前两篇文章分别讨论了 VAE 和自回归模型。它们代表了两种非常不同的生成建模路线:
- VAE 通过潜变量和变分下界间接学习数据分布;
- 自回归模型通过链式法则把联合分布拆成条件分布。
GAN 走的是第三条路线。它不显式写出变分下界,也不把联合分布拆成条件分布,而是换了一个问题:
如果直接写分布之间的距离很困难,能否训练一个网络来判断“生成分布和真实分布是否不同”?
这一讲在 MIT 6.S978 里的安排也正是如此:先解释为什么传统的 reconstruction loss 假设过强,再引出对抗目标,然后给出 GAN 的理论结论,最后说明为什么 GAN 难训练,以及 WGAN 为什么出现。
1. GAN 的动机:为什么不再使用 reconstruction loss
在 VAE 中,训练目标里通常有 reconstruction term,例如像素空间上的高斯或伯努利似然。这样的目标有一个隐含假设:观测空间中的元素服从相对简单的分布,或者说误差可以用像素级的独立分布来刻画。
这类假设对于高维图像往往过强。图像的语义结构非常复杂,用像素级 L2/L1 或独立伯努利来衡量“像不像真实图像”,往往并不充分。
于是问题被改写成:
- 不是先手工指定一个分布差异;
- 而是直接训练一个网络去表示这种差异。
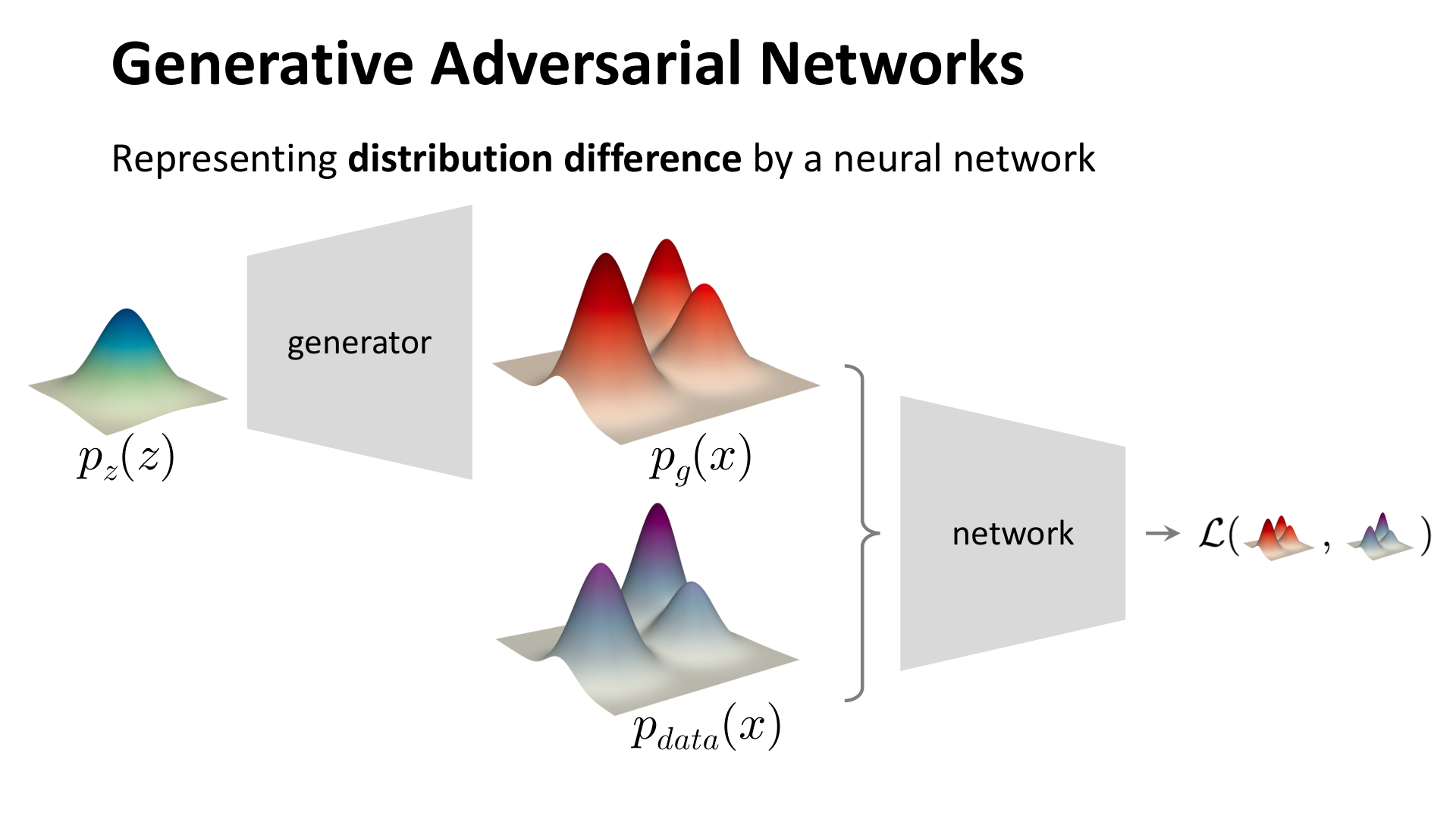
图:MIT 6.S978 lec4_gan.pdf 中对 GAN 动机的示意。生成器 把先验噪声映射到生成分布 ,另一个网络则尝试学习 与 之间的差异。
这一步其实是 GAN 最核心的转变:它不再先规定“什么样的误差才算像”,而是让判别器自己学习什么样的样本更像真实数据。
2. 对抗目标:一个最小最大问题
GAN 由两个网络组成:
- 生成器 :把噪声 映射成样本 ;
- 判别器 :输入一个样本 ,输出它来自真实分布的概率。
原始 GAN 的目标函数是:
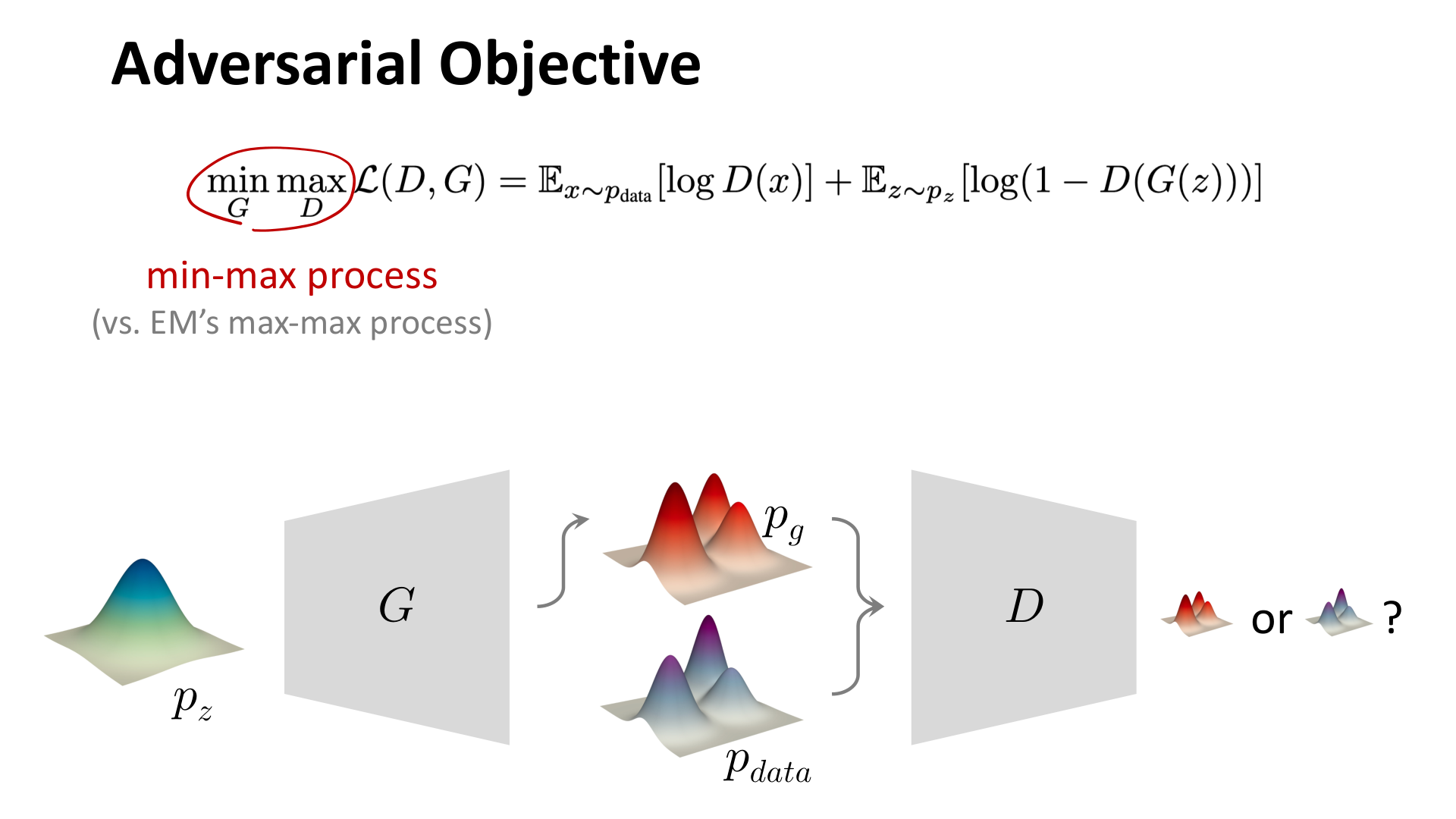
图:MIT 6.S978 lec4_gan.pdf 中对原始 GAN 目标的示意。和 EM 一类方法的 max-max 不同,GAN 是一个 min-max 过程。
这个目标可以拆成两个交替进行的步骤。
2.1 D-step:固定生成器,优化判别器
在判别器更新阶段,生成器被冻结,判别器希望做到:
- 对真实样本输出接近 1;
- 对生成样本输出接近 0。
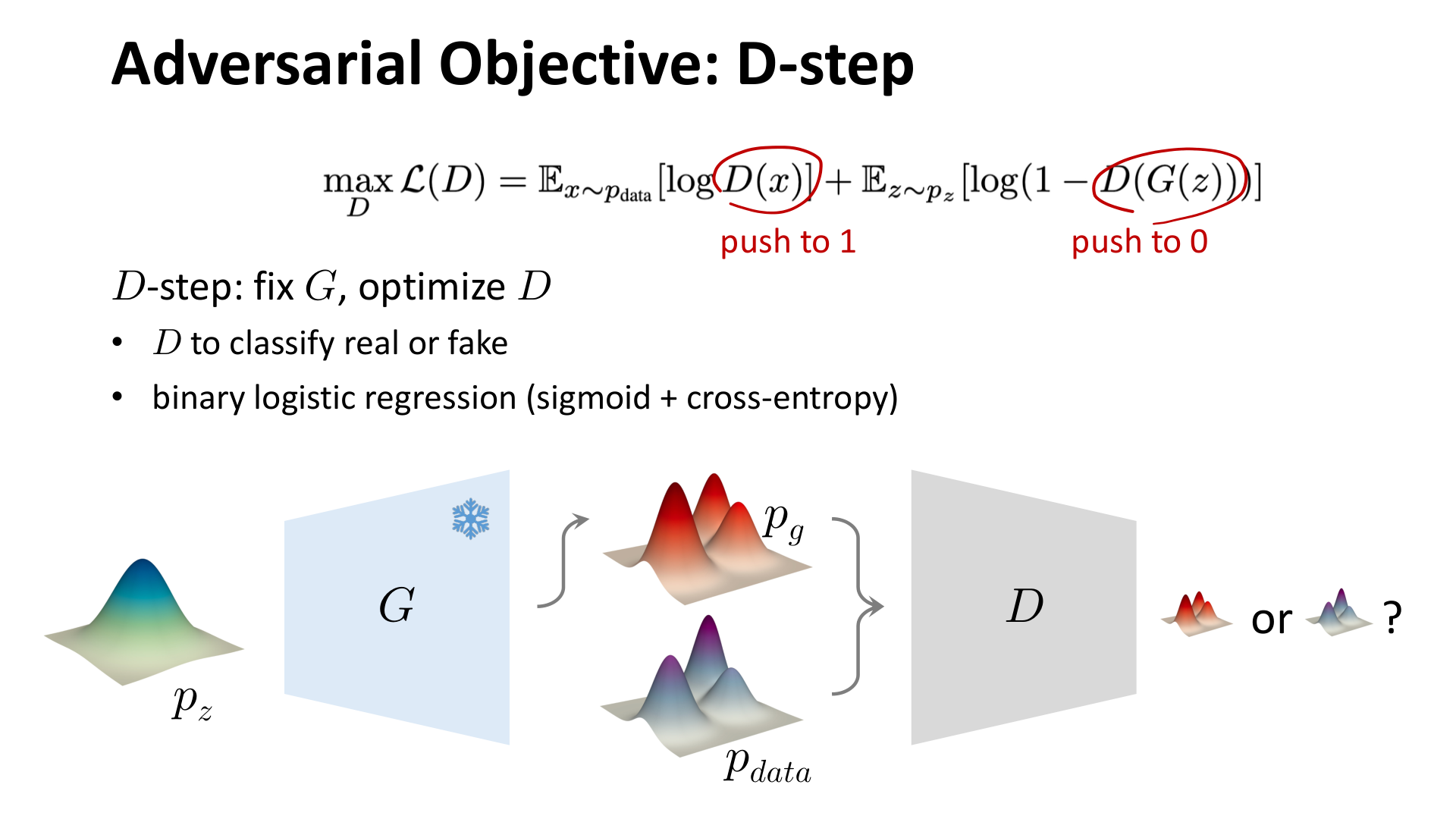
图:MIT 6.S978 lec4_gan.pdf 中对 D-step 的示意。判别器本质上在做一个二分类问题,目标是区分真实样本和生成样本。
2.2 G-step:固定判别器,优化生成器
在生成器更新阶段,判别器被冻结,生成器希望把自己的样本推到判别器会认为“真实”的区域。
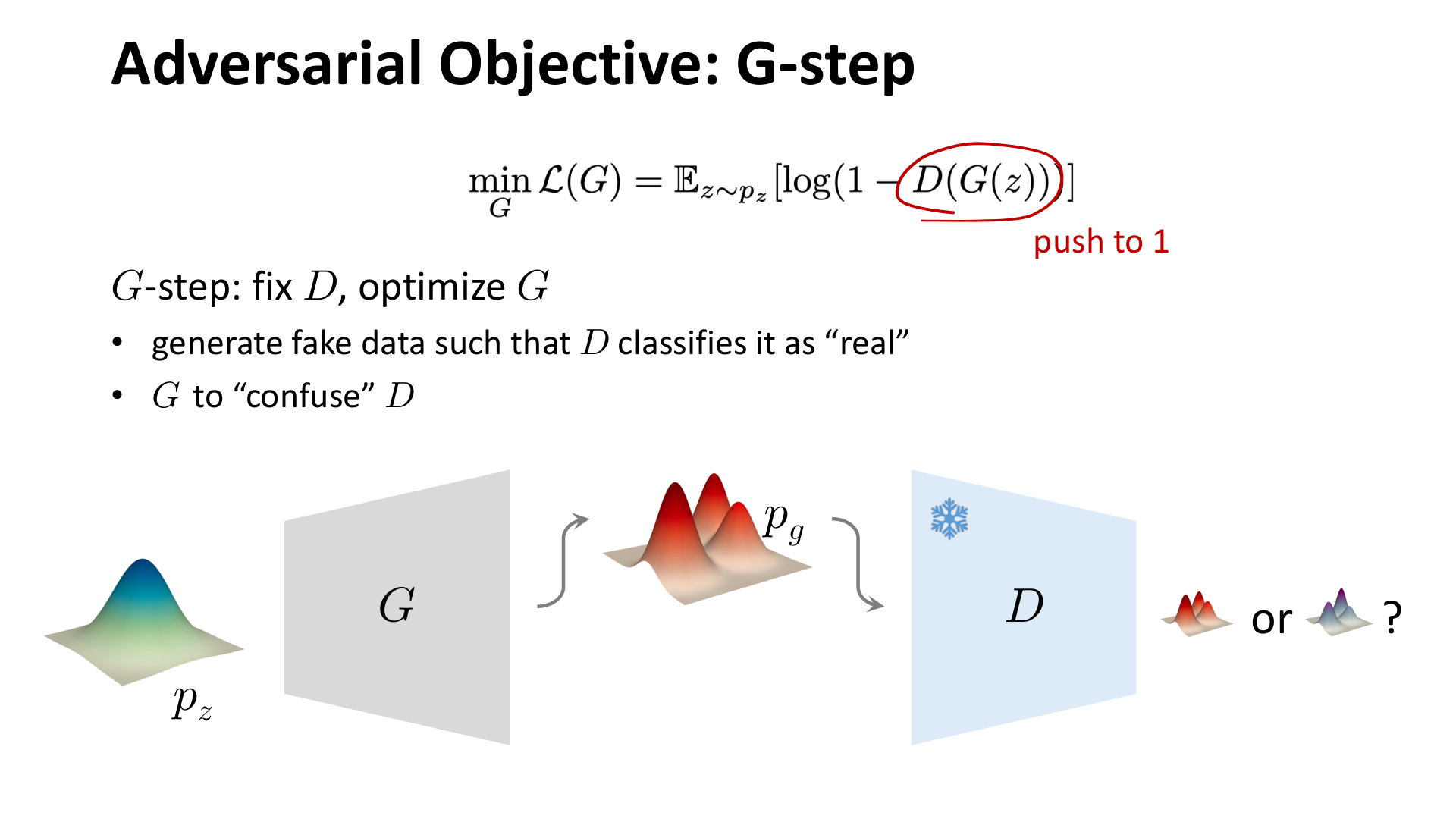
图:MIT 6.S978 lec4_gan.pdf 中对 G-step 的示意。生成器并不直接接触真实分布,而是通过判别器给出的梯度方向进行更新。
从这个角度看,GAN 的训练不是在最小化一个固定的损失函数,而是在交替优化两个相互依赖的目标。因此,GAN 的核心既是生成建模,也是博弈优化。
3. 为什么生成器目标通常使用“翻转”写法
如果严格按照原始 minimax 形式更新生成器,那么生成器优化的是:
但这种写法在训练早期常常会产生弱梯度。原因是:
- 训练初期生成器很差;
- 判别器很容易把假样本判成接近 0;
- 于是 对生成器的有效梯度可能过小。
因此,工程上更常见的做法是让生成器最大化:
也就是把“假样本应判成真样本”直接作为优化目标。这通常被称为 non-saturating loss,也常被称为“flip trick”。
这一步非常重要,因为它说明:
- GAN 的核心思想来自 minimax 博弈;
- 但真正稳定的训练常常依赖于对目标形式做工程修正。
4. GAN 的三个理论结果
原始 GAN 论文给出了三个经典结论,这三点也是理解 GAN 理论结构的主线。
4.1 对任意固定的生成器,存在最优判别器
当 固定时,最优判别器是:
这意味着最优判别器在每个点上都在比较“真实密度”和“生成密度”的相对大小。
4.2 带入最优判别器后,GAN 实际上在优化 JS 散度
把 带回目标函数,可以得到:

图:MIT 6.S978 lec4_gan.pdf 中对理论结果的总结。原始 GAN 在理想条件下对应 Jensen-Shannon divergence。
4.3 全局最优时,生成分布等于真实分布
如果优化能够达到全局最优,那么有:
从理论上看,这是一个很漂亮的结论:只要判别器足够强、生成器足够强、优化也足够理想,GAN 的确是在逼近真实分布。
问题在于,这些条件在实际训练里往往并不满足。
5. 为什么 GAN 难训练
GAN 的训练困难主要体现在三类问题:
- 难以达到平衡;
- 梯度可能消失;
- 容易出现 mode collapse。
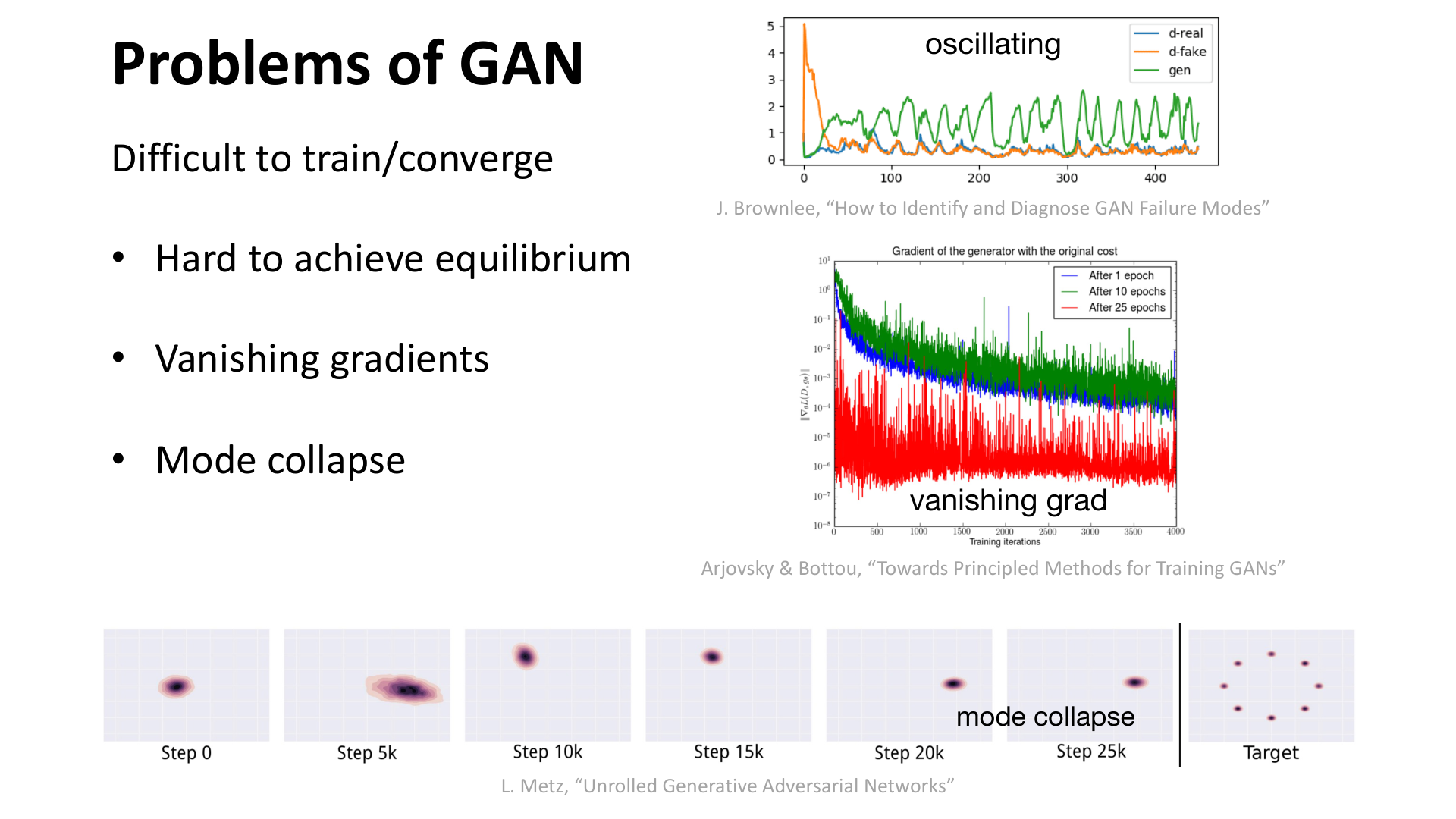
图:MIT 6.S978 lec4_gan.pdf 中总结的 GAN 典型问题,包括 oscillation、vanishing gradients 和 mode collapse。
这些问题的根源主要有两个。
5.1 它是一个博弈,而不是单一目标优化
在普通监督学习里,模型面对的是一个固定损失函数。但 GAN 不同:生成器看到的损失,是由一个同时在变化的判别器产生的。因此优化地形始终在变,训练轨迹很容易震荡。
5.2 JS 散度在分布不重叠时可能给不出有效梯度
一个关键问题是:当 和 的支撑几乎不重叠时,JS 散度会接近常数,无法给生成器提供足够有用的梯度信息。
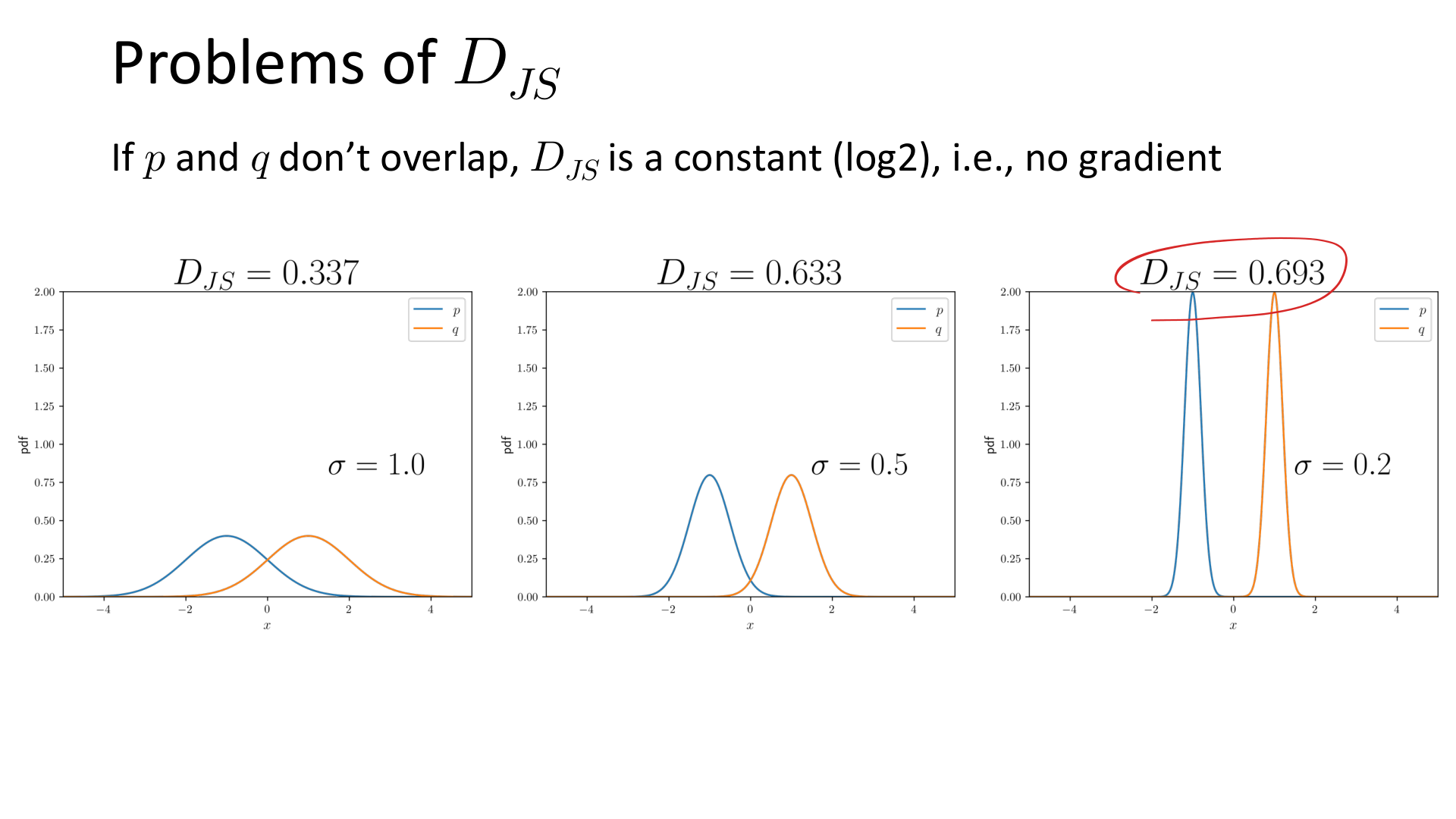
图:MIT 6.S978 lec4_gan.pdf 中对 JS 散度问题的示意。当两个分布几乎不重叠时, 接近常数,梯度会变得不理想。
这就自然引出了 WGAN。
6. 从 GAN 到 WGAN:为什么要换距离
WGAN 的出发点非常直接:如果 JS 散度在分布相距较远时表现不好,那么可以考虑换一个更适合优化的分布距离。
WGAN 选择的是 Wasserstein distance,也叫 Earth Mover’s Distance。它衡量的不是“两个分布在信息论意义下有多不同”,而是“把一个分布搬运成另一个分布要付出多少代价”。

图:MIT 6.S978 lec4_gan.pdf 中对 WGAN 的概括。数学上它对应 Wasserstein distance;工程上则体现为去掉对数、引入 Lipschitz 约束。
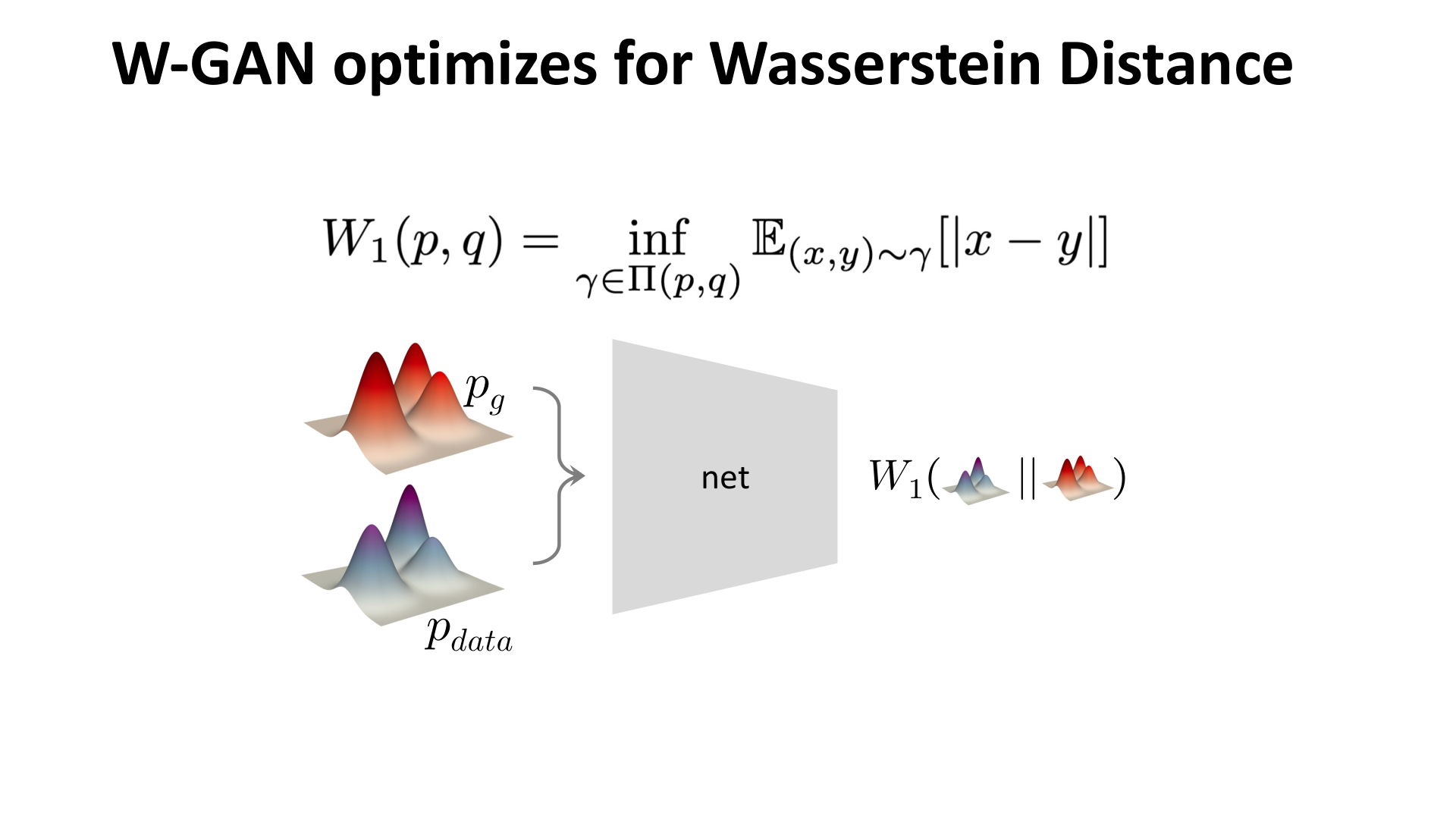
图:MIT 6.S978 lec4_gan.pdf 中对 WGAN 核心目标的示意。和原始 GAN 不同,这里优化的是 Wasserstein distance。
WGAN 的核心思想可以概括为:
- 不再让判别器做真假分类;
- 而是让它输出一个能够反映“样本质量或价值”的分数;
- 生成器沿着这个更平滑的距离信号去改进样本。
当然,WGAN 也不是终点。原始的权重裁剪后来又进一步发展为 gradient penalty 等更稳定的约束方式。但在课程顺序里,WGAN 的作用很清楚:它解释了为什么 GAN 的困难与分布距离的选择直接相关。
7. 代码中,GAN 的关键思想体现在哪里
下面几段代码覆盖了原始 GAN 和 conditional GAN 的关键训练环节。
7.1 判别器的训练就是一个二分类问题
criterion = nn.BCELoss()
def train_discriminator(discriminator, d_optimizer, images, real_labels, fake_images, fake_labels, with_condition, cls_labels):
discriminator.zero_grad()
if with_condition:
outputs = discriminator(images, cls_labels)
else:
outputs = discriminator(images)
real_loss = criterion(outputs, real_labels.view(-1, 1))
if with_condition:
outputs = discriminator(fake_images, cls_labels)
else:
outputs = discriminator(fake_images)
fake_loss = criterion(outputs, fake_labels.view(-1, 1))
d_loss = real_loss + fake_loss
d_loss.backward()
d_optimizer.step()
return d_loss, real_loss, fake_loss这段代码直接对应判别器更新:
- 真实样本标签为 1;
- 生成样本标签为 0;
- 用二元交叉熵训练判别器。
从概率建模角度看,判别器在这里并没有直接输出某种“图像距离”,而是在做真假分类。也正是这一点,最终把原始 GAN 和 JS 散度联系了起来。
7.2 生成器更新时使用了“标签翻转”
def train_generator(generator, g_optimizer, discriminator_outputs, real_labels, with_condition):
generator.zero_grad()
g_loss = criterion(discriminator_outputs, real_labels.view(-1, 1))
g_loss.backward()
g_optimizer.step()
return g_loss这段代码非常值得注意。这里生成器并没有把自己的目标写成“让判别器输出 0”,而是直接把 fake sample 的目标标签设成 real_labels。这正对应前面讨论的 non-saturating 写法:
- 从优化定义看,生成器是在“骗过判别器”;
- 从实现上看,就是让判别器对 fake sample 输出接近 1。
这一步正是训练中最常见、也最实用的目标修正之一。
7.3 判别器和生成器分别表示两个不同方向的映射
class Discriminator(nn.Module):
def __init__(self, channels=[512, 256, 128], with_condition=False):
super().__init__()
self.label_emb = nn.Embedding(10, 50) if with_condition else None
in_dim = 784 + 50 if with_condition else 784
layers = []
for out_dim in channels:
layers.append(nn.Linear(in_dim, out_dim))
layers.append(nn.LeakyReLU(0.2))
layers.append(nn.Dropout(0.3))
in_dim = out_dim
layers.append(nn.Linear(in_dim, 1))
layers.append(nn.Sigmoid())
self.model = nn.Sequential(*layers)
class Generator(nn.Module):
def __init__(self, dim_z=100, channels=[128, 256, 512], with_condition=False):
super().__init__()
self.label_emb = nn.Embedding(10, 50) if with_condition else None
in_dim = dim_z + 50 if with_condition else dim_z
layers = []
for out_dim in channels:
layers.append(nn.Linear(in_dim, out_dim))
layers.append(nn.LeakyReLU(0.2))
in_dim = out_dim
layers.append(nn.Linear(in_dim, 784))
layers.append(nn.Tanh())
self.model = nn.Sequential(*layers)这两段网络从结构上都很简单,但它们对应的角色完全不同:
- 生成器实现的是 的映射;
- 判别器实现的是 的真假评分。
GAN 的难点不在网络深浅,而在这两个网络形成了一个相互依赖的优化闭环。
7.4 Conditional GAN:把条件变量加进博弈过程
self.label_emb = nn.Embedding(10, 50) if self.with_condition else None
...
c = self.label_emb(label)
x = torch.cat([x, c], dim=1)conditional GAN 的关键思想并不复杂:把类别信息 一起送进生成器和判别器,于是建模目标就从
变成了
这样生成器不再只是“生成一个看起来像 MNIST 的数字”,而是“生成一个看起来像指定类别的数字”。
这也是对抗学习后来广泛进入 image-to-image translation、文本到图像和多模态生成的重要入口。
8. GAN 更重要的遗产:对抗损失作为通用损失函数
这一讲的后半部分其实非常重要。课程并没有把 GAN 停在“从噪声生成图像”的原始设置,而是进一步强调:
GAN 更深的价值,在于它定义了一种 adversarial loss。

图:MIT 6.S978 lec4_gan.pdf 中对 adversarial loss 的总结。对抗损失不要求输入一定来自随机噪声,也可以和 L1/L2 重建损失组合使用。
这意味着:
- 输入不一定是纯噪声;
- 输出不一定只靠对抗目标训练;
- adversarial loss 可以和 reconstruction loss、perceptual loss 结合。
于是 GAN 很快从一个“生成模型”扩展成了一种“损失设计方法”。
9. 为什么 pix2pix 和 VQ-GAN 仍然值得放在这一讲里
几个典型例子说明,对抗损失最有生命力的地方,往往不在“纯噪声生成”,而在它和其他目标的结合。

图:MIT 6.S978 lec4_gan.pdf 中的 pix2pix 例子。单独使用 L1 会得到更平滑的结果,而加上对抗损失后,输出通常更锐利、更符合真实图像统计。
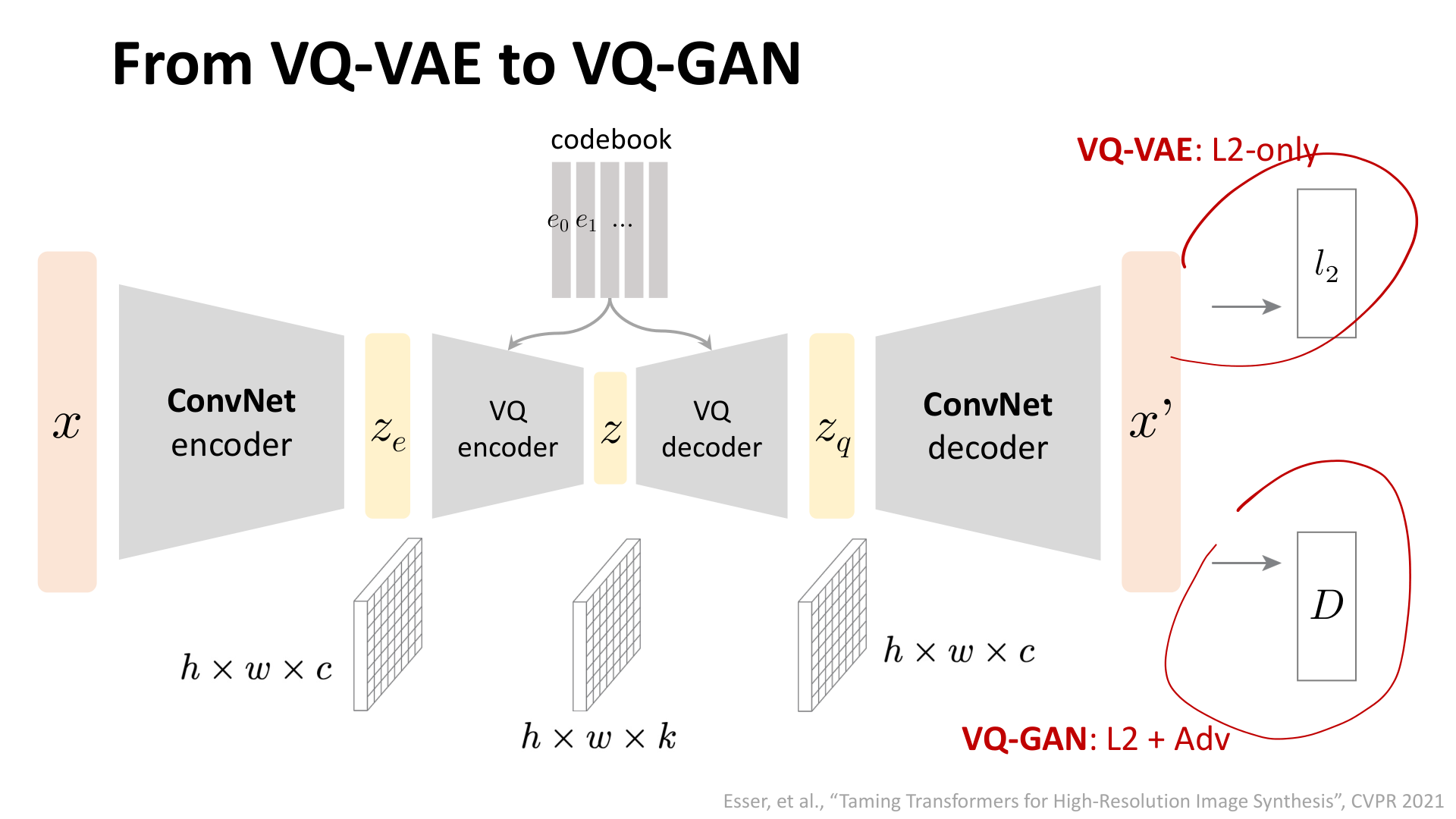
图:MIT 6.S978 lec4_gan.pdf 中对 VQ-GAN 的示意。VQ-GAN 可以被理解为在 VQ-VAE 的基础上加入 adversarial loss,从而改善重建结果的视觉质量。
这两个例子说明了一件很重要的事:
- GAN 本身可能难训练;
- 但 adversarial loss 作为一个组件,常常仍然非常有效。
这也是为什么后来的很多系统虽然不再是“纯 GAN”,却依然会保留对抗损失这一模块。
10. 如何看待 GAN 在今天的位置
如果只看当前最主流的大规模图像生成,GAN 的中心地位已经被 Diffusion 等方法取代。但这并不意味着 GAN 失去价值。相反,它仍然保留了三层重要性。
第一,GAN 清楚地展示了“让网络学习分布差异”这一思想。
第二,GAN 促成了对训练稳定性、分布距离和博弈优化的大量研究。
第三,对抗损失已经成为许多生成系统中的长期组件。
从这个角度看,GAN 的历史作用不只是“曾经生成得很好”,而是它改变了大家设计生成目标函数的方式。
参考资料
- Ian Goodfellow et al., Generative Adversarial Nets
- Martin Arjovsky, Soumith Chintala, Léon Bottou, Wasserstein GAN
- MIT 6.S978 Deep Generative Models, Course Schedule
- MIT 6.S978 Deep Generative Models,
lec4_gan.pdf - Ian Goodfellow, NIPS 2016 Tutorial: Generative Adversarial Networks