在上一篇 Diffusion 文章里,生成过程被理解为“从噪声出发,逐步沿着逆过程回到数据”。Flow Matching 可以看作对这条思路的一次重新组织:
与其学习一个带随机性的逆扩散过程,不如直接学习一条把源分布推到目标分布的连续速度场。
这类方法的重要性在于,它把扩散模型中的许多直觉重新表达成了更干净的连续时间语言:
- 不再强调一步步的随机去噪;
- 而是强调一条随时间变化的概率路径;
- 以及产生这条路径的向量场或速度场。
一个二维高斯例子足以把这条路线的直觉建立起来。
1. 为什么在 Diffusion 之后会出现 Flow Matching
Diffusion 模型已经很强,但它有一个结构上的特点:训练目标虽然最后简化成噪声的 L2 回归,推断过程仍然来自一个带随机性的逆过程近似。哪怕后来可以用 probability flow ODE 来写,它的叙述中心依然是“加噪再去噪”。
Flow Matching 的出发点则更直接:
- 给定一个简单源分布 ,例如标准高斯;
- 再给定目标数据分布 ;
- 构造一族随时间变化的中间分布 ;
- 直接学习一个速度场 ,使粒子沿这个速度场从 流动到 。
因此,Flow Matching 不是否定 Diffusion,而是在一个更一般的连续动力学框架里重新表述“如何从简单分布走到数据分布”。
2. 核心对象不再是逆扩散,而是概率路径
Flow Matching 的第一个关键概念是 probability path。它描述的不是单个样本如何被噪声腐蚀,而是整体分布如何随时间从 演化到 。
最常见的做法,是先定义一个条件概率路径 ,然后由它诱导出总体边缘分布 。
一种常见实现会把这条路径写成一类高斯路径:
class ConditionalFlowMatcher:
def __init__(self, sigma = 0.0):
self.sigma = sigma
def compute_mu_t(self, x0, x1, t):
t_pad = pad_t_like_x(t, x1)
return t_pad * x1
def compute_sigma_t(self, t):
return 1 - (1 - self.sigma) * t这表示:
- 均值随着时间从接近源端逐渐移动到目标样本 ;
- 方差随着时间逐渐收缩;
- 当 时,路径集中到目标分布附近。
从直觉上看,这条路径既保留了起点的随机性,又让整体流动朝着目标分布靠近。
3. 条件流和边缘流不是一回事
Flow Matching 中最容易混淆的一点,是 conditional flow 和 marginal flow 的区别。
- conditional flow:给定一对端点 时,某个中间样本应该朝哪个方向移动;
- marginal flow:在只知道当前点 属于整体边缘分布 的情况下,平均意义上的速度方向是什么。
一个二维例子足以把这件事展示清楚。
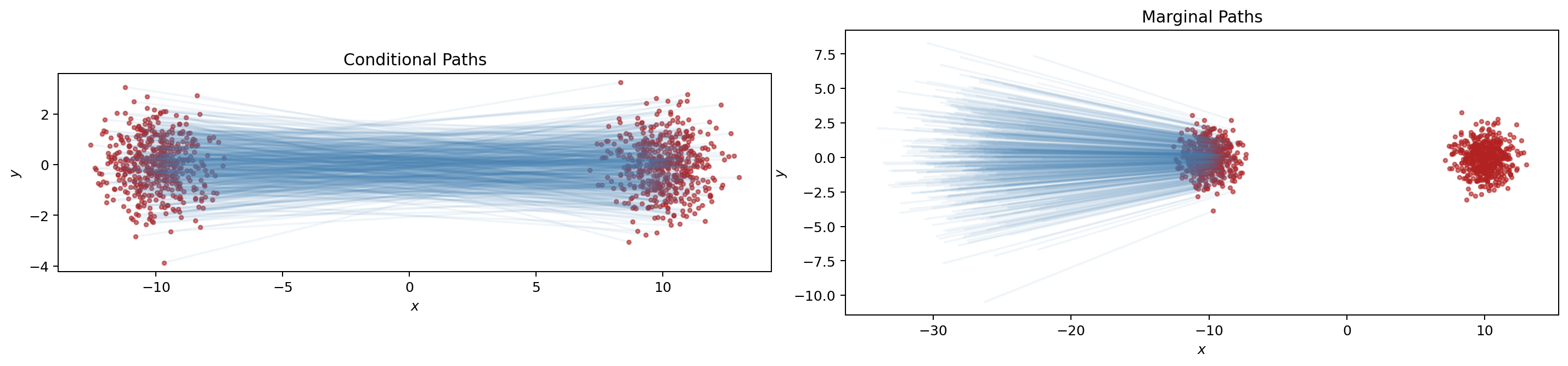
图:根据二维高斯示例重绘。左图是条件路径,每条轨迹都连接一对具体的起点和终点;右图是边缘视角下的整体流动,强调的是总体分布的演化。
这张图很重要,因为它解释了 Flow Matching 的训练为什么可行:
- 训练时并不需要直接知道真实的 marginal flow;
- 只需要从条件路径中构造出可监督的条件速度;
- 再通过期望把它提升到边缘分布意义下的速度场学习。
4. 训练目标:回归速度场,而不是回归噪声
Diffusion 的训练目标通常是预测噪声 。而 Flow Matching 的训练目标则更接近:
其中:
- 是构造出来的条件流;
- 是网络预测的速度场。
常见实现正是这种形式:
def compute_conditional_flow(self, x0, x1, t, xt):
t_pad = pad_t_like_x(t, x1)
return (x1 - (1 - self.sigma) * xt) / (1 - (1 - self.sigma) * t_pad)
...
t, xt, ut = FM.sample_location_and_conditional_flow(x0, x1)
vt = model(xt, t)
loss = torch.mean((vt - ut) ** 2)这段代码可以直接对应到理论:
xt是在时间 采样到的中间状态;ut是已知的条件速度;vt是模型预测的速度;- 训练就是让网络逼近这条条件速度场。
这和 DDPM 非常不一样。DDPM 最后回归的是噪声,而 Flow Matching 直接回归动力学里的速度。
5. 为什么这种训练更“直接”
Flow Matching 之所以让很多人觉得更清晰,原因在于它省掉了扩散推导里一部分中间结构。
在 Diffusion 中,通常要经过这些步骤:
- 先定义前向加噪过程;
- 再讨论逆过程的参数化;
- 再从 KL 推到噪声回归;
- 再从离散时间走向连续时间。
而在 Flow Matching 中,叙述可以更直接:
- 先定义一条源分布到目标分布的概率路径;
- 再写出对应的条件速度;
- 最后直接回归这个速度场。
这也是它名字的来历。它不是先去学一个隐含的生成器,而是显式地去 match 一条 flow。
6. 代码中,Flow Matching 的关键思想体现在哪里
下面几段代码对应了四个最关键的部分。
6.1 中间状态是沿概率路径采样出来的
def sample_xt(self, x0, x1, t, epsilon):
mu_t = self.compute_mu_t(x0, x1, t)
sigma_t = pad_t_like_x(self.compute_sigma_t(t), x1)
return mu_t + sigma_t * epsilon这一步和 Diffusion 的前向闭式采样很像,但语义不同:
- 在 Diffusion 里, 来自预设的加噪过程;
- 在 Flow Matching 里, 来自一条人为构造的条件概率路径。
换句话说,这里采样的不是“被腐蚀后的数据”,而是“流动路径上的中间状态”。
6.2 训练监督来自条件速度
def sample_location_and_conditional_flow(self, x0, x1, t=None, return_noise=False):
if t is None:
t = torch.rand(x0.shape[0]).type_as(x0)
eps = self.sample_noise_like(x0)
xt = self.sample_xt(x0, x1, t, eps)
ut = self.compute_conditional_flow(x0, x1, t, xt)
return t, xt, ut这段代码说明 Flow Matching 的监督信号并不是通过一个复杂的变分目标间接得到的,而是由设计好的条件路径直接给出。
这也是为什么很多人会觉得它在概念上比 Diffusion 更简洁。
6.3 神经网络学习的是时间相关的向量场
t, xt, ut = FM.sample_location_and_conditional_flow(x0, x1)
vt = model(xt, t)
loss = torch.mean((vt - ut) ** 2)这里的 model(xt, t) 输出的不是一个类别标签、不是一个重建图像、也不是噪声本身,而是当前点在时间 上应该沿着哪个方向继续移动。
这意味着网络所学到的是一个 time-dependent vector field。
6.4 推断阶段由 ODE 积分器完成
traj = torchdiffeq.odeint(
lambda t, x: model.forward(x, t),
torch.randn(100, 1, 28, 28, device=device),
torch.linspace(0, 1, 2, device=device),
atol=1e-4,
rtol=1e-4,
method="dopri5",
)这段代码是 Flow Matching 和 DDPM 差异最直观的地方之一:
- DDPM 通常用离散时间采样链一步一步更新;
- Flow Matching 则更自然地写成一个 ODE 初值问题。
生成时,从源分布采样一个初值,再把学到的速度场送进 ODE 求解器,就能把样本推到数据分布附近。
7. 它和 Continuous Normalizing Flow 是什么关系
Flow Matching 和 Continuous Normalizing Flow, CNF 的关系非常近。二者都在学习一个连续时间向量场,并通过 ODE 把简单分布运输到目标分布。
它们的差别更多体现在训练方式:
- 经典 CNF 更强调精确的 log-likelihood 与雅可比迹积分;
- Flow Matching 更强调利用构造好的概率路径,直接监督向量场。
因此,可以把 Flow Matching 看成一条更面向生成任务、也更贴近现代深度学习训练方式的连续流路线。
8. 它和 Diffusion 的关系到底是什么
从更高层看,Diffusion 和 Flow Matching 都在学习“如何把简单分布变成数据分布”。差别主要在于:
- Diffusion 更常从随机过程和去噪视角组织问题;
- Flow Matching 更常从连续流和速度场视角组织问题。
二者并不是互相排斥的。实际上,很多最新工作都在用统一框架来理解它们:扩散模型可以对应某类随机路径,而 Flow Matching 则对应某类确定性或近确定性的概率流。
这也是为什么在理解完 Diffusion 之后再看 Flow Matching,会显得非常自然。
9. 为什么这类方法值得特别重视
Flow Matching 的重要性主要体现在三个方面。
第一,它提供了比“加噪再去噪”更直接的连续时间叙述。
第二,它把训练目标简化成对速度场的监督回归。
第三,它天然适合和 ODE/SDE、optimal transport、continuous flow 等理论联系起来。
从写博客和建立知识地图的角度看,它非常适合放在 Diffusion 和 Consistency Model 之间。因为:
- 它保留了连续时间视角;
- 又比传统 Diffusion 更像“直接学习一条生成轨迹”;
- 后面的 Consistency Model 可以看作在另一个方向上进一步追求更少采样步数。
参考资料
- Yaron Lipman et al., Flow Matching for Generative Modeling
- Cambridge MLG, Flow Matching Guide and Code