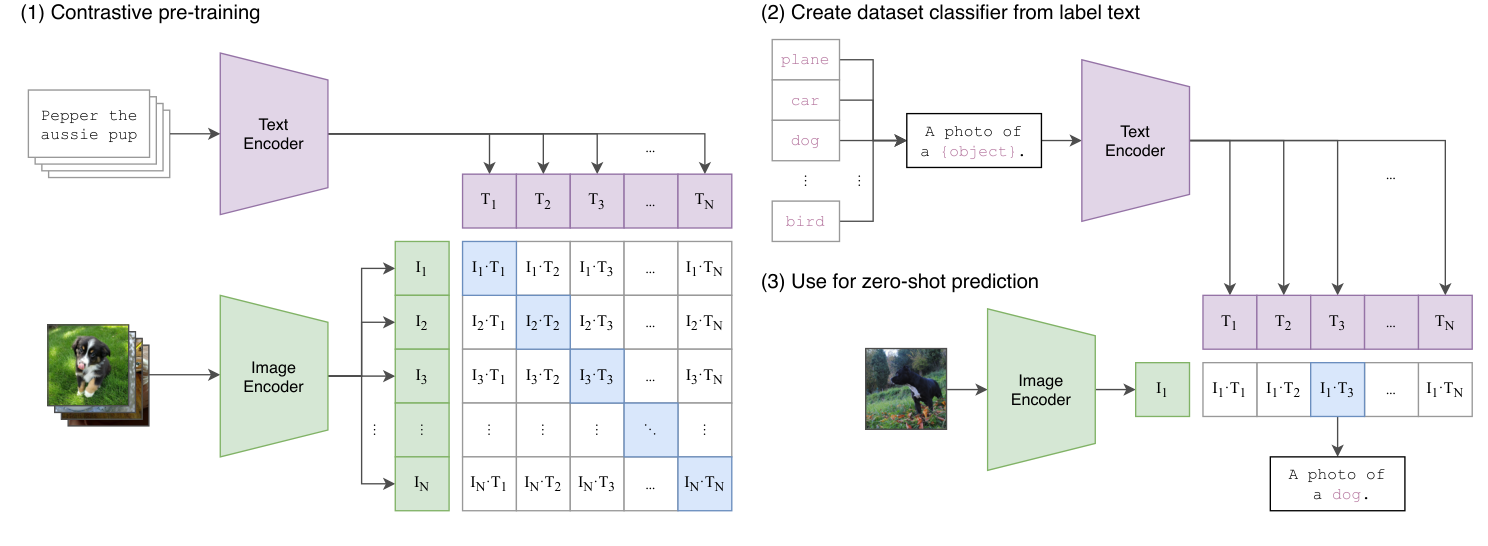
图:CLIP 的三步非常经典。先做图文对比预训练,再把类别写成文本模板,最后通过图像和类别文本的相似度实现 zero-shot 分类。
一个常见误解:CLIP 会“回答问题”吗
不会。
CLIP 不是生成模型。它的主要能力是:
- 把图像编码成向量
- 把文本编码成向量
- 比较两者相似度
因此,更准确的定位是:
如果输入一句:
this is a dogCLIP 不会像聊天模型那样返回一段回答。它只会把这句话编码成文本向量,用于后续匹配。
zero-shot classification 到底是什么意思
这是 CLIP 最经典的能力之一。
传统图像分类通常需要:
- 为当前任务准备标注数据
- 针对目标类别训练一个分类头
CLIP 则可以把类别名称写成文本提示,例如:
a photo of a dog
a photo of a cat再把图像向量与这些文本向量做相似度比较。
这时 zero-shot 的真正含义是:
这不等于“完全没有监督”。CLIP 的预训练本身依赖海量图文对。
对 VLA 的意义
CLIP 给后续 VLA 带来的不是动作能力,而是:
- 开放词汇视觉理解
- 图文语义对齐
- 从 web-scale 数据中获得视觉语言知识
换句话说,它先解决了“如何用语言描述和检索视觉概念”。
BLIP-2:视觉信息如何真正接入 LLM
如果说 CLIP 已经完成了对齐,那么接下来的问题就是:
BLIP-2 的答案非常经典:
这个桥接器就是 Q-Former。
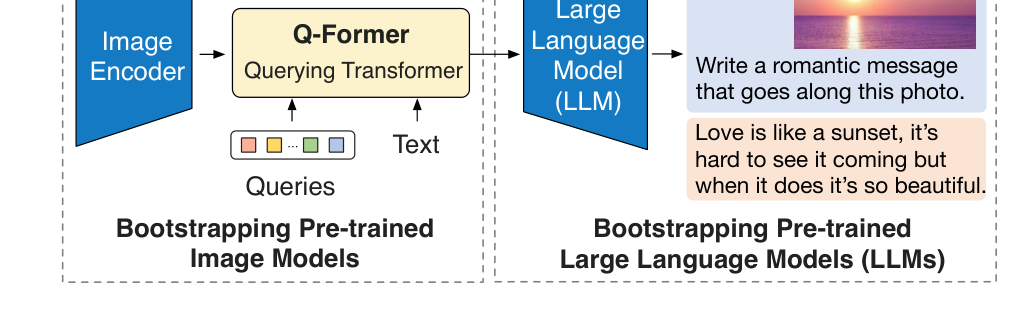
图:BLIP-2 的整体思路。左边是冻结的图像编码器,右边是冻结的大语言模型,中间的 Q-Former 负责完成视觉到语言的桥接。
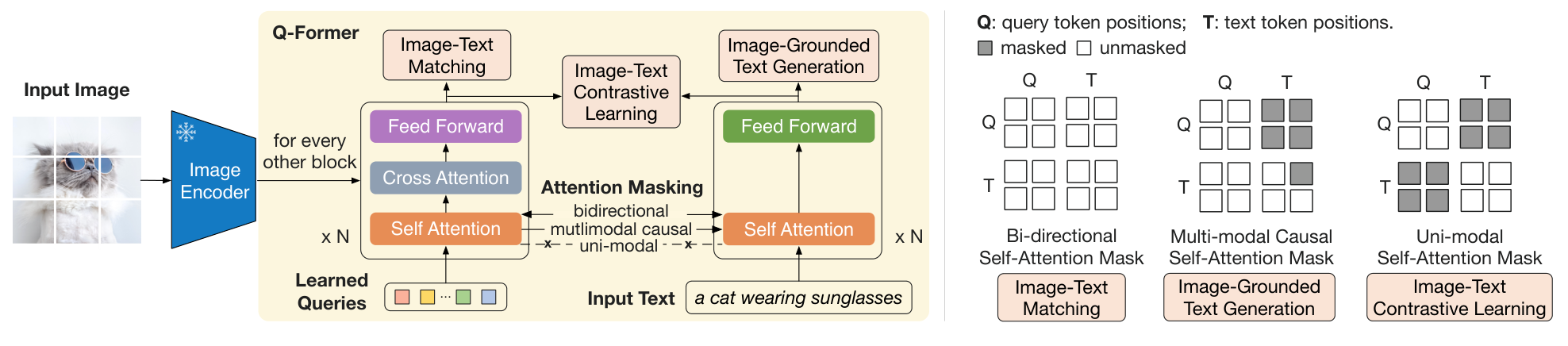
图:Q-Former 是这篇论文的关键。它通过一组 learnable queries,从冻结视觉特征中提取出最值得传给语言模型的信息。
Q-Former 里最容易混淆的两个 Q
BLIP-2 同时出现了两种 “Q”。
第一种是 learned query embeddings,也就是一组可学习输入 token:
第二种是 attention 里的 query matrix:
两者不是一回事。
一个更清楚的理解方式是:
- query token:谁在提问
- attention 里的 (Q):这一层里它怎样提问
self-attention 和 cross-attention 的区别
如果:
那么这是:
如果:
那么这是:
在 BLIP-2 里:
- query token 彼此之间交流,是 self-attention
- query token 去读图像特征,是 cross-attention

图:同一个 Q-Former,在不同训练目标下会切换不同的 attention mask。mask 的作用不是“加一点遮挡”,而是明确规定哪些 token 可以互相看见。
mask 在这里到底控制什么
BLIP-2 论文里,最值得配图理解的地方之一就是这组 mask。它控制的其实是信息流方向。
ITC:query 和 text 各自编码,彼此不直接通信,目标是做图文对比学习。ITM:query 和 text 可以双向交互,目标是判断图文是否匹配。ITG:text 端采用自回归 mask,只能看见全部 query 和自己左边已经出现的文本,不能偷看未来 token,目标是做生成。
如果只记一句话,可以记成:
对 VLA 的意义
BLIP-2 最有价值的地方,不只是性能,而是说明:
这件事对后面的 VLA 也一样成立。
Decision Transformer:动作也能写成条件序列预测
到这里,视觉和语言这半边已经比较清楚了。
剩下的关键问题是:
Decision Transformer 给出的答案是:
轨迹被写成:
其中:
是 return-to-go。
模型学习的是:
也就是:
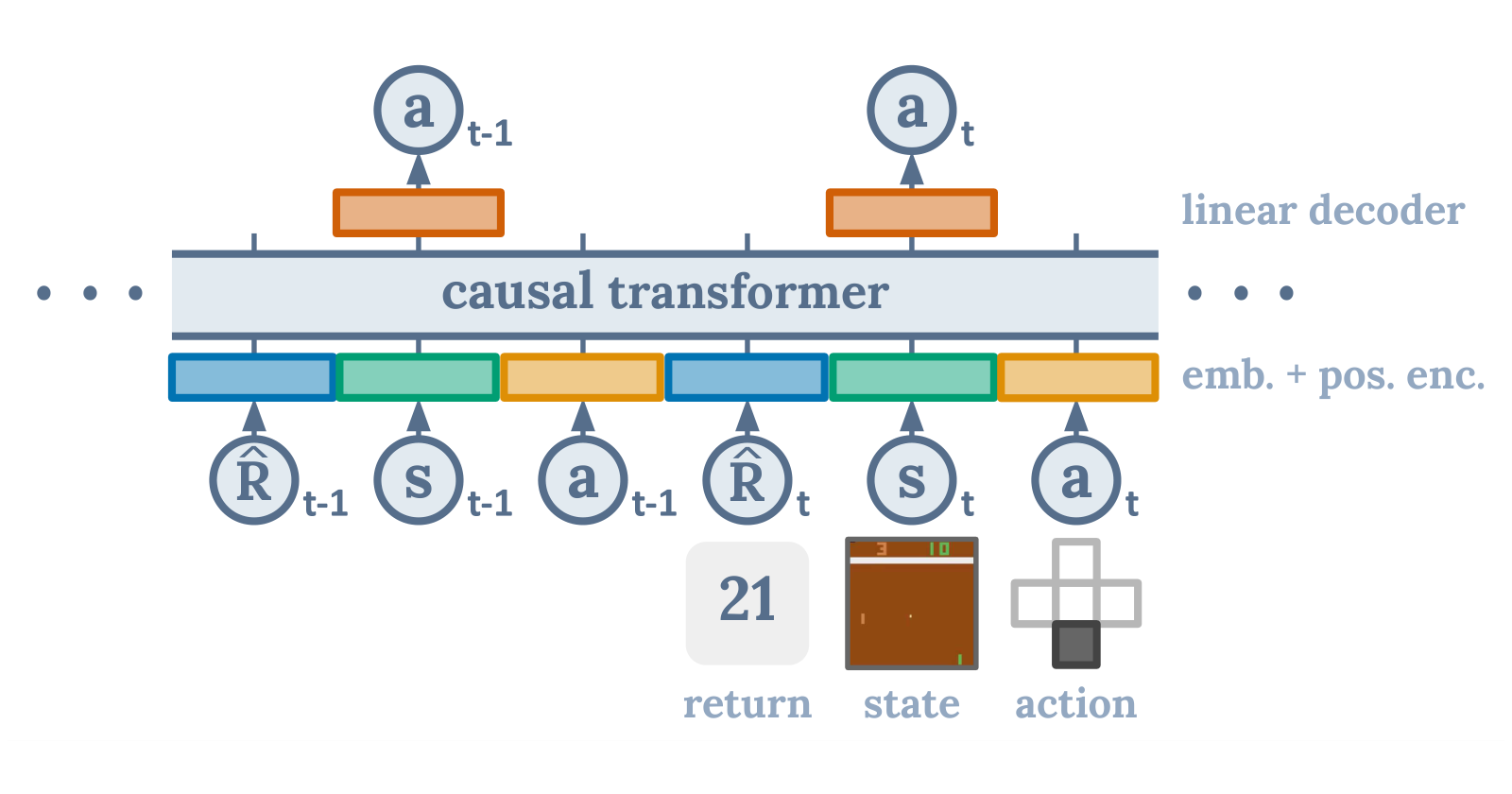
图:Decision Transformer 的输入不再只是状态,而是交替排列的 return-to-go、state 和 action。这一步把决策问题改写成了标准的自回归序列建模问题。
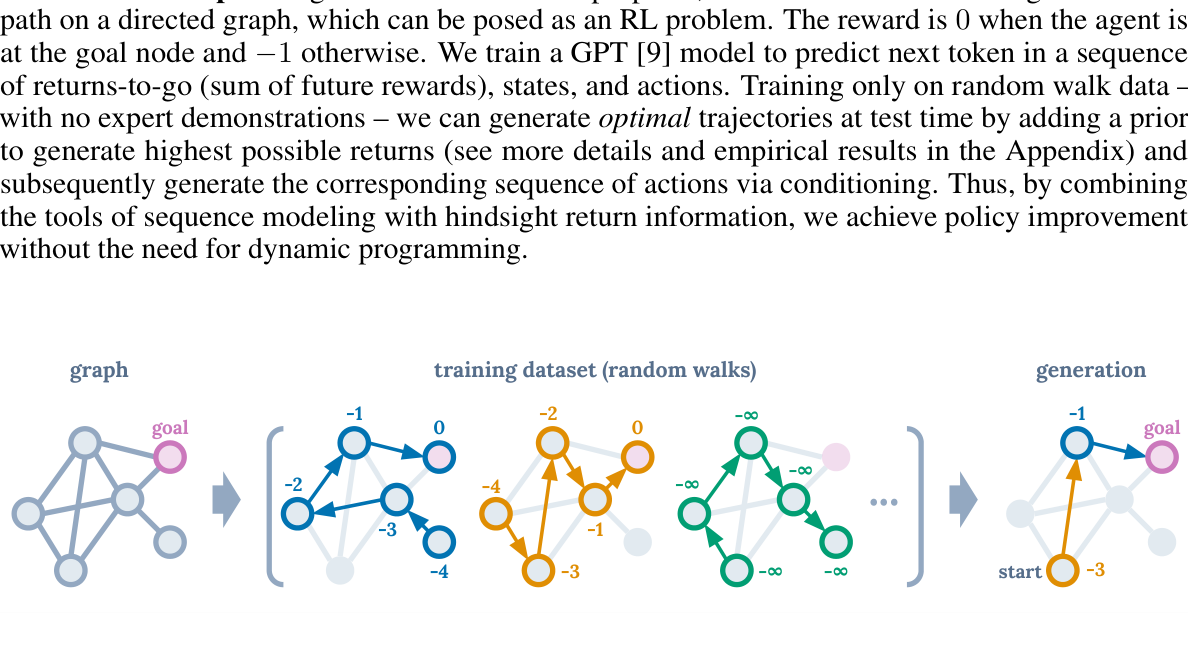
图:return-to-go 是这篇论文最关键的条件信号。它告诉模型“想达到怎样的表现水平”,再结合当前状态和历史动作去预测下一步行为。
它和普通 behavior cloning 的区别
普通 BC 更像是在学:
而 Decision Transformer 多了一个关键条件:
因此它不是简单地模仿平均行为,而是在学:
更准确的定位是:
为什么 long context 很重要
这篇论文特别强调长上下文,因为当前动作往往不只取决于当前状态,还取决于更早的轨迹信息。
因此模型学的是:
而不是只学:
这对 VLA 的意义很直接。后面的很多 VLA 模型其实都在做更一般的事情:
所以 Decision Transformer 最重要的价值,不是某个 benchmark,而是它让“动作也可以像 token 一样被条件化预测”这件事变得自然了。
一些最容易混淆的基础概念
这一部分单独列出来,方便回头查。
token 是什么
token 不是“一个单词”这么简单,更准确地说,它是:
文本里的 token 可能是:
- 一个词
- 一个词的一部分
- 一个汉字
- 一个标点
embedding 是什么
embedding 的最实用定义是:
文本 token、图像 patch、状态、动作、return 都可以有各自的 embedding。
projection 和 embedding 的关系
一个比较顺手的区分方式是:
self-attention 和 cross-attention
- 同一组 token 彼此看彼此:
self-attention - 一组 token 去看另一组 token:
cross-attention
CLIP 为什么不生成文字
因为它的主要任务是图文表示对齐,不是文本生成。
Decision Transformer 为什么不是普通 BC
因为它多了 return-to-go 这个条件,学的是条件行为分布,而不是无条件模仿。
最后的总结
进入 VLA 之前,真正需要先建立的,不是某个零散术语,而是一套连续的理解框架:
Transformer解决序列建模ViT解决图像进入 TransformerCLIP解决图文对齐BLIP-2解决视觉接入 LLMDecision Transformer解决动作条件生成
把这五步串起来,再去读 ACT、Diffusion Policy、RT-1、RT-2、OpenVLA、pi0,理解速度通常会快很多。
下一条最自然的动作线前置,就是 ACT 和 Diffusion Policy。
参考资料
原始论文
- Vaswani, A., et al. “Attention Is All You Need.” NeurIPS 2017. arXiv
- Dosovitskiy, A., et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” ICLR 2021. arXiv
- Radford, A., et al. “Learning Transferable Visual Models From Natural Language Supervision.” ICML 2021. arXiv
- Li, J., et al. “BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models.” ICML 2023. arXiv
- Chen, L., et al. “Decision Transformer: Reinforcement Learning via Sequence Modeling.” NeurIPS 2021. arXiv