Variational AutoEncoder, VAE 是现代生成模型中最适合先系统理解的一类模型。它的重要性不在于今天最强的样本质量,而在于它把潜变量建模、近似推断和神经网络参数化统一在了同一个可训练框架里:
- 我们怎样显式地定义一个生成过程?
- 当后验分布难算时,怎样做近似推断?
- 神经网络怎样参与这个概率模型,而不只是做一个黑箱拟合器?
这里真正需要回答的问题是:
为什么 VAE 的目标函数长成今天这样?
理解这个问题之后,再看后面的 Flow、Diffusion、Flow Matching,会更容易把握它们各自的建模选择。
1. 从生成问题出发:为什么要引入潜变量
我们真正想学的是数据分布 。如果数据是图像,那么 是高维像素;如果数据是句子,那么 是一个 token 序列。困难在于,真实数据往往有一种低维结构隐藏在高维观测之下。
这就是潜变量模型的出发点:假设数据不是凭空出现的,而是由某个更简单的隐藏变量 生成出来的。于是我们写出一个两步生成过程:
这里的 一般取简单先验,比如标准高斯 。这样总分布就变成:
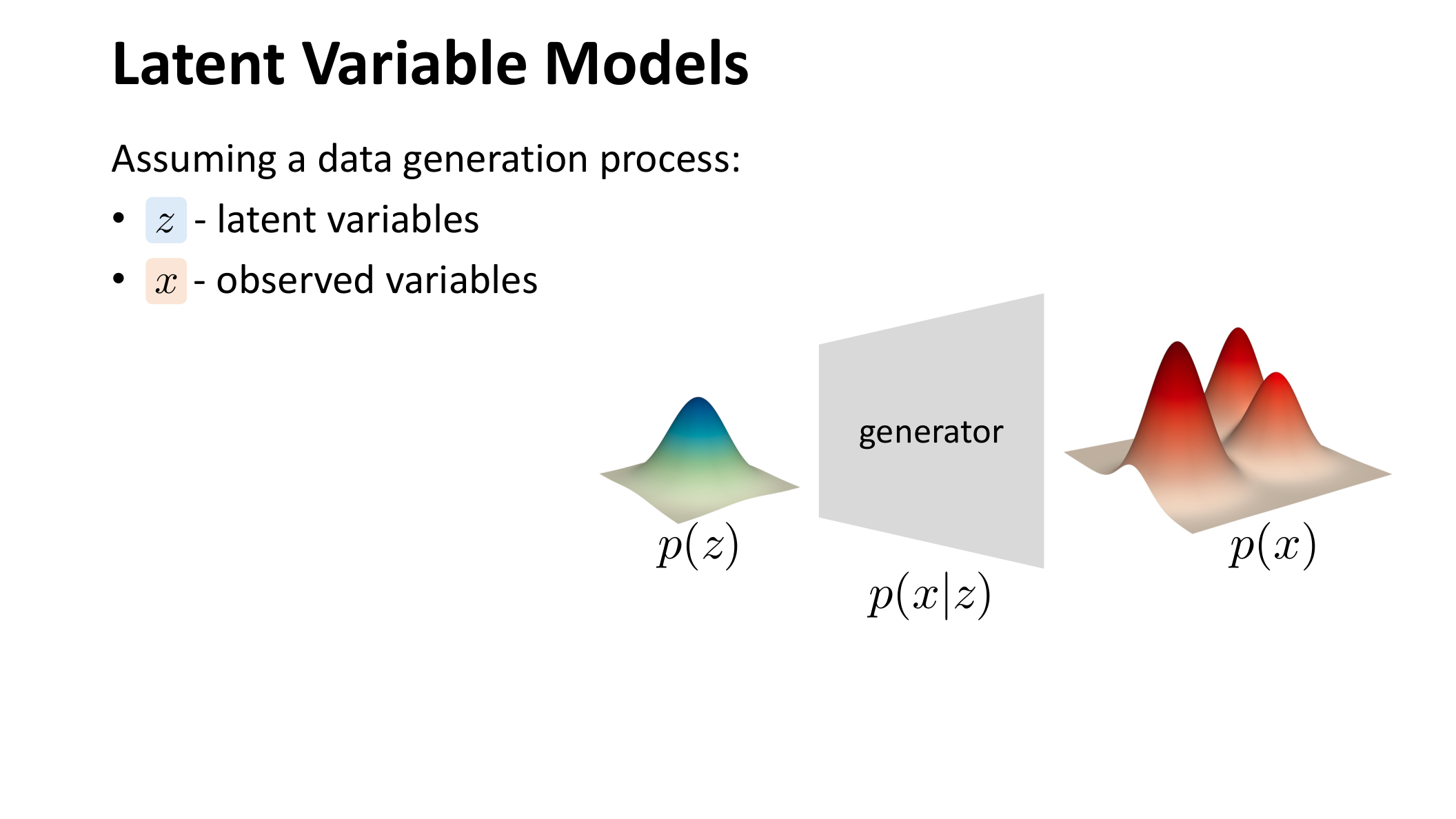
图:MIT 6.S978 lec2_vae.pdf 中对潜变量模型的示意。左侧的先验分布 经过生成器 之后,诱导出数据分布 。
这里需要特别区分 VAE 和普通 AutoEncoder。VAE 的关键不在于“加入噪声”,而在于:
- 它把编码器和解码器放回了一个概率模型里;
- 它不是只想重建输入,而是想学习一个真正的生成分布;
- 它要求 latent space 不是任意的,而是必须和一个可采样的先验分布对齐。
2. 为什么直接最大化似然会遇到困难
如果我们观察到了一个样本 ,最自然的问题是:它对应的潜变量 是什么?这对应后验分布:
问题在于,分母正是:
如果目标是学习生成分布,那么最自然的想法是直接最大化数据的对数似然 。但在潜变量模型中, 本身包含对潜变量的积分,而后验又依赖于这个积分。因此困难的核心不在于生成过程无法写出,而在于相关概率量无法直接计算。VAE 的核心做法,就是把这个问题改写成一个可优化的下界问题。
3. 引入近似后验,并把问题改写成 ELBO
我们引入一个近似后验分布 ,用它来逼近真正的 。接下来对 做一个标准但非常深刻的分解:
因为最后一项 KL 散度总是非负,所以得到:
这就是 Evidence Lower Bound, ELBO。

图:MIT 6.S978 lec2_vae.pdf 中对 ELBO 的解释。红框对应直接优化时不可解的项,绿框对应可以计算或近似计算的项。VAE 的训练正是通过优化这个下界来替代直接优化 。
这条式子已经包含了 VAE 的主要思想:
- 第一项 逼着模型“从潜变量把数据重建回来”;
- 第二项 逼着编码器产出的 latent distribution 不要乱跑,而要贴近先验;
- 当我们最大化 ELBO 时,本质上是在同时做生成建模和近似推断。
这里有一个很容易被简化过头的地方:KL 项不是一个事后附加的正则项,而是概率推断结构的一部分。没有它,latent space 更接近一个压缩表示空间;有了它,latent space 才能和先验分布对齐,从而具备生成意义。
4. 参数化近似后验之后,VAE 的目标函数是什么
在最常见的实现里,我们通常令:
这时 ELBO 里的 KL 项可以解析写出来:
于是训练目标就变成大家最熟悉的形式:
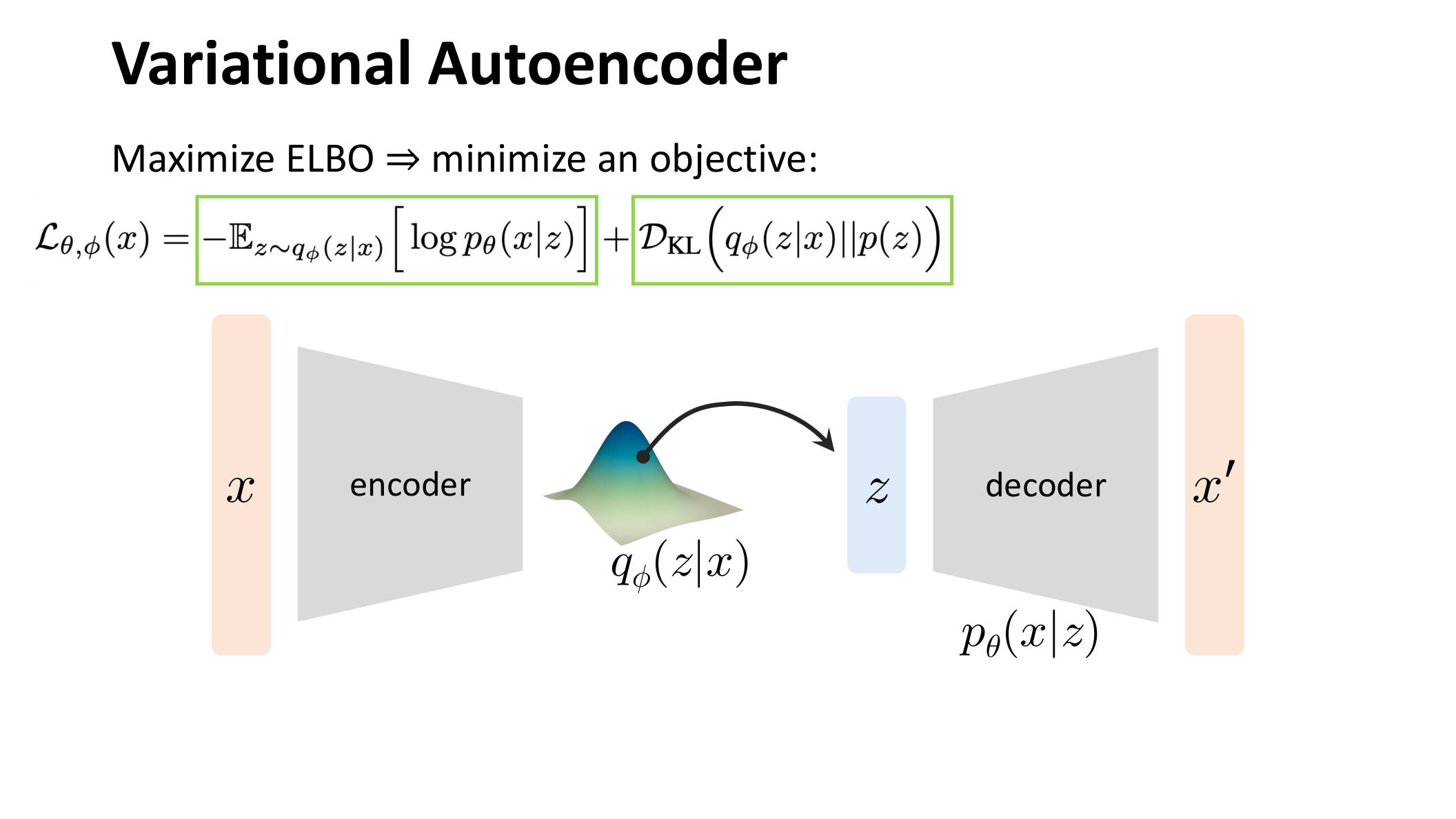
图:MIT 6.S978 lec2_vae.pdf 中对 VAE 目标函数和结构的整体展示。输入 经过编码器得到近似后验 ,采样得到 后再由解码器建模 。
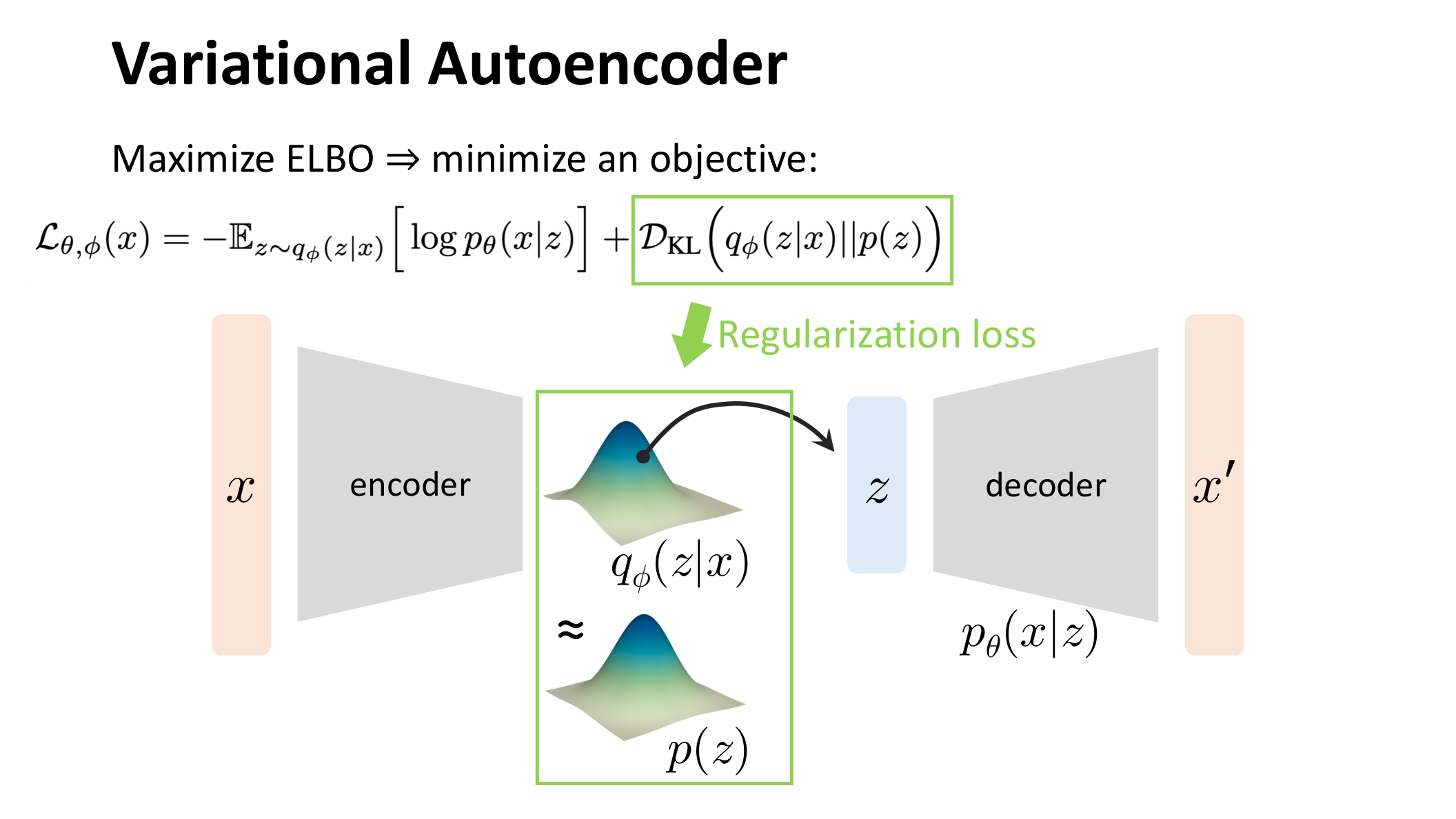
图:MIT 6.S978 lec2_vae.pdf 中对正则项的解释。KL 项要求编码器输出的后验分布不要偏离先验分布 太远,这一步保证了 latent space 的可采样性。
这也是为什么很多教程把 VAE 写成“重建误差 + KL 正则”。这种写法在工程上是方便的,但如果只停留在这个层面,往往会遗漏它背后的变分推断结构。更准确地说,这两部分对应的是:
- reconstruction term 对应如何建模 ;
- KL term 对应如何约束 与先验 的关系;
- 二者共同对应的是一个对数似然下界,而不是两个任意拼起来的损失。
5. 重参数化:怎样让采样进入反向传播
如果直接从 里采样,那么 会随机依赖于参数 ,这会让反向传播很不稳定。VAE 的第二个关键点是 reparameterization trick:
这一步的本质不是“换一种记号”,而是把随机性从参数依赖中剥离出来,改写成:
- 随机噪声 负责 stochasticity;
- 负责可导的确定性变换。
于是梯度就可以稳定地回传到编码器参数。这一步使 VAE 能够以标准的反向传播方式进行训练。
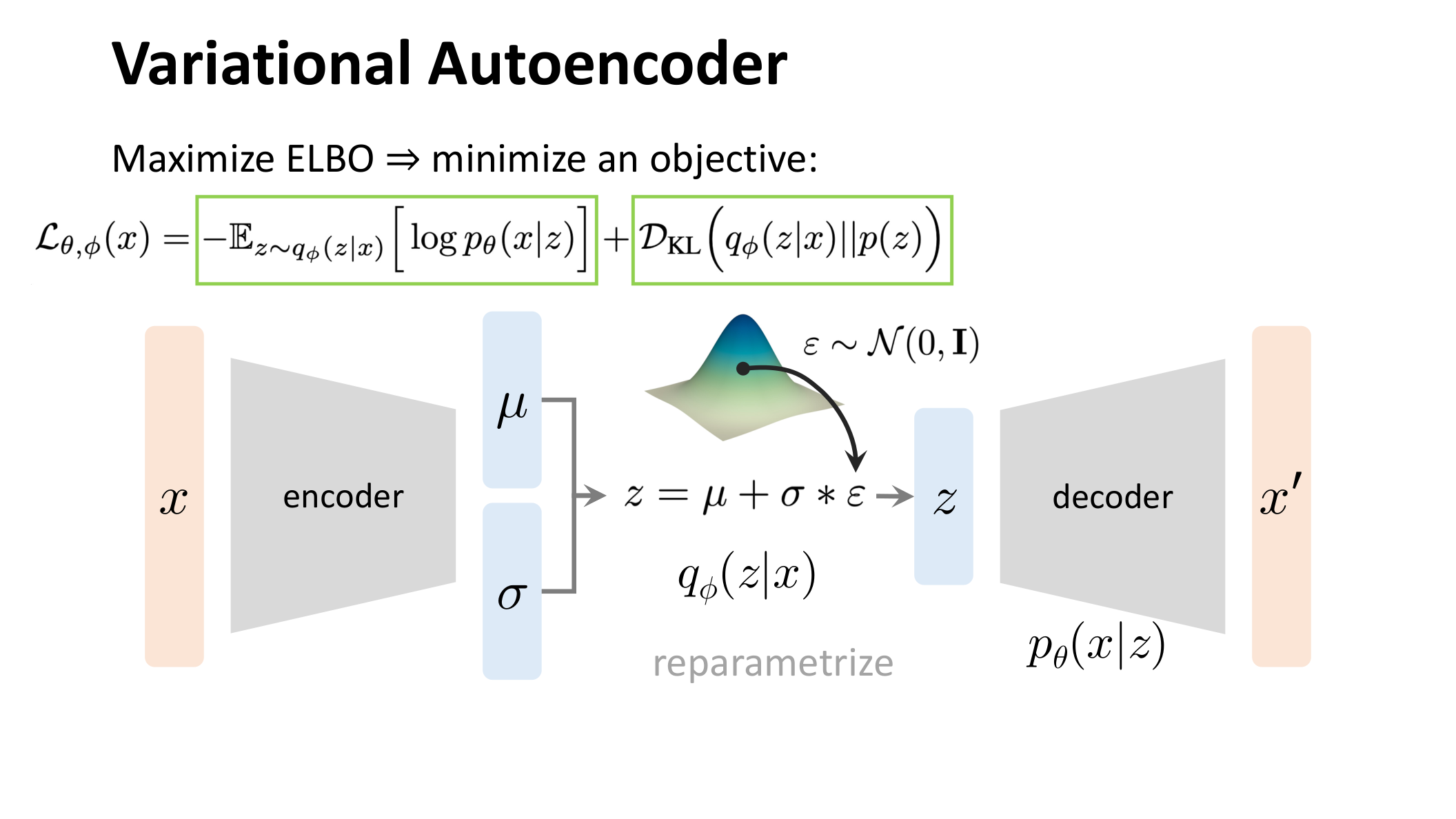
图:MIT 6.S978 lec2_vae.pdf 中对重参数化技巧的示意。编码器不直接输出一个样本,而是输出 和 ,再结合独立噪声 构造出 。
这里还有两个容易被忽略的问题:
- 训练时优化的不是单个样本,而是数据分布上的期望;
- 推断时真正做生成,并不需要编码器,而是直接从先验分布采样。
从这个角度看,VAE 在训练阶段同时使用编码器和解码器,但在生成阶段只需要解码器。
6. 生成阶段:VAE 如何真正生成样本
训练完成后,生成过程很直接:
这意味着在推断阶段,不需要先给定一个输入样本再经过编码器。只要能够从先验分布 中采样,再经过解码器,就可以得到新的样本。
图:MIT 6.S978 lec2_vae.pdf 中对生成过程的示意。生成时直接从先验分布采样,然后通过解码器映射到数据空间。
还可以从另一种视角理解 VAE:它连接的是“编码分布”和“解码分布”。
图:MIT 6.S978 lec2_vae.pdf 中的分布视角。解码器把 latent distribution 映射到数据分布,编码器则把数据分布映射回 latent distribution。
这个视角的重要性在于,它让 VAE 不再只是“输入一张图再重建一张图”的模型,而是一个在两个概率空间之间建立映射关系的模型。
7. 代码中,VAE 的关键思想体现在哪里
下面三段代码对应了 VAE 的三个关键环节。
7.1 编码器不是输出一个点,而是输出一个分布
def encode(self, x):
mean, logvar = torch.split(
self.encoder(x),
split_size_or_sections=[self.z_size, self.z_size],
dim=-1
)
return mean, logvar这里最重要的不是 split 这个操作本身,而是它体现了 VAE 和普通 AutoEncoder 的本质差异:
- AutoEncoder 把 映射到一个确定的 latent vector;
- VAE 把 映射到一个高斯分布的参数 。
也就是说,编码器学的不是“一个坐标”,而是“一个关于潜变量的不确定性描述”。
7.2 重参数化把随机采样变成可导计算图
def reparameterize(self, mean, logvar, n_samples_per_z=1):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = eps * std + mean
return z这几行代码直接对应重参数化公式。eps 提供噪声,mean 和 std 把标准高斯映射到样本相关的后验分布上。这样既保留了采样过程,也保留了梯度。
7.3 当先验和后验都取高斯时,KL 可以解析计算
def loss_KL_wo_E(output):
var = torch.exp(output['logvar'])
logvar = output['logvar']
mean = output['mean']
return -0.5 * torch.sum(
torch.pow(mean, 2) + var - 1.0 - logvar,
dim=[1]
)这段代码对应的正是上面的解析 KL 项。它说明:
- 当模型结构选得合适时;
- 概率推断里的某些项其实能写成封闭形式;
- 这会让训练目标既更稳定,也更接近理论本身。
这三段代码分别对应前面的三个核心对象:
encode()对应近似后验 的参数化;reparameterize()对应从 到样本 的可导采样过程;loss_KL_wo_E()对应 KL 正则项的解析计算。
8. 从实验结果看 VAE 在学什么
下面几张图展示的是这一实现得到的实验结果。
8.1 用 SGVB 估计 ELBO 的生成结果

这张图说明模型已经能够从先验空间采样,并生成符合 MNIST 分布特征的数字。更准确地说,模型学习到的是一个连续的潜变量分布,而不是对训练样本的逐点记忆。
8.2 用解析 KL 目标训练的生成结果

当部分 ELBO 可以写成解析形式时,训练通常会更稳定,latent space 的组织也往往更规整。很多 VAE 实现的差异,最后都会体现在这里:模型学到的是一个可采样的潜变量空间,还是一个仅用于重建的表示空间。
8.3 SGVB 与解析 KL 的损失对比
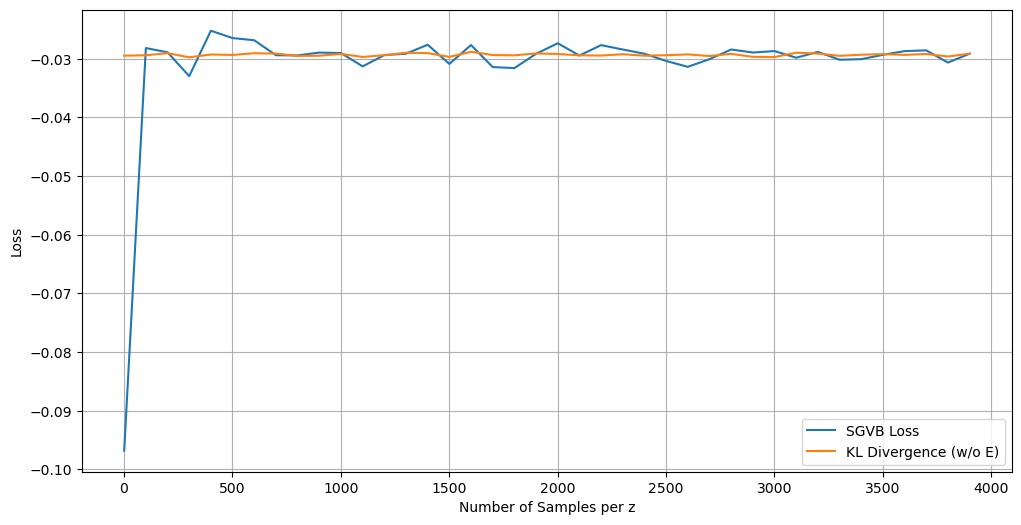
这张对比图的价值不在于简单比较“哪条曲线更低”,而在于说明:同一个理论目标可以对应不同的估计方式,而不同估计器的偏差和方差会直接影响训练表现。
8.4 潜空间插值是检验 latent structure 的最好方式之一
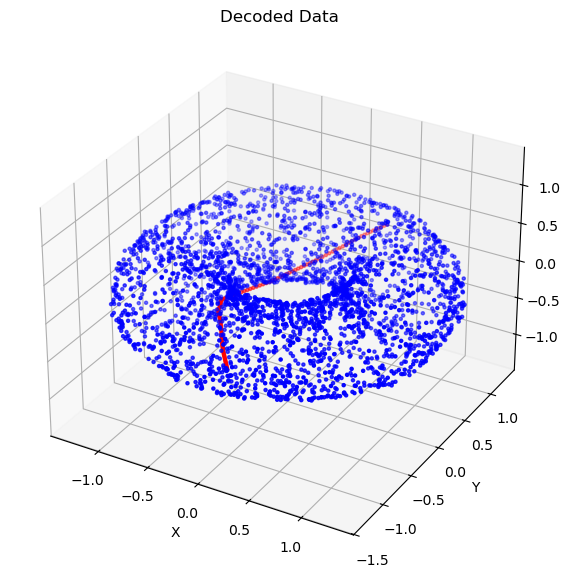
插值实验之所以重要,是因为它不只是看“能不能生成”,而是在看:
- latent space 是否连续;
- 邻近点是否对应语义相近的样本;
- 解码器是否学到了一张平滑的生成流形。
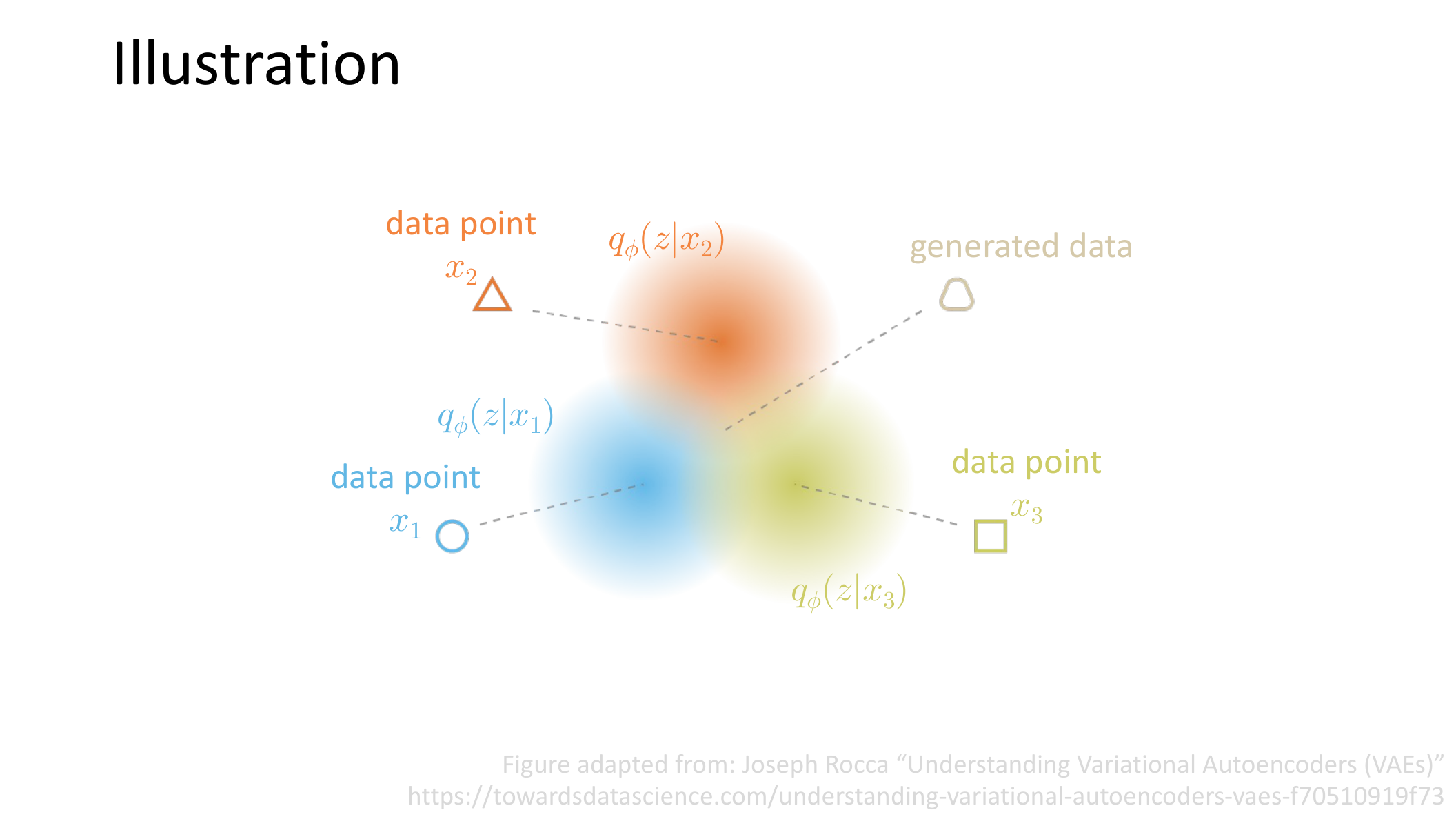
图:MIT 6.S978 lec2_vae.pdf 中的示意图。不同样本在潜空间中对应不同的后验分布区域,生成过程则是在这些分布之间学习一个平滑的概率结构。
这也是为什么 VAE 长期被用于 representation learning 和 controllable generation。它的优势不只体现在生成结果上,更体现在它显式构造了一个可操作的隐变量空间。
9. VAE 的局限性在哪里
VAE 有明确的理论结构,但它也有清楚的局限。
- 如果解码器太强,编码器可能被“绕开”,出现 posterior collapse;
- 当观测分布很复杂时,简单高斯后验往往不够灵活;
- 由于目标是 ELBO 而不是精确最大似然,最终样本质量常常不如后来的一些生成模型;
- 像素级重建损失容易让图像显得平滑,尤其在自然图像上更明显。
这正是后来很多模型继续向前走的原因:
- Flow 追求可精确计算的 likelihood;
- GAN 追求更锐利的样本质量;
- Diffusion 与 Flow Matching 追求更强的生成能力和更稳定的训练路径。
但这些后来的路线,并没有让 VAE 失去价值。相反,VAE 留下了一个直到今天仍然重要的认识:
生成模型不只是一个采样器,也可以是一套近似推断系统。
10. 为什么今天还要学 VAE
如果目标只是关注当前最强的图像生成结果,研究重心通常会放在 Diffusion 一类模型上。但如果目标是建立稳定的生成模型理解,VAE 仍然是很难绕开的一步,因为它第一次把这些思想放到了同一个训练框架里:
- 潜变量建模;
- 近似后验;
- 下界优化;
- 可导采样;
- 结构化 latent space。
从这个角度看,VAE 连接了两类传统上相对分开的思想:一端是概率图模型与变分推断,另一端是深度神经网络驱动的生成建模。
参考资料
- Diederik P. Kingma, Max Welling, Auto-Encoding Variational Bayes
- MIT 6.S978 Deep Generative Models, Course Schedule
- MIT 6.S978 Deep Generative Models,
lec2_vae.pdf - Lilian Weng, From Autoencoder to Beta-VAE