如果说 GAN 的核心是让一个判别器学习“什么像真实数据”,那么 Diffusion 模型的核心问题则是:
如果把数据逐步加噪到接近高斯噪声,能否再学会把这个过程一步步反过来?
这类模型之所以重要,不只是因为图像生成效果强,更因为它把多个原本看起来分开的方向连接起来了:
- 分层潜变量模型;
- 去噪学习;
- score matching;
- 连续时间的 SDE/ODE 视角。
理解这类模型可以沿着五步展开:
- 先讲前向加噪;
- 再讲逆过程为什么未知;
- 然后从 KL 推到噪声的 L2 回归;
- 再解释为什么需要 noise-conditional network;
- 最后把它和 score matching 连接起来。
1. Diffusion 模型最直观的图景
Diffusion 模型包含两个过程:
- 前向过程:不断向数据中加入噪声;
- 逆过程:从噪声开始,逐步去掉噪声,恢复出样本。
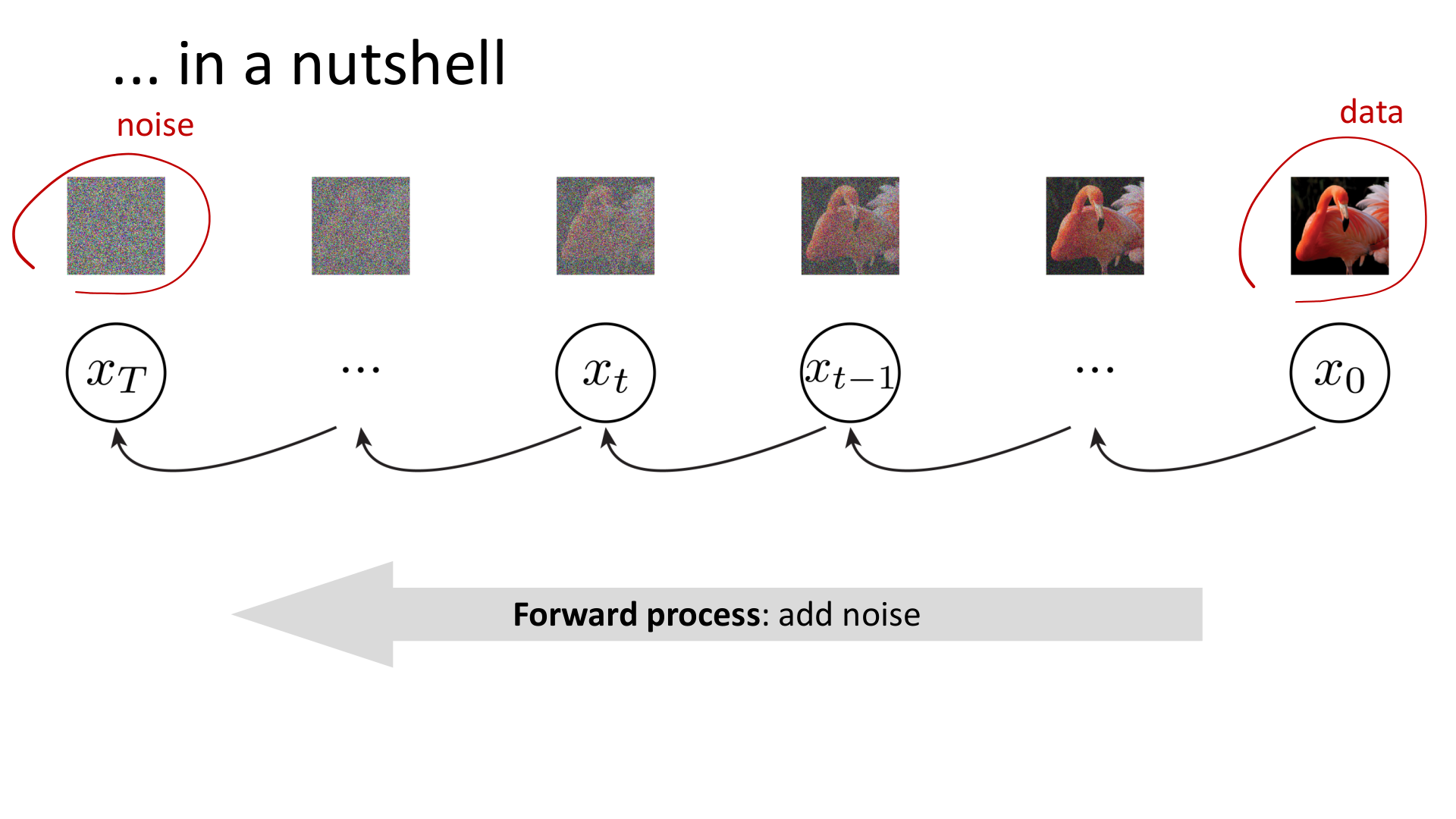
图:MIT 6.S978 lec5_diffusion.pdf 中对扩散模型的整体示意。训练时学习的是逆过程,推断时从纯噪声开始逐步去噪。
这个图景很容易让人产生误解,以为扩散模型只是“反复模糊图片再反过来锐化”。其实更准确的理解是:扩散模型在构造一条从数据分布通向简单噪声分布的概率路径,并学习这条路径的逆向生成机制。
2. 前向过程:为什么加噪是可控的
Diffusion 的前向过程通常定义为一个固定的马尔可夫链:
其中 ,而 是预先设定的 noise schedule。
这一步最关键的地方在于:前向过程不是学习出来的,而是人为设定好的。因此我们知道每一步如何加噪,也知道在足够多步之后,分布会逐渐接近高斯噪声。
更重要的是,前向过程还有一个闭式结果:
其中
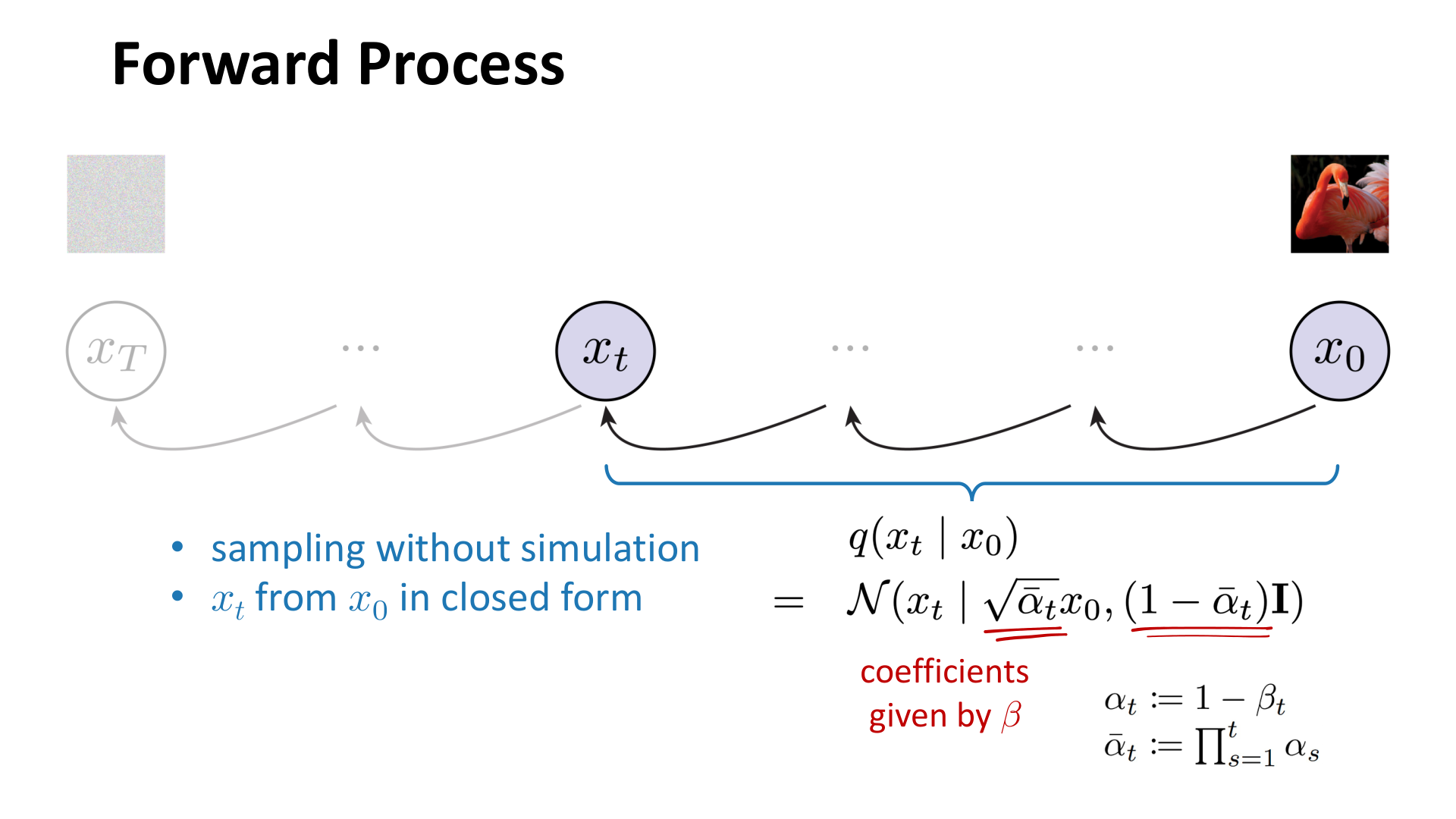
图:MIT 6.S978 lec5_diffusion.pdf 中对前向过程闭式采样的说明。因为高斯分布在仿射变换下保持高斯形式,所以 可以直接由 和噪声一次性构造出来。
这意味着训练时不需要真的一步一步把图像噪声化到第 步,而是可以直接采样:
这也是实现中的关键一步。
3. 逆过程:为什么真正困难的是它
如果前向过程完全已知,那么自然会问:为什么不直接把它反过来?
问题在于,真正想要的逆过程是:
而它一般并不只由前向加噪公式决定。它还依赖真实数据分布本身。

图:MIT 6.S978 lec5_diffusion.pdf 中对这一点的解释。前向条件分布是已知高斯,但逆条件分布取决于数据分布,因此不能直接写出。
因此,扩散模型真正学习的不是前向过程,而是逆过程的参数化近似:
这也是为什么扩散模型仍然属于生成模型:它学习的是一个从噪声逐步回到数据的生成链条。
4. 从 KL 到噪声预测:为什么最后会变成 L2
这一讲最值得反复体会的地方,是它如何把一个看起来复杂的生成模型目标,逐步化简成噪声回归。
这里的逻辑是这样的:
- 把逆过程近似成高斯分布;
- 用 KL 散度度量真实逆条件和参数化逆条件之间的差异;
- 利用高斯 KL 的解析形式,把目标转成均值之间的二次误差;
- 再把这个均值改写成对噪声 的预测。
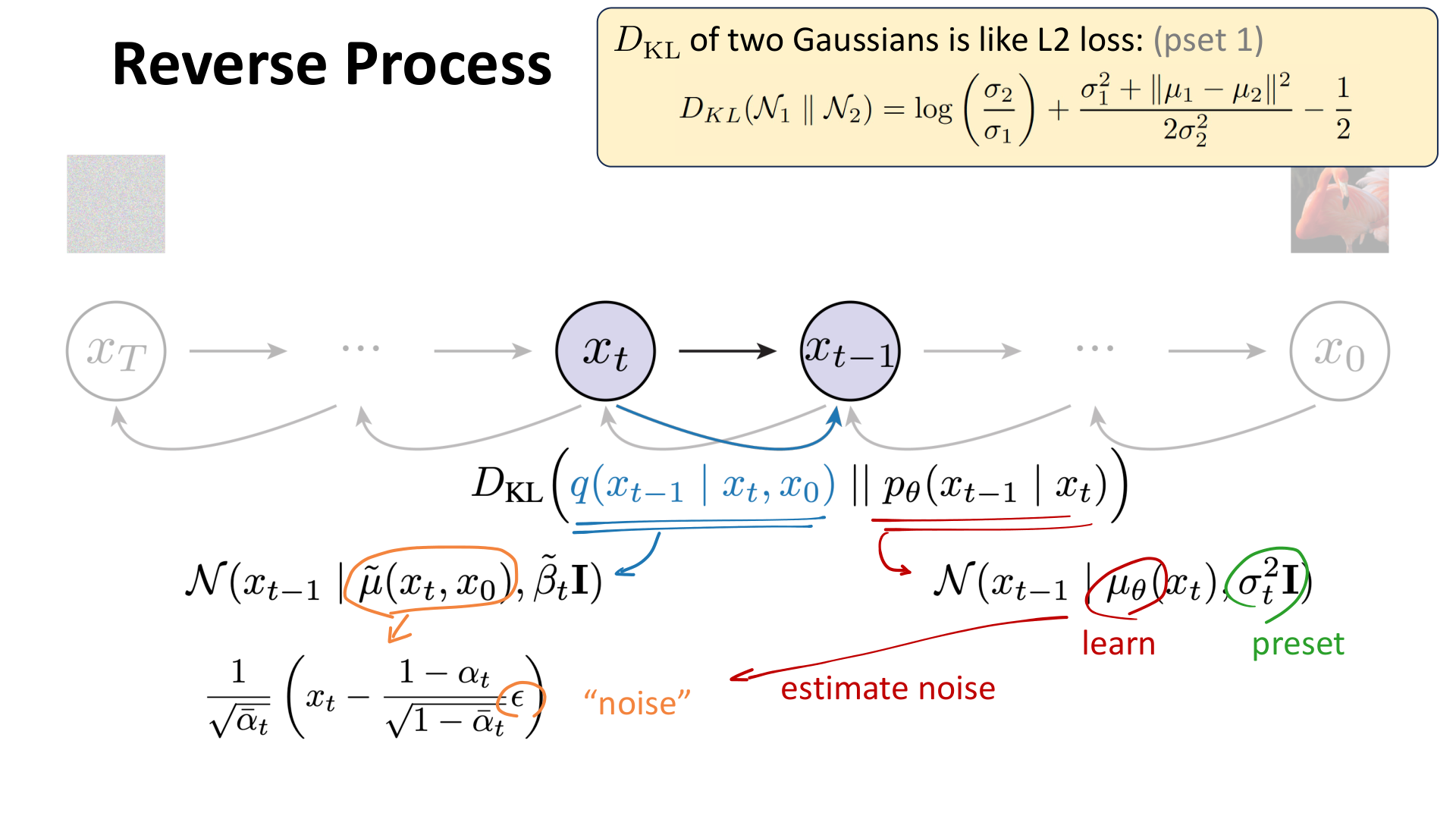
图:MIT 6.S978 lec5_diffusion.pdf 中对这一步的总结。真实逆分布和模型逆分布之间的 KL,在高斯设定下可转为一个关于噪声估计的 L2 目标。
这一点是 DDPM 最核心的简化:最终不必让网络直接预测复杂的分布对象,而只需要预测加到样本上的噪声。
因此,训练目标常常写成:
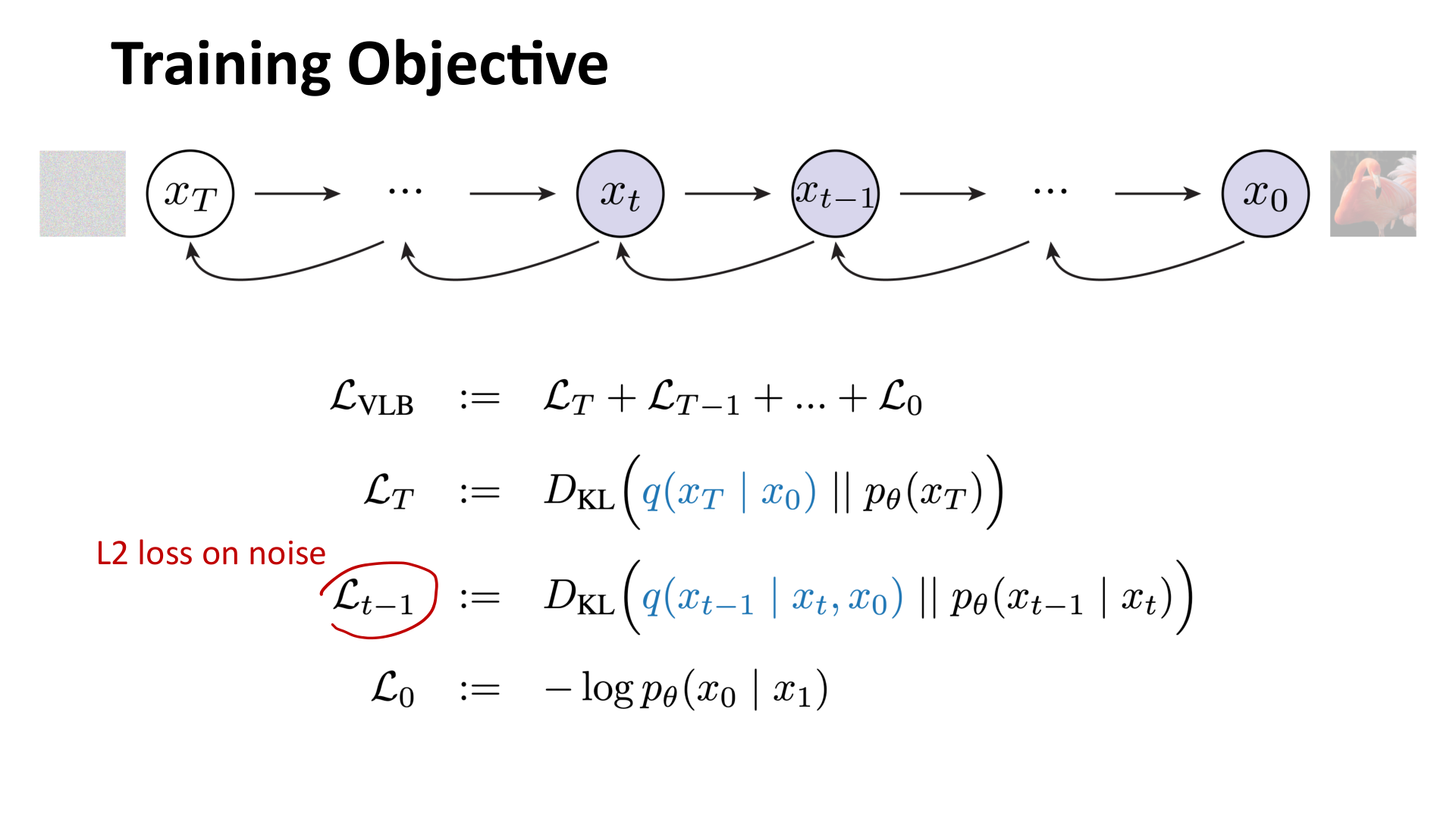
图:MIT 6.S978 lec5_diffusion.pdf 中的训练目标示意。严格地说目标来自一个分层的变分下界,但在实践中通常化简为对噪声的 L2 回归。
这里有两个容易被忽略的点:
- 这不是凭空选择了一个“好用的损失函数”,它来自概率模型与高斯 KL 的推导;
- 训练时预测噪声,推断时用噪声预测去构造逆过程均值,这两件事是一体的。
5. Noise Conditional Network:为什么一个网络就够了
Diffusion 模型可以看成把一个复杂分布拆成很多个更简单的噪声层级分布。理论上,每个噪声水平都可以有一个单独的网络;但那样当然不现实。
所以课程接着引入了一个关键想法:把所有噪声层级合并到一个条件网络中,让网络额外接收时间步或噪声水平 作为条件输入。

图:MIT 6.S978 lec5_diffusion.pdf 中对 Noise Conditional Network 的总结。扩散模型本质上把很多不同难度的去噪子任务交给同一个共享参数的网络。
这一步和前一篇 PixelCNN 里的 shared computation 很像:
- PixelCNN 把很多条件分布共享到一个网络;
- Diffusion 把很多噪声层级的去噪任务共享到一个网络。
所以从更高的角度看,现代生成模型经常都在做同一件事:把大量子问题统一放到一个共享参数的神经网络里。
6. 代码中,DDPM 的关键思想体现在哪里
下面四段代码对应了四个关键环节:
- 噪声 schedule;
- 前向加噪;
- 噪声预测目标;
- 逆过程采样。
6.1 schedule 决定了整条噪声路径
def ddpm_schedules(beta1, beta2, T):
beta_t = torch.linspace(beta1, beta2, T)
alpha_t = 1.0 - beta_t
alphabar_t = torch.cumprod(alpha_t, dim=0)
oneover_sqrta = 1.0 / torch.sqrt(alpha_t)
sqrt_beta_t = torch.sqrt(beta_t)
sqrtab = torch.sqrt(alphabar_t)
sqrtmab = torch.sqrt(1.0 - alphabar_t)
mab_over_sqrtmab_inv = (1.0 - alpha_t) / sqrtmab
return {
"alpha_t": alpha_t,
"oneover_sqrta": oneover_sqrta,
"sqrt_beta_t": sqrt_beta_t,
"alphabar_t": alphabar_t,
"sqrtab": sqrtab,
"sqrtmab": sqrtmab,
"mab_over_sqrtmab": mab_over_sqrtmab_inv,
}这段代码把推导里所有关键系数都预先算出来了。后面的前向加噪和逆过程采样,都依赖这些量。
可以把它理解成:论文里的符号推导在这里被落成了一张可直接查询的时间表。
6.2 前向加噪直接使用闭式采样
_ts = torch.randint(1, self.n_T + 1, (x.shape[0],)).to(self.device)
noise = torch.randn_like(x)
sqrtab = self.sqrtab[_ts - 1][:, None, None, None]
sqrtmab = self.sqrtmab[_ts - 1][:, None, None, None]
x_t = sqrtab * x + sqrtmab * noise这段代码正对应前面的闭式结果:
训练时随机采样一个时间步 ,再随机采样噪声 ,就可以直接得到对应的 noisy sample 。
这一步看起来很简单,但它本质上替代了“真的模拟到第 步”的整个过程。
6.3 训练目标就是预测噪声
return self.loss_mse(
noise,
self.nn_model(x_t, c, _ts / self.n_T, context_mask)
)这行代码就是 DDPM 训练的核心。网络的输入是:
- noisy image ;
- 条件标签 ;
- 时间归一化后的 ;
- context mask。
输出则是对噪声 的预测。损失函数就是预测噪声和真实噪声之间的 MSE。
这一步正对应“从变分下界到噪声 L2”的整个理论收束。
6.4 逆过程采样把噪声一步步拉回数据
for i in range(self.n_T, 0, -1):
t_is = torch.tensor([i / self.n_T]).to(device).repeat(n_sample * 2)
x_i_teased = x_i.repeat(2, 1, 1, 1)
with torch.no_grad():
eps = self.nn_model(x_i_teased, c_i, t_is, context_mask)
eps1 = eps[:n_sample]
eps2 = eps[n_sample:]
guided_eps = (1.0 + guide_w) * eps1 - guide_w * eps2
x_i = self.oneover_sqrta[i - 1] * (
x_i - guided_eps * self.mab_over_sqrtmab[i - 1]
)
if i > 1:
z = torch.randn(n_sample, *size).to(device)
x_i = x_i + self.sqrt_beta_t[i - 1] * z这段代码做了两件事情:
- 根据网络预测的噪声估计逆过程均值;
- 在每个时间步重新加入适当随机性,逐步采样到 。
同时,这里还实现了 classifier-free guidance:
这说明扩散模型在现代实践中已经不只是“基本 DDPM”,而是很自然地与条件控制和指导机制结合在了一起。
7. 从 DDPM 到 score matching:为什么二者本质相通
另一个重要视角是:Diffusion 模型和 score matching 是紧密相关的。

图:MIT 6.S978 lec5_diffusion.pdf 中对这条关系的总结。许多扩散模型中的关键概念,都和 score matching、denoising score matching 一起发展起来。
7.1 什么是 score
score function 定义为:
它表示在当前点上,概率密度增大的方向。
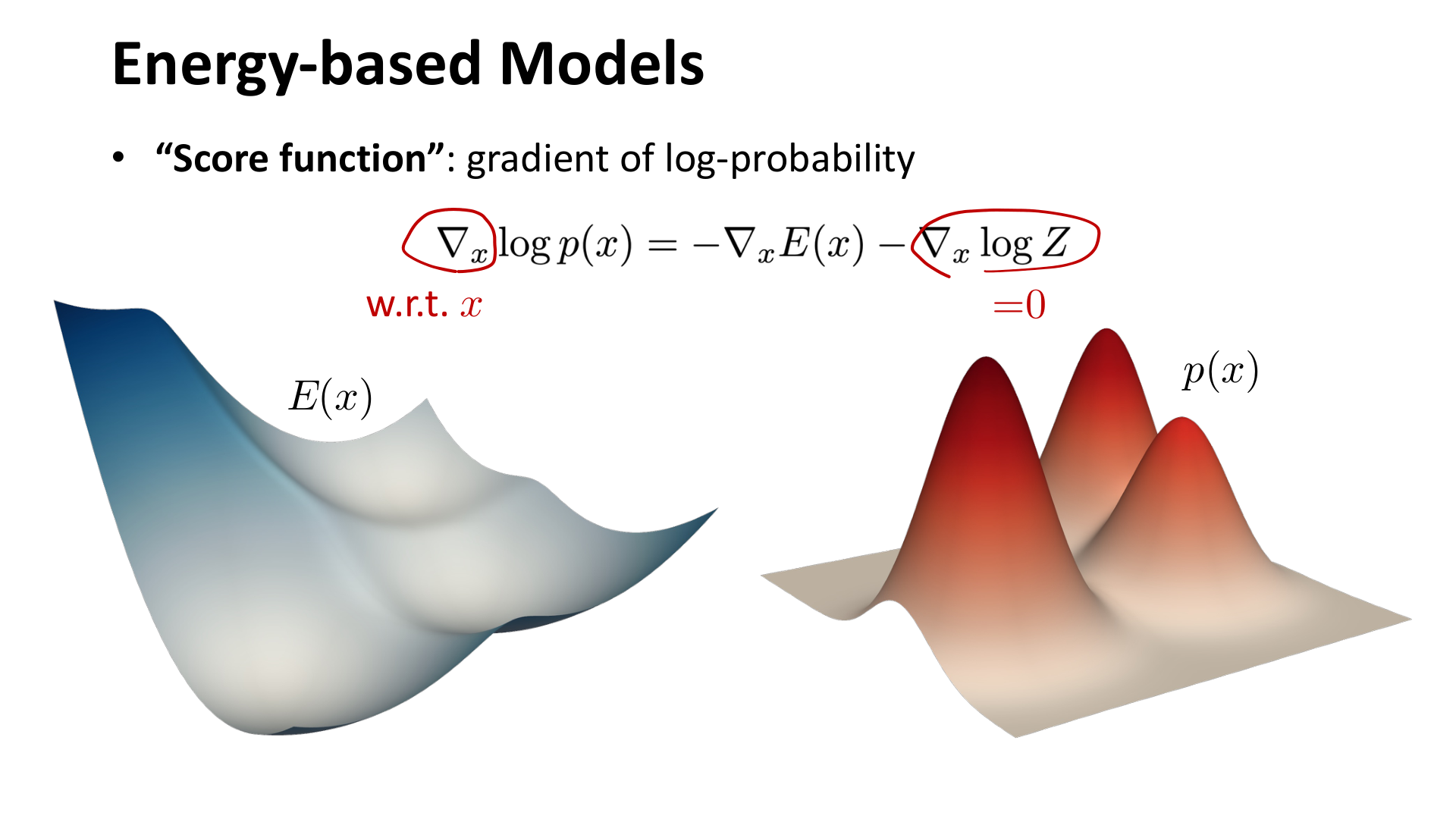
图:MIT 6.S978 lec5_diffusion.pdf 中对 score function 的说明。对于 energy-based model,score 也可以看作负能量函数关于输入的梯度。
这个定义的好处在于:即使概率分布本身带有难以计算的归一化常数,score 仍然可能是可学的,因为常数对 的梯度为零。
7.2 为什么去噪和 score matching 会连起来
在 denoising score matching 中,先对数据加噪,再学习 noisy distribution 的 score。对于高斯噪声情形,可以证明这个目标最终会退化为一个与噪声预测非常接近的目标。

图:MIT 6.S978 lec5_diffusion.pdf 中对 denoising score matching 的关键结果。带噪数据上的 score matching 与条件去噪之间可以建立严格联系。
这也解释了为什么扩散模型里“预测噪声”不是一个偶然的工程技巧,而与 score estimation 有深刻的理论对应。
8. 连续时间视角:Langevin Dynamics、SDE 与更统一的理解
如果把时间步数推到连续极限,扩散模型可以用 SDE 或 ODE 的方式来理解。
给定 score function,可以通过 Langevin Dynamics 进行采样:

图:MIT 6.S978 lec5_diffusion.pdf 中对 Langevin Dynamics 的解释。只要有 score,就可以沿着概率密度上升方向再叠加随机扰动,从而逐步采样。
从这个角度看,DDPM 不是一个孤立算法,而是更大一类随机动力系统生成模型中的一个离散时间实例。
9. Diffusion 模型的几个视角为什么值得同时保留
Diffusion 模型可以从多个角度理解:
- 分层 VAE;
- energy-based model 与 score matching;
- SDE / ODE;
- 甚至和 autoregressive、normalizing flows 等方向建立联系。

图:MIT 6.S978 lec5_diffusion.pdf 中对 diffusion 多重视角的总结。一个成熟的理解不应只停留在某一个公式层面。
这也是为什么扩散模型值得花更多篇幅去写:它并不是单一技巧,而是多个生成建模传统汇合的结果。
10. 为什么今天还要从第一性原理理解 Diffusion
扩散模型现在已经非常流行,但如果只记住“不断加噪、不断去噪”,理解其实还很浅。真正需要把握的是下面几层结构:
- 先构造一个已知且可控的前向噪声过程;
- 再学习依赖数据分布的逆过程;
- 利用高斯结构把目标化简为噪声的 L2 回归;
- 用时间条件网络共享所有噪声层级;
- 再从 score matching 和连续时间视角理解它的更一般形式。
从这个角度看,Diffusion 的成功并不是依赖某一个“魔法技巧”,而是因为它把很多复杂问题拆成了结构非常清楚的子问题。
参考资料
- Jonathan Ho, Ajay Jain, Pieter Abbeel, Denoising Diffusion Probabilistic Models
- Yang Song et al., Score-Based Generative Modeling through Stochastic Differential Equations
- Yang Song, Score-based generative modeling blog
- Lilian Weng, What are Diffusion Models?
- MIT 6.S978 Deep Generative Models, Course Schedule
- MIT 6.S978 Deep Generative Models,
lec5_diffusion.pdf