自回归模型是现代生成模型中最基本、也最持久的一条路线。它的重要性不只体现在 PixelCNN 这类图像模型上,更体现在今天的大语言模型、语音生成模型和一大类序列建模方法中。
如果只看表面形式,自回归模型似乎只是“预测下一个元素”。但从概率建模的角度看,它真正做的事情是:
不再直接建模整个高维联合分布,而是把联合分布分解成一串条件分布。
核心问题有三个:
- 为什么联合分布可以写成条件分布的乘积;
- 为什么自回归模型在训练和推断时是两种不同的过程;
- PixelCNN 如何用掩码卷积把这种思想落实到图像上。
1. 从联合分布开始:高维数据为什么难建模
生成模型的目标仍然是学习数据分布 。如果 是一张图像,那么它可以看作一个高维随机变量:
困难在于,这些维度通常不是独立的。对于图像来说,一个像素的取值会受到周围像素的强烈影响;对于文本来说,下一个 token 的概率依赖前面的上下文;对于语音来说,当前采样点也依赖过去的波形结构。
VAE 代表的是一条通过潜变量间接建模复杂分布的路线。但如果直接面对高维联合分布,单纯依赖独立潜变量往往不够。
另一条路线是不先引入潜变量,而是直接对联合分布本身做分解。
2. 链式法则:任何联合分布都可以拆成条件分布
自回归建模最根本的数学基础是概率论中的链式法则。对于任意联合分布,都有:
这一步很关键,因为它不是近似,也不是技巧,而是一个严格成立的恒等式。

图:MIT 6.S978 lec3_ar.pdf 中对链式法则的基本表达。自回归模型的全部出发点,就是把联合分布转写成条件分布的连乘。
对生成模型来说,这样做带来两个直接后果:
- 建模时不再需要一次性输出整个联合分布;
- 生成时可以按某个顺序逐步采样。
当然,链式法则允许任意顺序。理论上,左到右、右到左、按块分组、甚至更复杂的顺序都成立。但一旦选定了顺序,模型就同时获得了一种 inductive bias。这个顺序决定了“哪些条件是过去,哪些变量是未来”。
3. 什么叫自回归
这里需要先区分一个常见误解:autoregressive 首先描述的是推断时的行为,而不是某种固定网络。
自回归的核心含义是:
- 当前步骤的分布依赖于之前已经生成出的结果;
- 模型用自己的历史输出,递归地生成后续变量。
因此,自回归并不等于某一种架构。RNN 可以做自回归,CNN 可以做自回归,Transformer 也可以做自回归。决定它是否是自回归的,不是“用了什么层”,而是“当前输出是否只依赖过去而不依赖未来”。
4. 训练与推断为什么不同
理解自回归模型时,最容易混淆的地方就是训练和推断。
4.1 推断时是真正的逐步生成
如果已经有了条件分布
那么生成过程就是:
- 先从 采样;
- 再从 采样;
- 再从 采样;
- 持续到最后一个变量。

图:MIT 6.S978 lec3_ar.pdf 中对自回归推断的示意。对于图像来说,推断是逐像素进行的,当前像素只能由之前已经生成出的像素决定。
4.2 训练时通常使用 teacher forcing
如果真的按照推断图来训练,那么梯度路径会非常长,而且每一步都要穿过之前的采样操作,这在大模型里往往是不可行的。因此训练通常使用 teacher forcing:
- 输入不是模型前一步生成的结果;
- 输入直接来自 ground-truth 数据。
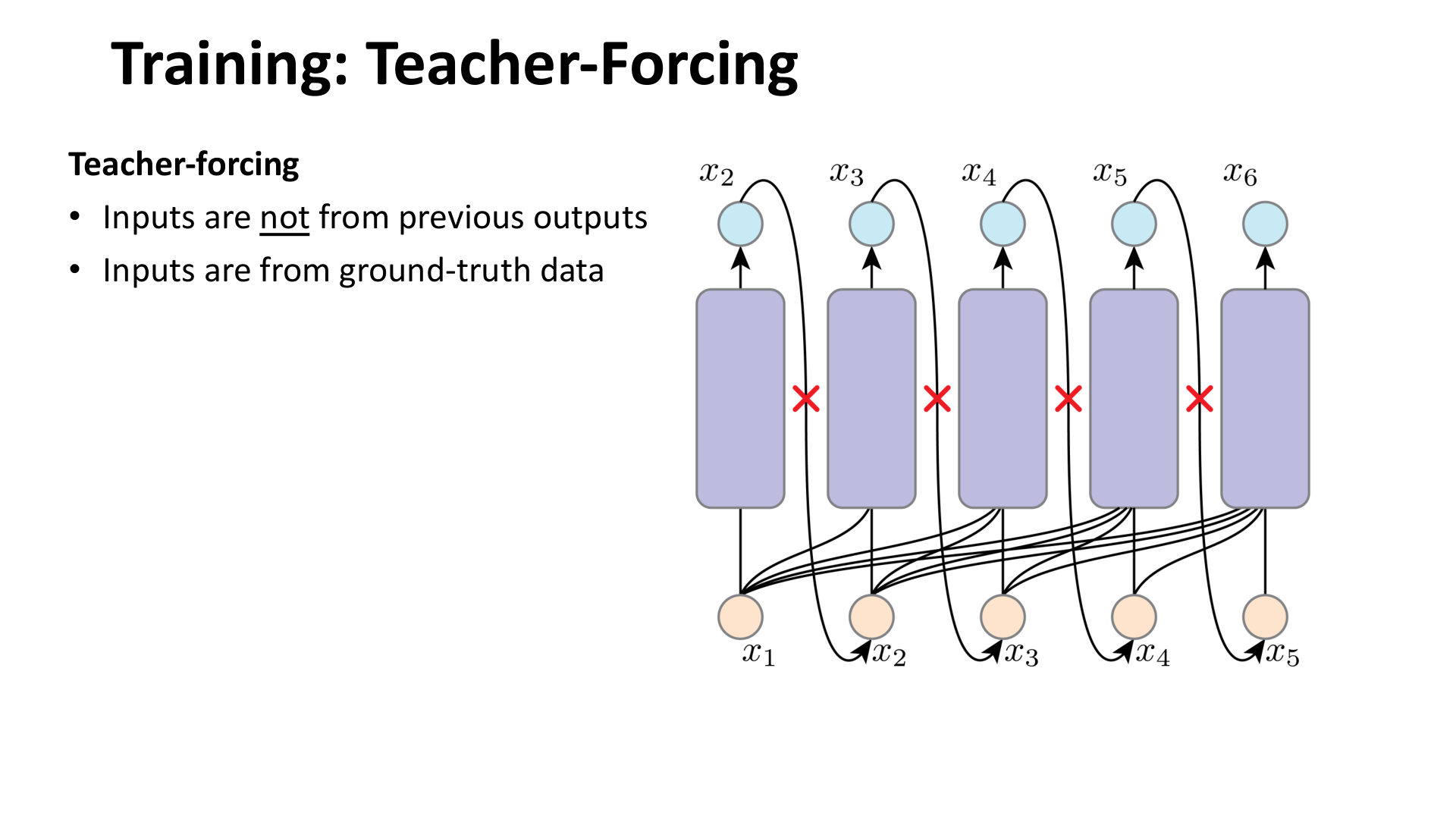
图:MIT 6.S978 lec3_ar.pdf 中对 teacher forcing 的示意。训练时,当前预测所依赖的历史上下文直接来自真实数据,而不是模型自己的采样结果。
放到图像上,这意味着训练某一个像素时,条件部分来自真实图像中已经出现的位置:

图:MIT 6.S978 lec3_ar.pdf 中对图像自回归训练的示意。红框像素是当前要预测的位置,蓝色区域是允许使用的真实上下文。
这样做的优点是:
- 训练可以并行化得更充分;
- 反向传播路径更短;
- 优化更稳定。
代价是训练和推断之间出现了差异:训练时看到的是“真实历史”,推断时看到的是“模型自己生成的历史”。这就是自回归模型里常说的 exposure bias 或分布偏移问题。
5. 共享计算:为什么自回归训练可以高效实现
如果按照链式法则最朴素的写法,每个条件分布似乎都需要一个单独的网络:
这样当然太低效。关键思想是 shared computation。
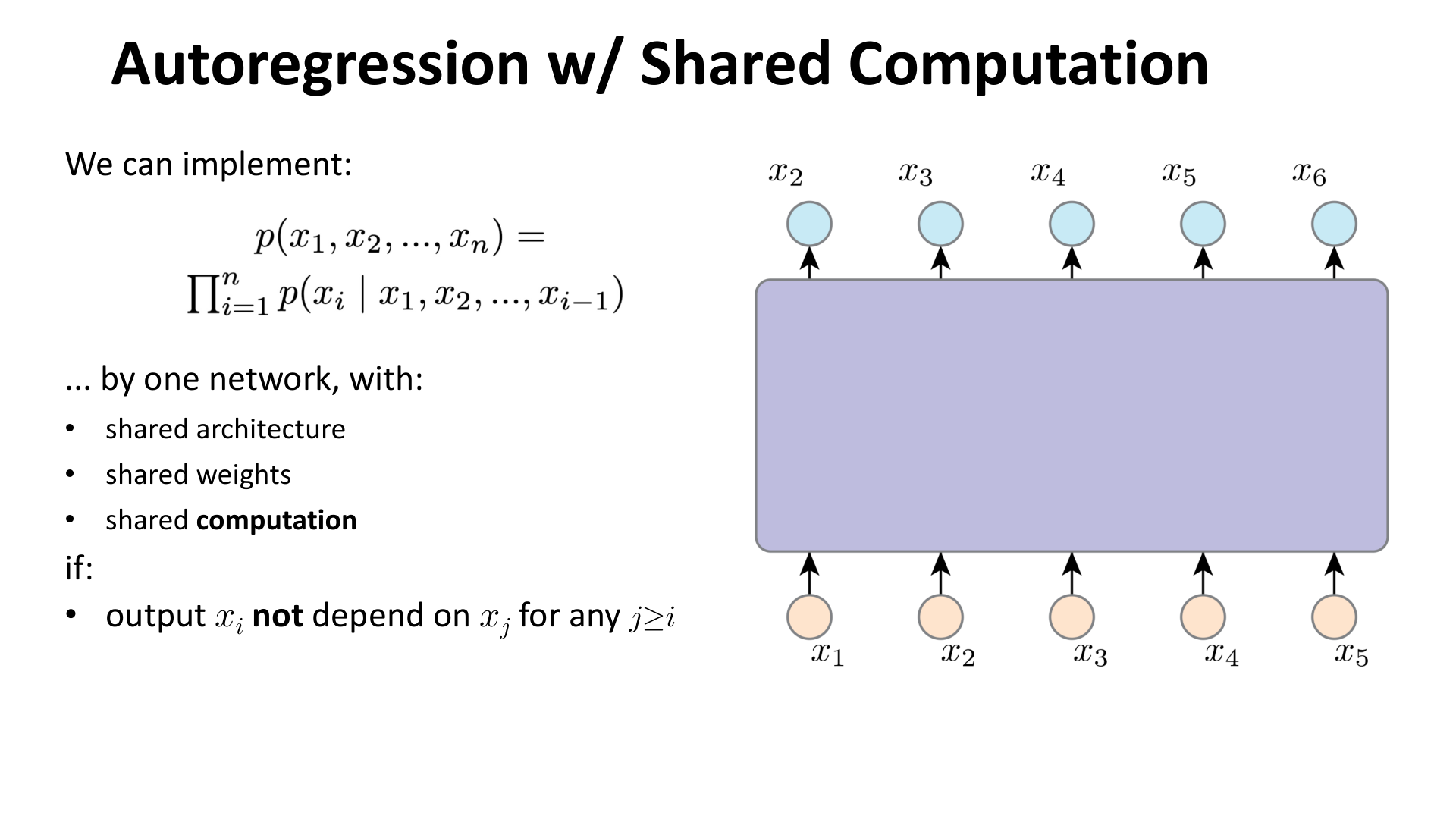
图:MIT 6.S978 lec3_ar.pdf 中对 shared computation 的示意。只要第 个输出不依赖未来位置 ,就可以用一个共享参数的网络同时实现所有条件分布。
这一步是现代自回归模型能真正扩展起来的关键。否则无论是 PixelCNN、WaveNet 还是 GPT,都不可能训练到今天的规模。
从这个角度看,自回归模型的核心不是“逐步生成”本身,而是:
- 用链式法则定义概率结构;
- 用参数共享把多个条件分布合并到一个网络里;
- 再用合适的结构约束保证“看不到未来”。
6. PixelCNN:用卷积网络实现图像自回归
对图像来说,一个自然的顺序是 raster order,也就是按行从左到右、从上到下扫描像素。这样,一张图像就可以看成一个像素序列。

图:MIT 6.S978 lec3_ar.pdf 中对图像自回归的起点示意。PixelCNN 的基本做法,就是选定这种像素顺序,然后只根据已出现的像素预测当前像素。
CNN 本来非常适合做图像建模,因为它天然共享参数和局部计算。但普通卷积会同时看到过去和未来,这违反了自回归约束。因此需要引入 causal convolution 的思想:当前输出只能依赖历史位置。
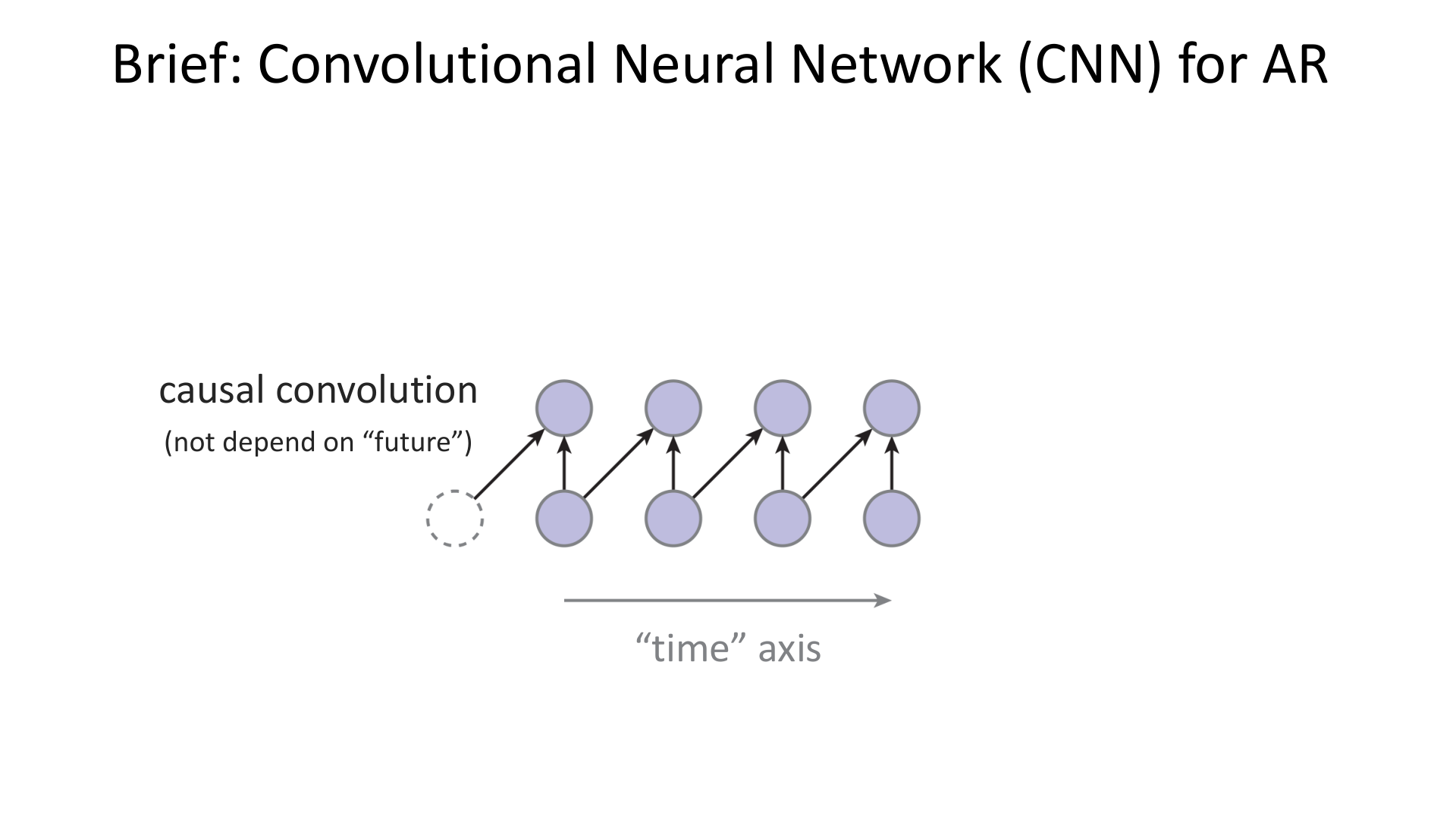
图:MIT 6.S978 lec3_ar.pdf 中对因果卷积的示意。在一维序列中,卷积核需要被限制为不能访问未来位置。PixelCNN 只是把这个思想推广到了二维图像网格上。
对于二维图像,PixelCNN 的关键做法是给卷积核加上掩码:
- 当前像素右边的位置不能看;
- 当前像素下方的位置不能看;
- 第一层通常还不能看当前像素本身;
- 后续层可以在不破坏自回归约束的前提下看当前像素位置的中间表征。
这就对应了常见的 Mask A 和 Mask B。
7. 代码中,PixelCNN 的关键思想体现在哪里
下面几段代码对应了上面的三件事情:
- 如何通过掩码保证“看不到未来”;
- 如何用一个 CNN 表示所有条件分布;
- 如何在推断时真正逐像素采样。
7.1 MaskedConv2d:把因果约束写进卷积核
class MaskedConv2d(nn.Conv2d):
def __init__(self, mask_type, *args, **kwargs):
super().__init__(*args, **kwargs)
assert mask_type in ('A', 'B')
self.register_buffer('mask', self.weight.data.clone())
_, _, kH, kW = self.weight.size()
self.mask.fill_(1)
self.mask[:, :, kH // 2, kW // 2 + (mask_type == 'B'):] = 0
self.mask[:, :, kH // 2 + 1:] = 0
def forward(self, x):
self.weight.data *= self.mask
return super().forward(x)这段代码是整篇文章里最重要的一段。它把“未来信息不可见”直接编码进卷积核:
- 中心像素右侧全部置零;
- 下一行以及更下面的卷积权重全部置零;
A型掩码连中心位置本身也屏蔽;B型掩码保留中心位置,用于更深层的特征传递。
换句话说,PixelCNN 并不是先做普通卷积,再在损失函数里“提醒模型不要看未来”,而是直接在结构上禁止这种依赖出现。
7.2 PixelCNN:一个网络同时输出所有位置的条件分布
class PixelCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = MaskedConv2d('A', in_channels=1, out_channels=64, kernel_size=7, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.conv2 = MaskedConv2d('B', 64, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = MaskedConv2d('B', 64, 64, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(64)
self.conv4 = MaskedConv2d('B', 64, 64, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.conv5 = MaskedConv2d('B', 64, 64, kernel_size=3, padding=1)
self.bn5 = nn.BatchNorm2d(64)
self.out_conv = nn.Conv2d(64, 1, kernel_size=1)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
return torch.sigmoid(self.out_conv(x))这里最重要的不是网络深不深,而是它体现了前面说的 shared computation:
- 一个网络同时处理整张图;
- 每个位置都输出该位置像素的条件分布;
- 由于卷积核被掩码约束,任何位置都不会读到未来像素。
所以从概率角度看,这个网络不是在输出“一张图”,而是在同时输出整张图上所有位置对应的条件伯努利分布。
7.3 推断时仍然必须逐像素采样
samples = torch.zeros(size=(64, 1, H, W)).to(device)
with torch.no_grad():
for i in range(H):
for j in range(W):
if j > 0 and i > 0:
out = model(samples)
samples[:, :, i, j] = torch.bernoulli(
out[:, :, i, j],
out=samples[:, :, i, j]
)这段代码很好地说明了自回归模型训练和推断的区别:
- 训练时整张图可以并行送入网络;
- 推断时仍然必须按顺序一个像素一个像素生成。
也就是说,掩码卷积帮助的是“并行计算条件分布”,而不是“取消自回归采样本身”。
7.4 条件版本:把类别信息注入每一层
class ConditionalMaskedConv2d(MaskedConv2d):
def __init__(self, mask_type, in_channels, out_channels, kernel_size, num_classes, padding=0):
super().__init__(mask_type, in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, padding=padding)
self.cond_proj = nn.Linear(num_classes, out_channels)
def forward(self, x, class_condition):
out = super().forward(x)
cond = self.cond_proj(class_condition)
cond = cond.unsqueeze(-1).unsqueeze(-1)
return out + cond这段代码体现了 conditional PixelCNN 的核心思想:类别条件并不是在最后一步拼接一下,而是被投影到通道维度,并加到每一层的特征里。这样,模型学到的条件分布就不再是
而是
其中 是类别信息。
8. PixelCNN 在自回归家族中的位置
这一讲的一个重要收束是:自回归不是 PixelCNN 独有的,而是一整类方法。
- RNN 用递归状态实现自回归;
- CNN 用因果卷积或掩码卷积实现自回归;
- Transformer 用 causal attention 实现自回归。
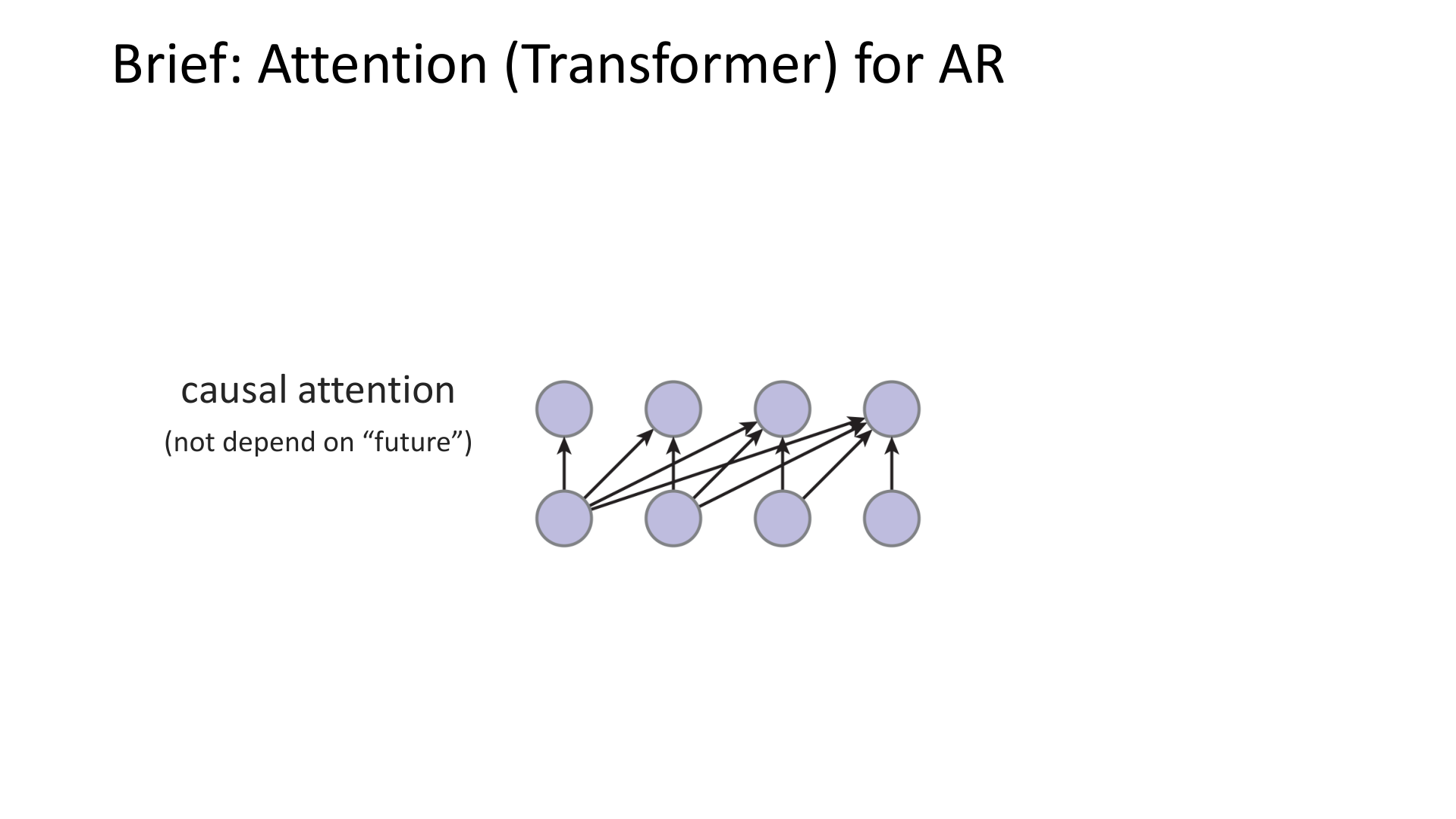
图:MIT 6.S978 lec3_ar.pdf 中对 Transformer 自回归约束的示意。GPT 这类模型本质上也属于自回归模型,只是把“看不到未来”的约束放进了注意力掩码中。
因此,PixelCNN 更准确的定位是:
PixelCNN 是“用卷积网络做图像自回归建模”的一个具体实现。
它不是自回归思想本身,而是自回归思想在二维图像上的一个典型例子。
9. PixelCNN 的局限性
PixelCNN 的优点是明确的:
- 概率建模严格;
- 对数似然可以直接优化;
- 结构清楚,训练目标明确。
但它的局限也同样明显:
- 推断速度慢,因为生成必须逐像素进行;
- 长程依赖建模效率有限,尤其是浅层卷积时更明显;
- 对高分辨率图像来说,采样代价很高;
- 像素级离散建模虽然严格,但未必最符合人类语义层面的结构。
这也是为什么后来图像生成逐渐转向其他路线,例如:
- VQ-VAE 先把图像离散化成 token,再在 token 上做自回归;
- Diffusion 通过逐步去噪来生成图像;
- Flow Matching 与 Consistency Models 则从连续动力学角度重新设计生成过程。
10. 为什么今天仍然要学 PixelCNN
即使在今天,PixelCNN 仍然有三个持续重要的价值。
第一,它把“联合分布建模”这件事讲得非常直接。
第二,它清楚地区分了训练和推断。
第三,它说明了架构只是载体,核心是概率分解和因果约束。
和 VAE 对照起来看,会得到一个非常清晰的区别:
- VAE 通过潜变量来间接建模复杂分布;
- PixelCNN 直接对联合分布做条件分解。
这两条路线在后面的生成模型发展中一直都在反复出现。很多后来的模型,实际上都可以看作是在重新回答这两个问题:
- 是先构造潜空间,再生成数据?
- 还是直接把联合分布拆开来建模?
参考资料
- MIT 6.S978 Deep Generative Models, Course Schedule
- MIT 6.S978 Deep Generative Models,
lec3_ar.pdf - Aaron van den Oord, Nal Kalchbrenner, Koray Kavukcuoglu, Pixel Recurrent Neural Networks
- Aaron van den Oord et al., WaveNet: A Generative Model for Raw Audio