基于学习的机器人学其实本质上是一个生成式的过程,所以自然语言处理和计算机视觉中的一些模型可以用来生成动作序列和策略。

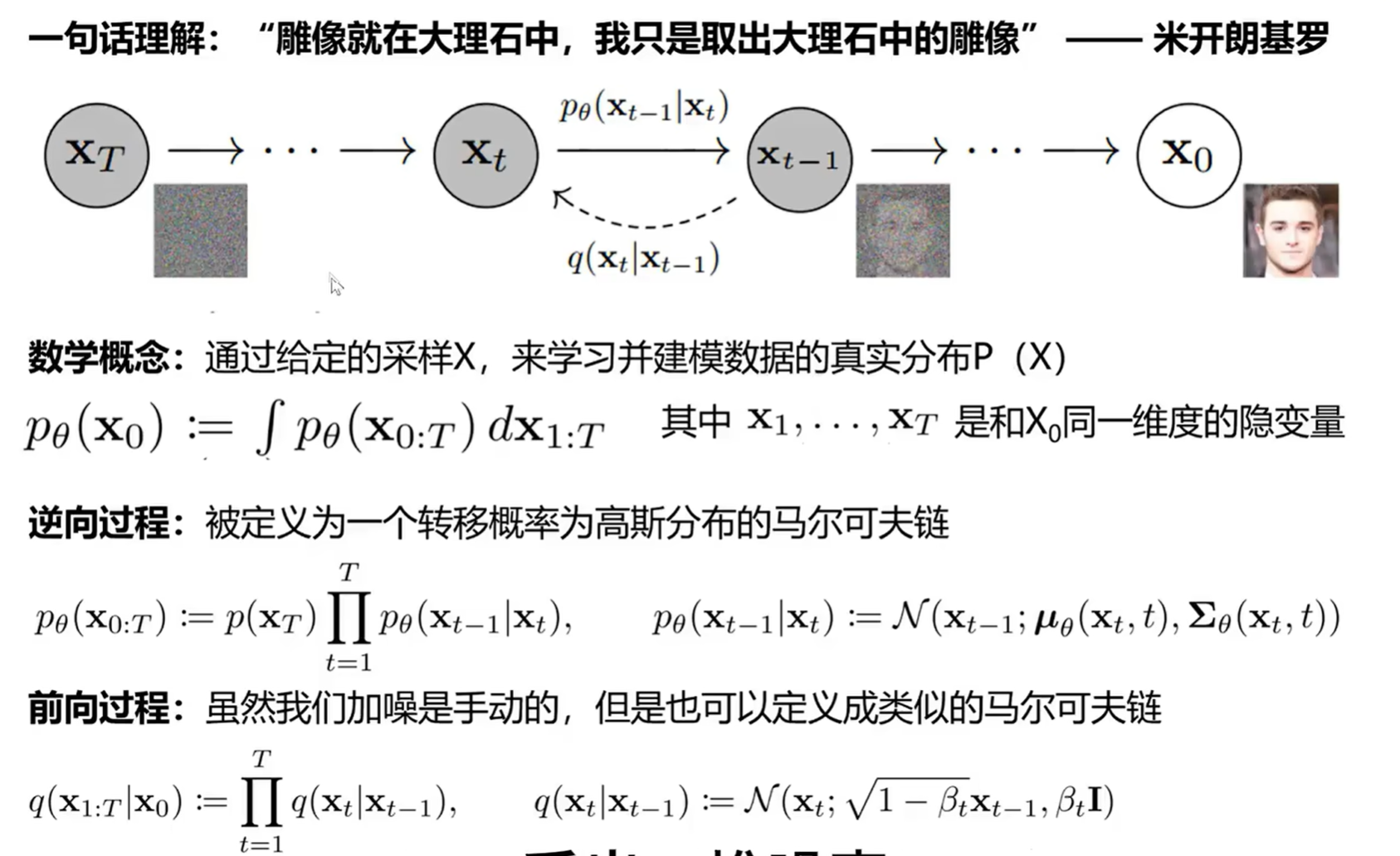
DDPM
使用的模型是 DDPM (Denoising Diffusion Probabilistic Models):
通过加噪再去噪的过程,训练完成之后就可以直接采样噪声,然后训练好的 decoder 根据一些 condition 就可以还原出原来的 。加噪和去噪的转移概率如下:
KL 散度概念回顾
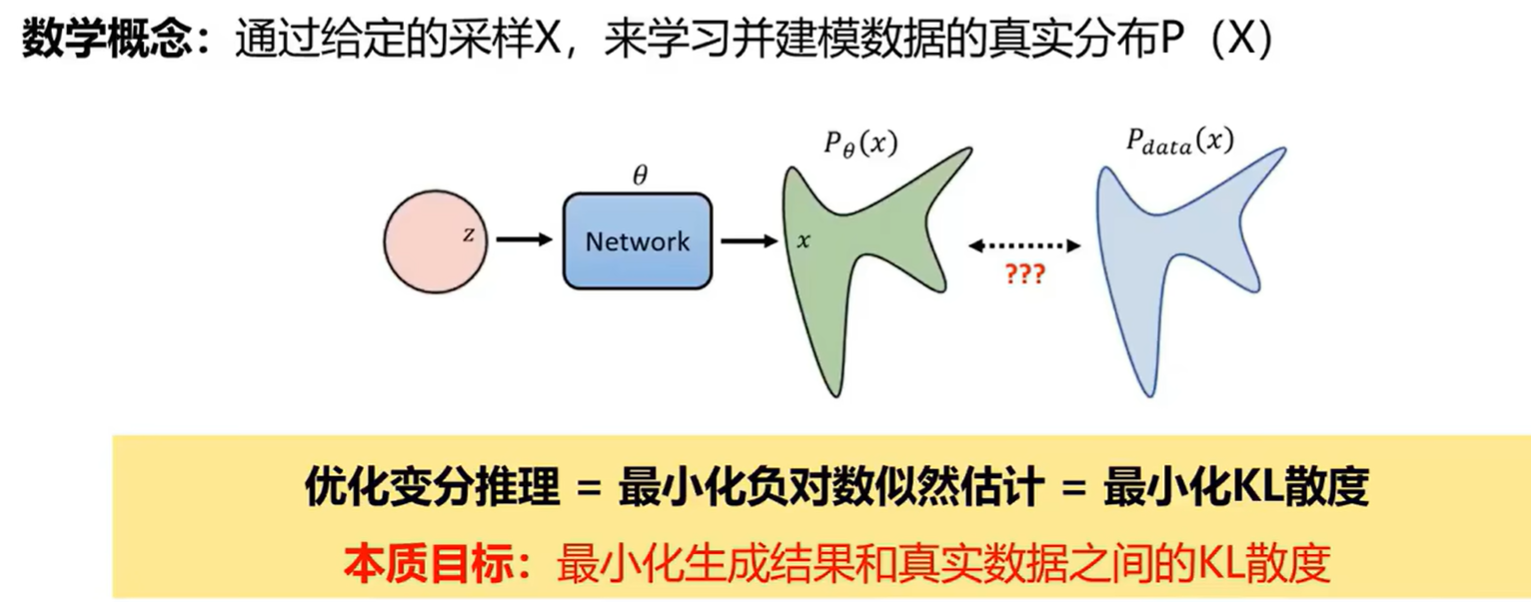
补充一下之前一直有的一个概念,什么是 KL 散度。KL 散度,也常被称为相对熵(Relative Entropy),是信息论和概率论中一个重要的概念。它用于衡量两个概率分布之间的差异性。
衡量当你用你的模型 来近似真实分布 时,所造成的信息损失(Information Loss)有多少。
- KL 散度值越小,意味着分布 与真实分布 越接近,模型 对真实情况的拟合就越好。
- KL 散度值越大,意味着两者差异越大,信息损失越多。
- 如果 KL 散度为 0,则意味着两个分布完全相同()。
这里给出公式:

DDPM 的优化目标
回到 DDPM,它的目标是通过负对数似然估计来优化变分推理界:
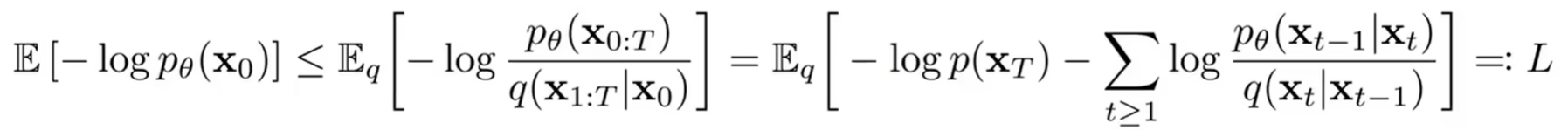
求解过程:

转换一下其实就是求 和我训练 network 得到的 的最小化 KL 散度:
(如果感兴趣可以去看看变分推理,边缘分布里面有引入了证据下界来估计一些观测数据的对数似然的下限。)
加噪过程的优化
在论文里面的加噪过程不是说在上一个时刻的基础上加噪,而是在原图的基础上,每一次按照手动设置的比例直接加上去:

来源于这里:
闭合性(Closure Property)
两个高斯分布的和(或线性组合)仍然是一个高斯分布。这就是”闭合性”。
我们的前向过程是不断地累加高斯噪声。第一步是 + 高斯噪声,第二步是在此基础上再加高斯噪声…
利用高斯分布的闭合性,我们可以推导出一个**“一步到位”的公式**,直接从原始图像 计算出任意时刻 的噪声图像 ,而无需真的去迭代 次。
对应的数学公式:
- 这就是那个”一步到位”的公式。它告诉我们,任意时刻 的噪声图像 ,其分布等价于对原始图像 乘以一个系数 ,再加上一个均值为0、方差为 的高斯噪声。
- 这里的 是由每一步的噪声水平 (通过 ) 累乘得到的,它代表了从开始到 时刻信号的衰减程度。
- 有了这个闭合性带来的公式,我们可以在 的时间内,瞬间得到任意 时刻的 ,极大地提高了训练效率。
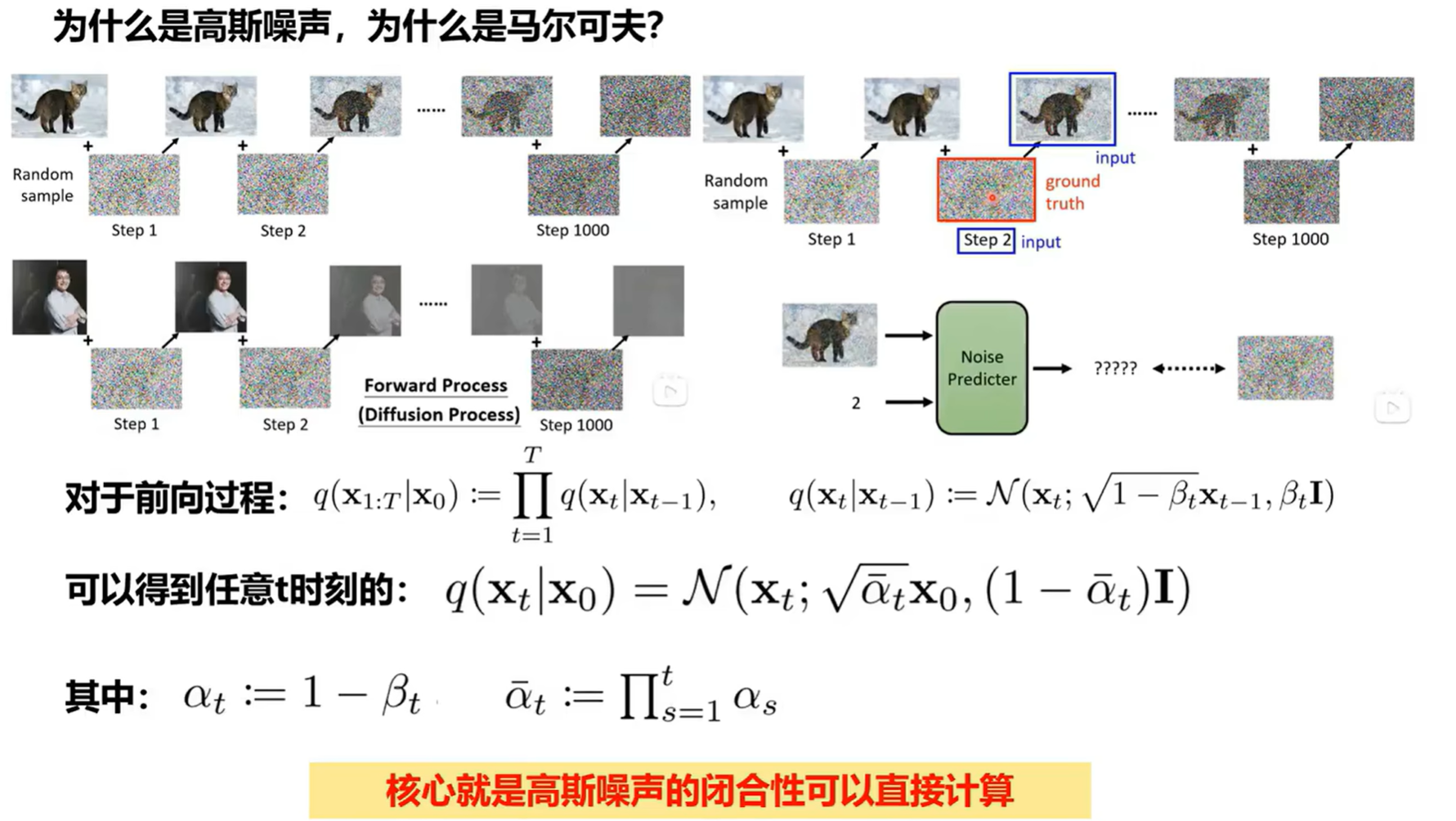

让网络去学习噪声(学习起来是更加简单的相比图像):
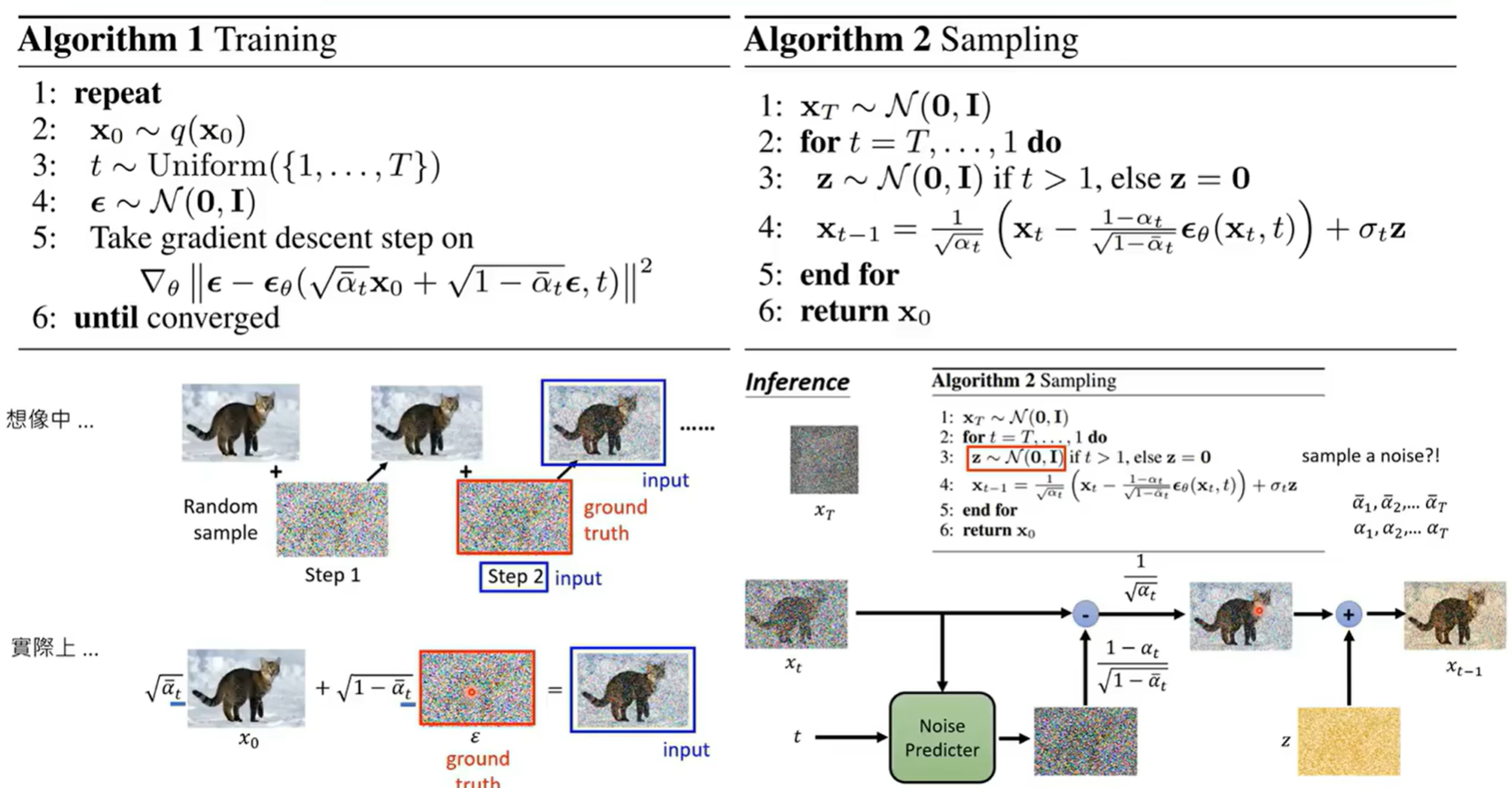
详细数学讲解可以参看这篇博客What are Diffusion Models? | Lil’Log
关于 Diffusion Policy
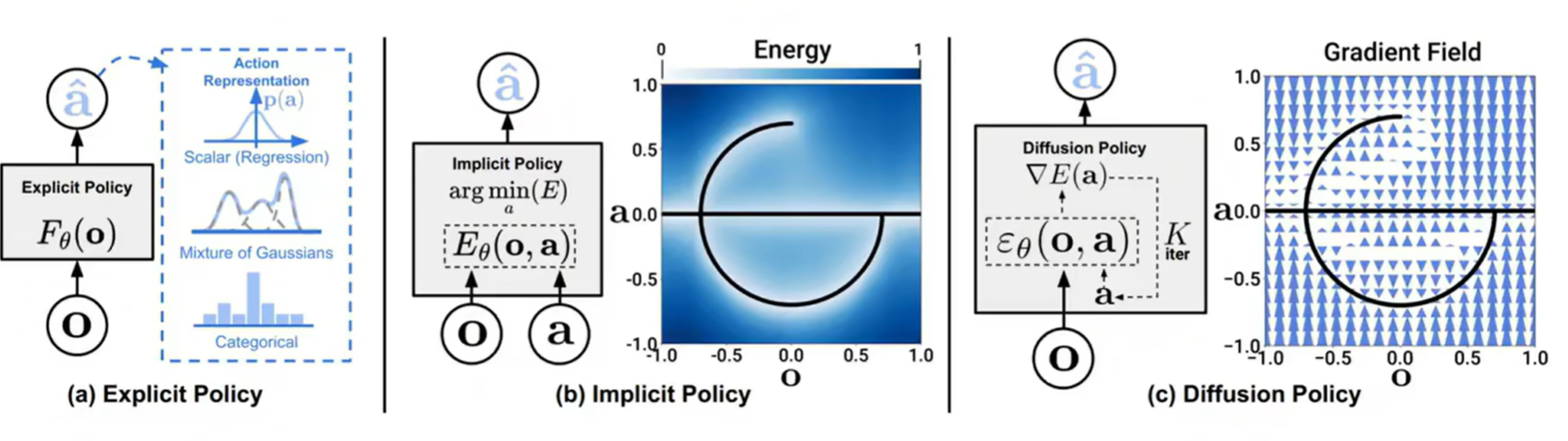
在模仿学习(IL)的工作里面,有三种主流的思想:显式策略 (Explicit Policy)、隐式策略 (Implicit Policy) 和 扩散策略 (Diffusion Policy)
① 显式策略 (Explicit Policy)
多模态失效问题
-
核心思想:试图学习一个直接的函数,这个函数的输入是当前的观察 ,输出就是应该执行的动作 。就像一个简单的”如果看到这个(输入),就做那个(输出)“的规则。
-
输出 (action) 可以是两种形式:
- 标量回归 (Scalar Regression):如果动作是连续的(比如机器臂要移动到的某个具体坐标),模型会直接预测这个数值。
- 分类 (Categorical) 或 高斯混合模型 (Mixture of Gaussans):如果动作是离散的(比如”前进”、“左转”),或者动作的可能性有多个”甜点区”(多峰性),模型会输出一个概率分布,来表示每个动作的好坏或可能性。
-
缺点:
- 精度很差:直接映射通常难以精确地拟合复杂、高维度的动作。
- 解决不了多峰性问题:当一个好的决策有多种同样可行的选择时(例如,开门时可以顺时针也可以逆时针转动门把手),简单的直接映射模型很难学习到这种多模态的分布,往往只会输出所有可能性的一个平均值,而这个平均值动作可能是无效的。

② 隐式策略 (Implicit Policy)
-
核心思想:不直接告诉你”该做什么动作”,而是学习一个”评价函数”或”能量函数” 。这个函数会根据当前的观察 ,给每一个可能的动作 打分。分数越低(能量越低),代表这个动作越好。因此,决策过程就变成了在所有可能的动作中,寻找那个能让能量函数 最小化的动作。
-
缺点:
- 解决不了负采样的问题:为了学习这个能量函数,模型需要知道哪些是”好”的动作(正样本),哪些是”坏”的动作(负样本)。在复杂的动作空间中,如何有效地采集到足够多且有代表性的”坏”动作(负样本)是一个非常棘手且影响模型性能的关键问题。
③ 扩散策略 (Diffusion Policy)
- 核心思想:借鉴了热力学中扩散过程的思想。它不直接生成动作,也不学习能量函数,而是学习一个能够引导动作生成的”梯度场” 。
这里的condition变成了摄像头的观测来做去噪:
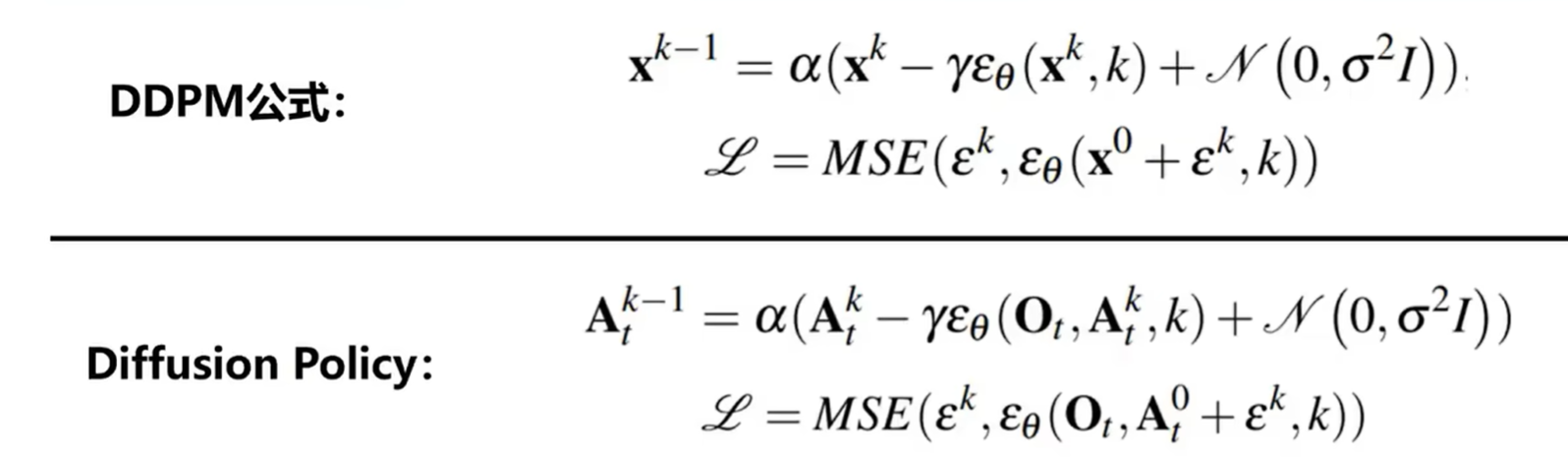
- 将视觉观测作为”条件”输入而非”被去噪的对象”,而不是与动作一起作为联合分布的一部分来建模。在整个去噪迭代过程中,视觉特征只需要提取一次,极大地降低了计算量,为实时推理提供了可能。
在每一次需要生成动作时,视觉编码器(如 ResNet)会先处理一次输入的图像,将其转换成一个紧凑的特征向量 。然后,在后续的几十步甚至上百步的迭代去噪过程中,这个固定的特征向量 会在每一步都被用作”条件”输入到噪声预测网络中,指导噪声的去除方向。
如果把视觉信息和动作混在一起作为被去噪的对象,那么每一步去噪都需要重新编码图像,这将导致无法接受的计算延迟,使其无法用于实时控制。
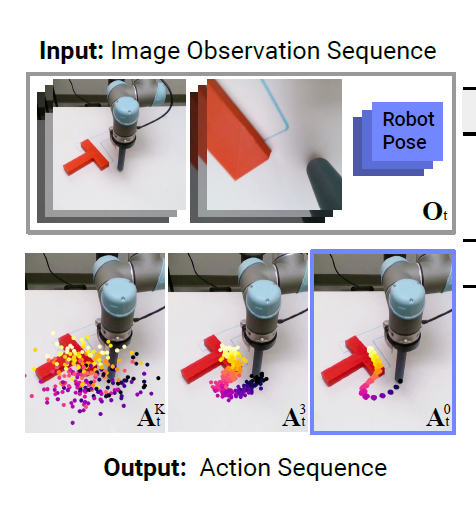
技术实现细节
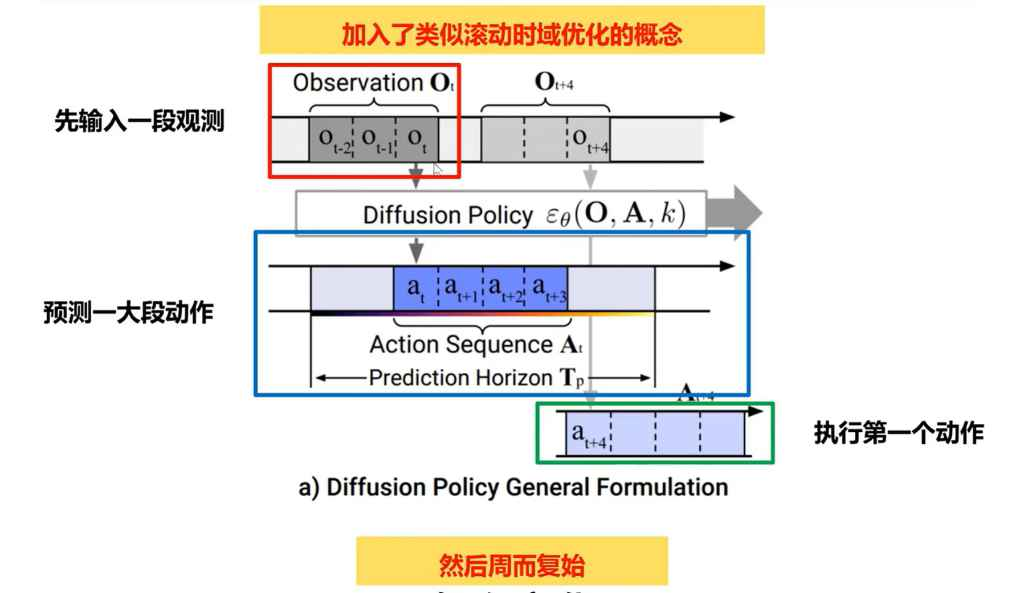
闭环动作序列与滚动时域控制
滚动时域控制 (Receding Horizon Control):
策略会预测未来 步的动作序列,但只执行其中的前 步,然后根据最新的观测重新规划。预测长序列,执行短序列,不断循环。
- 预测时域 (Prediction Horizon )
- 执行时域 (Action Execution Horizon )
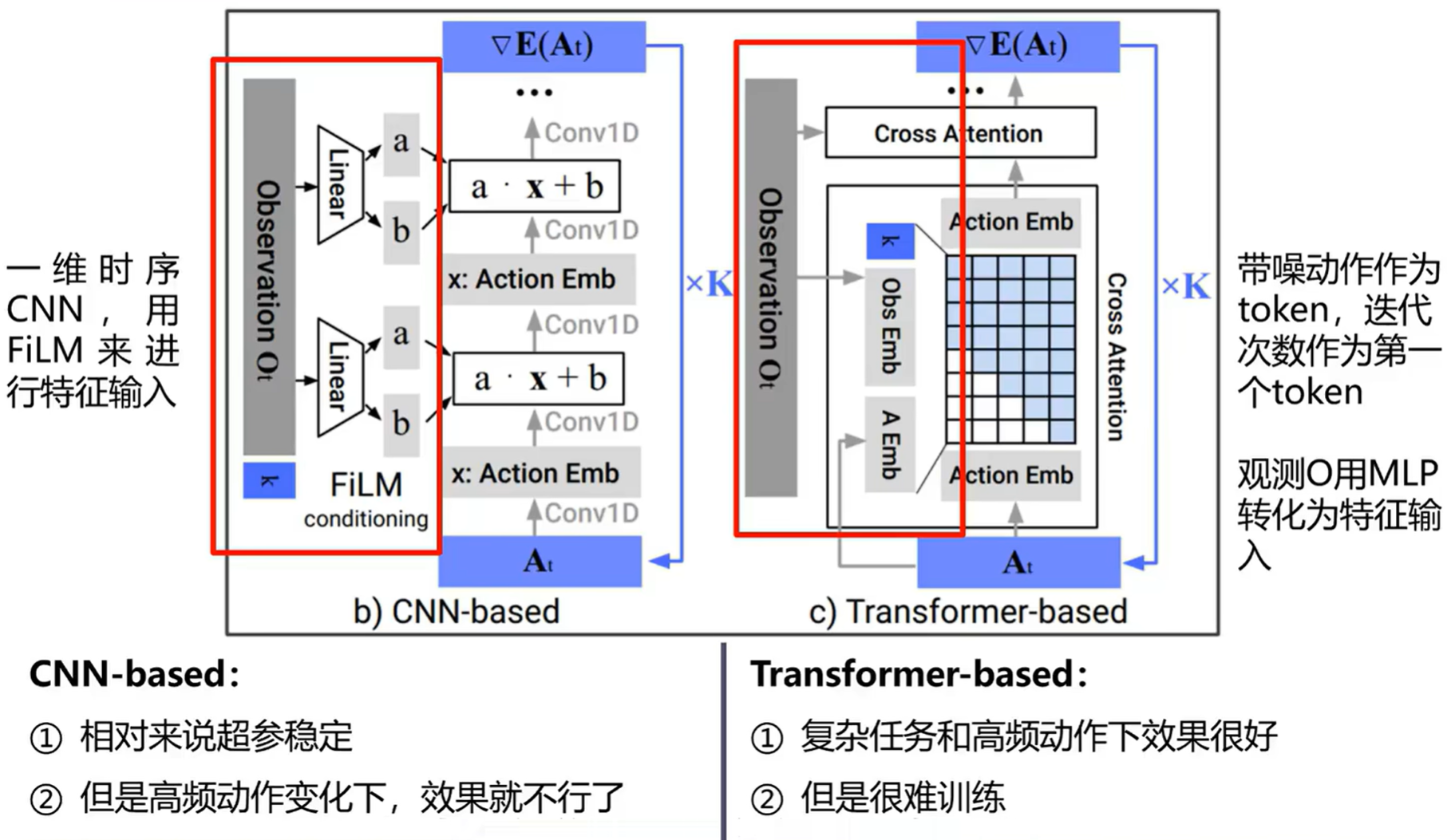
网络架构
网络架构选择:
-
CNN-based:通常作为首选,工作良好且无需过多调参。但在需要高频动作变化的任务上可能因卷积的平滑效应而表现不佳。使用 1D 时间卷积网络,同时用 FiLM 逐特征线性调制来用视觉信息指导去噪。
-
FiLM 的核心思想:提供一种机制,让来自一个信息源(例如一段文本问题)的指令,能够动态地、灵活地调整另一个神经网络(例如一个处理图像的 CNN)的内部计算过程。让 CNN 能够针对性地进行”思考”和”推理”。
-
Transformer-based:为解决 CNN 的过平滑问题而提出,尤其在任务复杂或动作变化快的场景下表现更佳,但对超参数更敏感。
控制策略优化
同时动作空间使用了位置控制取代速度控制,面对多模态问题(即同一个任务有多种正确做法)位置控制会更优。同时对”累积误差”的更强抵抗力:
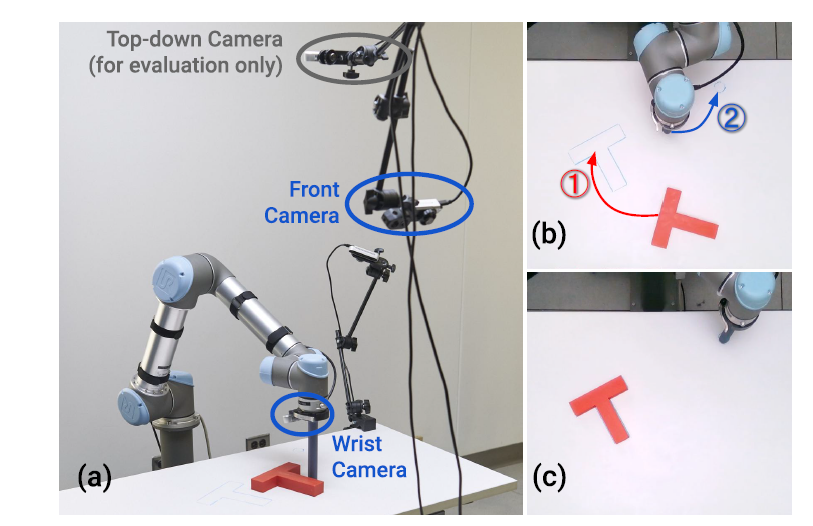
双相机设置
有两个相机,单独编码,一个用来保留深度信息,另一个用来保证训练稳定:
方法对比
不同方法的对比:(第二种是加了视觉的encoder)

训练和推理过程
训练阶段:学习如何”去噪”
训练的目标是让一个噪声预测网络 学会如何从一个带噪声的动作中,依据当前的视觉观测,准确地预测出所添加的噪声。
-
数据准备:从专家演示数据集中,随机抽取样本,每个样本包含一个真实的专家动作 和与之对应的观测 。
-
前向加噪:对真实的专家动作 进行逐步加噪。经过 个步骤,原始动作会变成一个纯粹的高斯噪声 。
-
反向学习:这是训练的核心。在任意一个加噪步骤 上,模型接收三样输入:
- 带噪声的动作
- 当前的去噪时间步
- 当前的机器人观测
-
训练目标:网络 的任务是预测出在步骤 时被加入的噪声。模型的损失函数是预测噪声和真实添加的噪声之间的均方误差 (MSE)。
通过这个过程,模型学会了在任何观测条件下,从一个混乱的、带噪声的动作中恢复出清晰、有效的专家动作的能力。
推理阶段:从噪声生成动作
在机器人需要执行任务时,它会利用训练好的去噪网络来生成一个动作。
-
初始状态:机器人获取当前观测 ,并从一个标准高斯分布中随机采样一个纯噪声向量作为初始动作 。
-
迭代去噪:模型进行 次迭代。在每一次迭代中,它将当前的(部分去噪的)动作、时间步 和观测 输入到噪声预测网络 中。
-
动作精炼:网络预测出当前动作中的噪声,然后从当前动作中减去这个预测出的噪声,从而得到一个更”干净”的动作。
-
最终输出:经过 次迭代后,最初的随机噪声被精炼成一个高质量的、符合专家行为模式的动作序列 ,机器人随后执行该动作。
参考
-
What are Diffusion Models? | Lil’Log - 扩散模型的详细数学讲解
-
Denoising Diffusion Probabilistic Models - DDPM 原始论文项目页面
-
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion - Diffusion Policy 官方项目页面
-
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion (arXiv) - 论文原文
-
【论文精读】Diffusion Policy:机器人策略学习的新范式 - B站视频讲解
-
扩散模型在机器人控制中的应用 - B站相关视频
-
Google Gemini - AI助手,协助理解和整理相关概念