MIT 6.S184 学习笔记:Diffusion 与 Flow Matching
0. A Reminder on Probability Theory
后面所有 flow matching 和 diffusion 的公式,本质上都在操作概率分布。因此先把 Appendix A 里的概率论记号放在最前面。这里不是为了完整复习概率论,而是为了固定这门课会反复使用的几个对象。
0.1 Random vectors and PDFs
课程里主要处理连续向量:
x=(x1,…,xd)∈Rd.
一个随机向量记作
X∈Rd.
如果 X 有连续概率密度函数,也就是 PDF:
pX:Rd→R≥0,
那么事件 X∈A 的概率为
P(X∈A)=∫ApX(x)dx.
概率密度必须归一化:
∫pX(x)dx=1.
如果积分区域没有特别写,默认是在整个空间 Rd 上积分。
随机变量 Xt 的 density 经常简写成
pt.
也就是说,当我们写
Xt∼pt
时,意思是 Xt 的分布密度是 pt。
0.2 Gaussian distribution
生成模型里最常见的简单分布是 isotropic Gaussian:
N(x;μ,σ2I)=(2πσ2)−2dexp(−2σ2∥x−μ∥2).
其中:
- μ∈Rd 是均值;
- σ>0 是标准差;
- σ2I 表示每个维度方差相同,且不同维度之间没有相关性。
后面 Gaussian probability path 会反复使用这个形式:
pt(x∣z)=N(x;αtz,βt2Id).
它的含义就是:在给定 clean data z 的情况下,x 是一个以 αtz 为均值、噪声尺度为 βt 的高斯随机变量。
0.3 Expectation and LOTUS
随机向量的期望是
E[X]=∫xpX(x)dx.
它也可以被理解成在 least-squares sense 下最接近随机变量 X 的常数向量:
E[X]=argz∈Rdmin∫∥x−z∥2pX(x)dx.
如果要计算随机变量函数的期望,可以直接用 density 积分:
E[f(X)]=∫f(x)pX(x)dx.
这叫 law of the unconscious statistician,简称 LOTUS。后面各种 loss 都是这种形式,例如
Et,z,ϵ[utθ(αtz+βtϵ)−(α˙tz+β˙tϵ)2].
它的意思就是:按指定方式采样 t,z,ϵ,再对括号里的函数取平均。
0.4 Joint density and marginals
如果有两个随机变量 X,Y,它们的 joint PDF 记作
pX,Y(x,y).
joint density 描述的是 (X,Y) 同时取某组值的密度。只关心其中一个变量时,需要把另一个变量积分掉:
pX(x)=∫pX,Y(x,y)dy,
pY(y)=∫pX,Y(x,y)dx.
这两个分布叫 marginals。
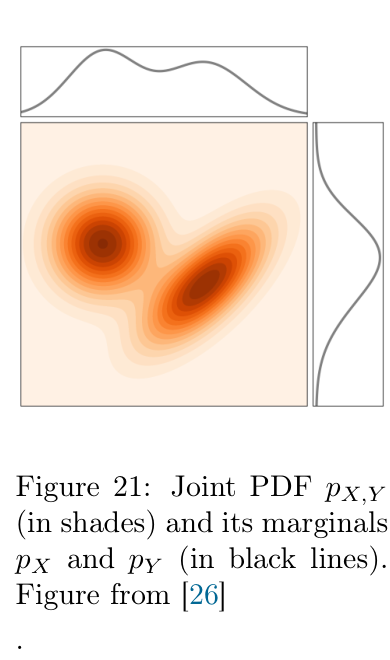
图 21 中,橙色阴影是 joint PDF:
pX,Y(x,y).
上方黑线是把 y 积掉后得到的 pX(x),右侧黑线是把 x 积掉后得到的 pY(y)。
这和 flow matching 里的 marginal path 是同一个思想。我们有联合采样:
z∼pdata,x∼pt(⋅∣z),
它对应联合密度
pt(x∣z)pdata(z).
把 z 积掉,就得到 x 的 marginal:
pt(x)=∫pt(x∣z)pdata(z)dz.
0.5 Conditional density and Bayes’ rule
conditional density 定义为
pX∣Y(x∣y)=pY(y)pX,Y(x,y),
其中要求 pY(y)>0。
它表示:在已经知道 Y=y 的情况下,X 的分布。
Bayes’ rule 把反方向的条件分布写出来:
pY∣X(y∣x)=pX(x)pX∣Y(x∣y)pY(y).
这个公式在 flow matching 和 score matching 中非常重要。比如给定 noisy sample x 后,背后的 clean data z 的 posterior 是
pt(z∣x)=pt(x)pt(x∣z)pdata(z).
这个权重反复出现在:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz,
以及
∇logpt(x)=∫∇logpt(x∣z)pt(x)pt(x∣z)pdata(z)dz.
也就是说,marginal velocity 和 marginal score 都是 conditional 对象按 posterior 权重做平均。
0.6 Conditional expectation
conditional expectation 可以先看成一个函数:
E[X∣Y=y]=∫xpX∣Y(x∣y)dx.
它表示:已知 Y=y 后,对 X 的平均估计。
如果把 y 换成随机变量 Y 本身,就得到另一个随机变量:
E[X∣Y].
这两个记号容易混:
- E[X∣Y=y] 是 y 的函数;
- E[X∣Y] 是随机变量,因为它等于把函数作用在随机变量 Y 上。
conditional expectation 还有一个 least-squares 解释:
E[X∣Y]
是所有只依赖 Y 的函数里,对 X 做均方误差预测的最优函数。这一点正是 Theorem 12 背后的统计直觉:网络只看到 noisy sample x,而 target 还依赖隐藏的 z,MSE 下最优预测就是对 z∣x 的条件平均。
0.7 Tower property
tower property 是
E[E[X∣Y]]=E[X].
意思是:先在给定 Y 的情况下对 X 取平均,再对 Y 的随机性取平均,结果等于直接对 X 取平均。
用 density 写就是
E[E[X∣Y]]=∫(∫xpX∣Y(x∣y)dx)pY(y)dy=∫xpX(x)dx.
后面只要看到“先条件平均,再整体平均”,本质上都在使用这个思想。
最后,对任意函数 f(X,Y),有
E[f(X,Y)∣Y=y]=∫f(x,y)pX∣Y(x∣y)dx.
这会帮助理解很多带条件的 loss 和 posterior average。
这一节最重要的连接是:
这门课里的 marginalization trick、score posterior average、denoiser、Theorem 12,本质上都在反复使用 joint density、marginal density、Bayes rule 和 conditional expectation。
1. Generative Modeling as Sampling
生成模型首先要解决的并不是“如何画出一张图片”,而是更抽象的问题:如何从一个分布中采样。图像、视频、分子结构看起来是不同的数据类型,但都可以统一看成某个高维空间中的向量:
z∈Rd.
例如,一张 RGB 图片可以看成 H×W×3 个数,一个视频可以看成一串图片,一个分子结构也可以用原子坐标组成的向量表示。这样一来,“生成对象”就变成了“生成一个向量”。
接下来我们需要描述什么叫“生成得好”。以生成一张狗的图片为例,并不存在唯一正确的狗图。合理的狗图有很多种,因此我们用一个概率分布来描述这些可能对象的集合。这个分布记作
pdata.
于是生成任务就被形式化为:
z∼pdata.
这句话是整个课程的起点。我们并不知道 pdata 的显式表达式;训练时真正拥有的是有限个样本:
z1,…,zN∼pdata.
也就是说,数据集只是这个未知分布的有限观察。生成模型的目标,是利用这些样本构造一个算法,使它训练后能够产生新的、近似来自 pdata 的样本。
如果加入条件,例如文本 prompt y,问题就变成条件采样:
z∼pdata(⋅∣y).
这就是 guided generation 或 conditional generation。前面先讨论 unconditional case,因为条件生成的很多方法是在无条件生成的基础上扩展出来的。

Summary 2 的中文整理
本节的结论可以概括为四点。第一,本课程主要研究可以表示成向量的对象,例如图像、视频和分子结构:
z∈Rd.
第二,生成就是从数据分布中采样:
z∼pdata.
第三,如果有条件变量 y,则目标变成:
z∼pdata(⋅∣y).
第四,我们的目标是构造一个 generative model,使它训练完成后能够返回来自 pdata 的样本,或者至少返回近似来自这个分布的样本。
到这里,生成模型的问题已经从直观任务变成了一个数学任务:给定样本,学习如何从未知数据分布中采样。
2. Flow and Diffusion Models
2.1 Flow Models: 用 ODE 搬运分布
采样算法可以通过动力系统来构造:从一个简单分布开始,让样本沿着某种运动规则演化,最后希望它们落在数据分布上。
我们先从确定性的动力系统开始,也就是 ODE。
一个轨迹是时间到空间位置的函数:
X:[0,1]→Rd,t↦Xt.
这里 Xt 表示粒子在时间 t 的位置。要规定这个粒子如何运动,我们引入向量场:
u:Rd×[0,1]→Rd,(x,t)↦ut(x).
向量场的含义是:在时间 t、位置 x,粒子的瞬时速度应该是 ut(x)。于是轨迹满足的 ODE 写成
dtdXt=ut(Xt),X0=x0.
这条公式的意思很直接:轨迹在每个时刻都沿着向量场给出的方向前进。
与 ODE 对应的 flow map 记作
ψt(x0).
它回答的问题是:如果粒子从 x0 出发,按照这个 ODE 走到时间 t,它会在哪里?因此
Xt=ψt(X0).
所以,vector field、ODE 和 flow 是同一个动力系统的三种描述方式:向量场规定局部速度,ODE 规定轨迹如何跟随这个速度,flow 则描述初始点被整体搬运到哪里。
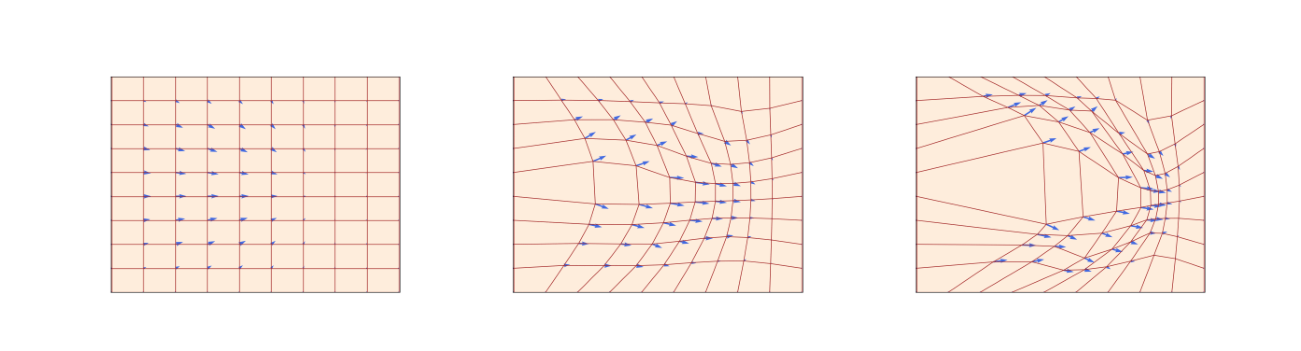
图中蓝色箭头是向量场,红色网格表示空间被 flow 扭曲后的样子。这个图很重要,因为它提醒我们:flow model 不是在单独移动一个点,而是在整体搬运空间里的概率质量。
一个简单例子是线性向量场:
ut(x)=−θx,θ>0.
对应的 ODE 为
dtdXt=−θXt,
它的 flow 是
ψt(x0)=exp(−θt)x0.
这个例子可以这样理解:点离原点越远,被拉回原点的速度越大;随着时间增加,所有点都会指数式靠近 0。后面 OU process 正是在这个稳定 drift 上加入 Brownian noise。
一般情况下,我们很难显式写出 ψt,因此需要数值模拟。最简单的是 Euler method:
Xt+h=Xt+hut(Xt).
也就是每次沿当前速度走一小步。Heun’s method 则先用 Euler 猜一步,再用当前点和预测点的速度平均来修正:
Xt+h′=Xt+hut(Xt),
Xt+h=Xt+2h(ut(Xt)+ut+h(Xt+h′)).
现在可以定义 flow model。ODE 本身是确定性的,如果初始点固定,终点也固定。但生成模型需要随机性,所以随机性放在初始条件中:
X0∼pinit.
通常取
pinit=N(0,Id).
然后用神经网络参数化向量场:
dtdXt=utθ(Xt).
我们的目标是让终点分布满足
X1∼pdata.
这里要特别注意:神经网络学习的是 utθ,也就是速度场;flow ψtθ 不是直接给出的,而是通过模拟 ODE 得到的。
2.2 Diffusion Models: 从 ODE 到 SDE
Flow model 使用确定性 ODE。Diffusion model 则把确定性轨迹推广成随机轨迹,也就是 SDE。
一个随机过程写作
(Xt)0≤t≤1.
这意味着每个 Xt 都是随机变量,而且同一个过程模拟两次,可能得到两条不同的轨迹。SDE 的随机性来自 Brownian motion,记作 Wt。可以把 Brownian motion 理解成连续时间随机游走。
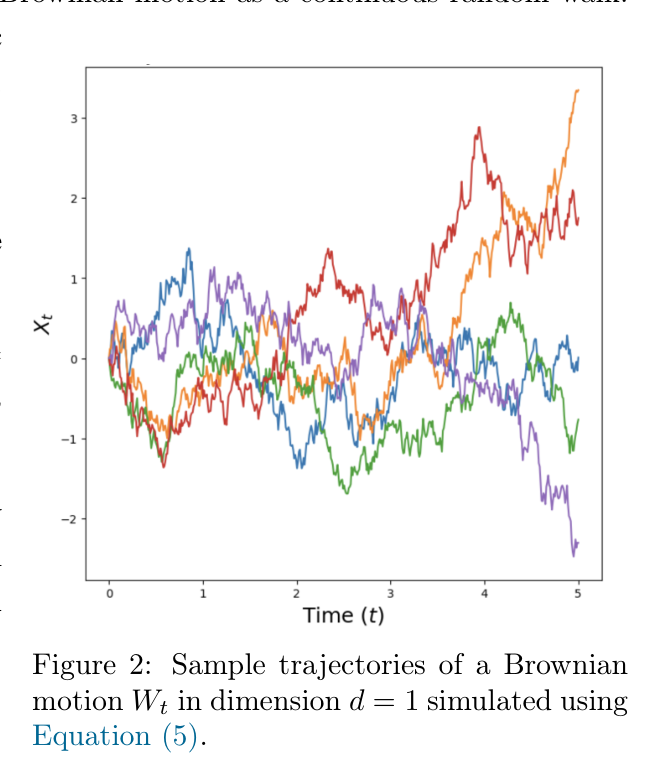
Brownian motion 有两个性质非常关键。第一是 normal increments:
Wt−Ws∼N(0,(t−s)Id),0≤s<t.
这说明它的增量均值为 0,方差随时间长度线性增长。因此在长度为 h 的小时间步内,随机扰动的尺度是 h,这就是后面 Euler-Maruyama 公式里 h 的来源。
第二是 independent increments:不重叠时间区间上的增量相互独立。直观地说,过去的随机波动不会预示未来的随机波动。
因此 Brownian motion 可以近似模拟为
Wt+h=Wt+hϵt,ϵt∼N(0,Id).
为了把随机扰动加入动力系统,我们先把 ODE 改写成小步更新形式。这样做的原因是 Brownian motion 的轨迹虽然连续,但非常粗糙,不能像普通光滑函数那样直接求导。
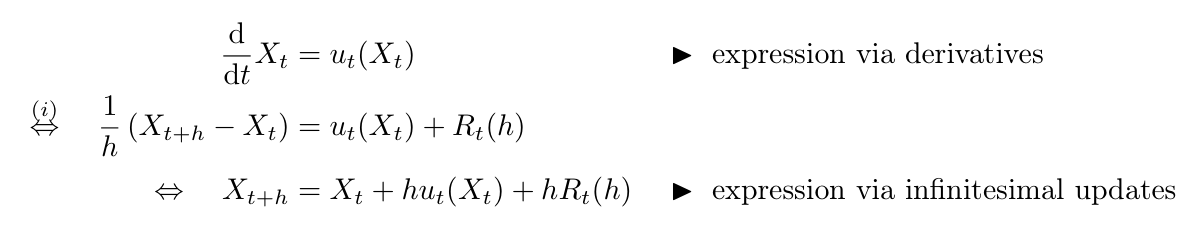
ODE
dtdXt=ut(Xt)
可以等价地理解为小步更新:
Xt+h=Xt+hut(Xt)+hRt(h),
其中当 h→0 时,Rt(h) 可以忽略。SDE 在这个小步更新中加入 Brownian motion 的随机增量:

Xt+h=Xt+hut(Xt)+σt(Wt+h−Wt)+hRt(h).
符号上通常写成
dXt=ut(Xt)dt+σtdWt.
这里 ut(Xt)dt 是 deterministic drift,σtdWt 是 stochastic diffusion,σt 是 diffusion coefficient。
Ornstein-Uhlenbeck process 是理解这类 SDE 的一个标准例子:
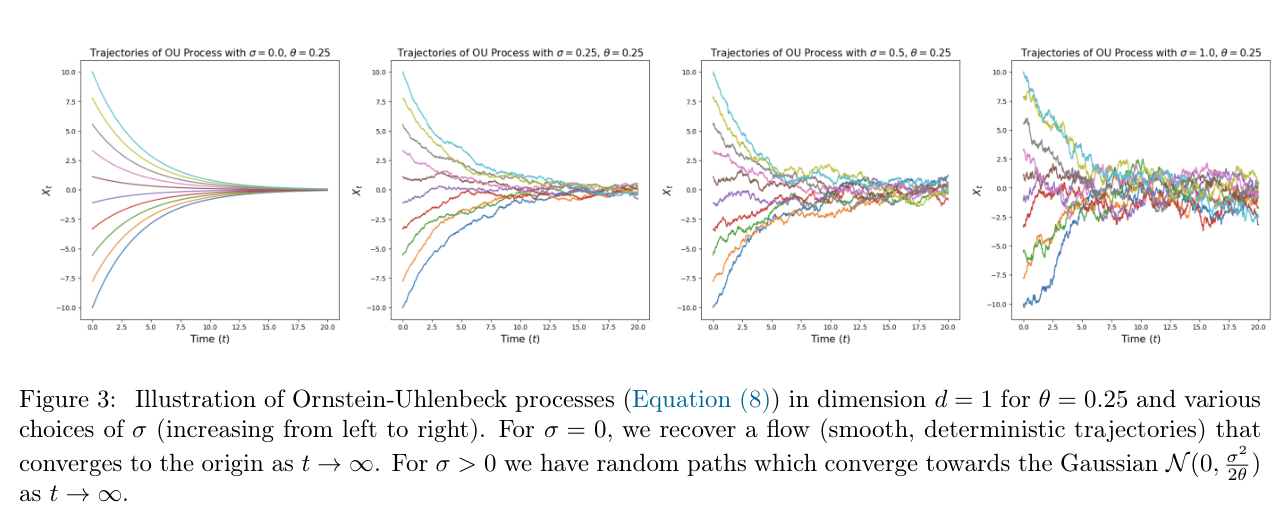

OU process 的 SDE 是
dXt=−θXtdt+σdWt.
其中 −θXtdt 把系统拉回 0,σdWt 持续注入随机性。若 σ=0,它就退化为前面学过的线性 ODE flow;若 σ>0,路径会随机抖动,但整体仍被 drift 拉回中心,并在长时间后趋向稳定高斯分布:
N(0,2θσ2).
所以 OU process 可以看成两个机制的平衡:drift 提供稳定性,noise 提供随机性。
为了模拟 SDE,我们使用 Euler-Maruyama method。由于
Wt+h−Wt∼N(0,hId),
可以写成
Wt+h−Wt=hϵt,ϵt∼N(0,Id).
代入 SDE 的小步形式,得到
Xt+h=Xt+hut(Xt)+σthϵt.
这就是 Euler-Maruyama method。

现在可以定义 diffusion model。它由一个神经网络 drift 和一个固定 diffusion coefficient 组成:
X0∼pinit,
dXt=utθ(Xt)dt+σtdWt.
其中 utθ 是要学习的向量场,σt 是预先指定的噪声强度。采样时从 pinit 出发,模拟这个 SDE 到 t=1,希望得到
X1∼pdata.

Summary 7 的中文整理
在这里,一个 diffusion model 由两部分构成。神经网络
uθ:Rd×[0,1]→Rd,(x,t)↦utθ(x),
参数化 drift / vector field;固定函数
σt:[0,1]→[0,∞)
控制随机噪声强度。生成时先采样
X0∼pinit,
再模拟
dXt=utθ(Xt)dt+σtdWt,
目标是让
X1∼pdata.
当 σt=0 时,随机项消失,diffusion model 就变成 flow model。因此 flow model 是 diffusion model 的一个特殊情况。
3. Flow Matching:从分布路径到可训练的速度场
到这里为止,我们已经知道如何用 ODE 或 SDE 定义生成模型。两者的共同目标都是
X0∼pinit,X1∼pdata.
区别在于 flow model 使用确定性 ODE:
dXt=utθ(Xt)dt,
而 diffusion model 使用带随机噪声的 SDE:
dXt=utθ(Xt)dt+σtdWt.
但这时还有一个核心问题没有回答:神经网络 utθ 应该如何训练?
Flow Matching 先把问题限制在 flow model 中,也就是先不考虑随机噪声:
X0∼pinit,dXt=utθ(Xt)dt.
我们希望训练后
X1∼pdata.
3.1 Conditional and Marginal Probability Path
现在先回到 flow model。模型从简单初始分布采样:
X0∼pinit,
然后沿着神经网络给出的速度场演化:
dXt=utθ(Xt)dt.
最后用 t=1 的位置作为生成样本。我们希望这个终点满足
X1∼pdata.
训练问题因此可以写得非常直接:怎样优化参数 θ,使得模拟这个 ODE 之后,终点分布就是数据分布?Flow Matching 的回答并不是直接处理终点,而是先安排整个中间过程。也就是说,我们不只关心
t=0andt=1,
还要指定每个中间时间
0<t<1
时,样本应该服从什么分布。
这个随时间变化的一族分布称为 probability path。它可以被理解成“分布空间中的一条轨迹”:起点是噪声分布,终点是数据分布。

图中每一列都可以理解成某个时间 t 下的样本状态。左边接近纯噪声,越往右数字结构越明显,最后得到清晰的数据样本。这里展示的是一条从噪声到数据的路径,而 Flow Matching 接下来要做的,就是学习一个速度场,让 ODE 的样本也沿着这样的路径移动。
为了更精确地定义这条路径,先固定一个数据点
z∈Rd.
用 δz 表示 Dirac delta distribution。它是最简单的一种“分布”:从 δz 采样,永远只会得到 z。因此可以把它理解成“所有概率质量都集中在数据点 z 上”。
现在定义 conditional probability path:
pt(x∣z),
它是一族关于 x 的分布,并且满足两个边界条件:
p0(⋅∣z)=pinit,
p1(⋅∣z)=δz.
这两个条件的意思是:
- 当 t=0 时,不管目标数据点 z 是什么,分布都等于初始噪声分布;
- 当 t=1 时,分布塌缩到这个具体数据点 z。
所以 conditional probability path 描述的是:如何把一个简单初始分布逐渐变成某一个固定数据点。
这里的 “conditional” 很重要。它不是直接从噪声分布变成整个 pdata,而是先问:如果目标是某个具体样本 z,那么从噪声到这个 z 的中间分布可以怎样安排?
这个构造看起来像是在“记住训练样本”,但它只是一个中间工具。下一步会把所有 z∼pdata 的 conditional paths 汇总起来,得到真正从噪声分布到数据分布的 marginal probability path。
这一页可以先记住一句话:
Flow Matching 先人为指定一条从噪声到数据的 probability path;训练速度场之前,先规定每个时间点的分布应该是什么。
Conditional path、marginal path 与 Gaussian path
固定一个数据点 z 时,conditional probability path
pt(x∣z)
描述的是从噪声分布到单个点 z 的路径:
p0(⋅∣z)=pinit,p1(⋅∣z)=δz.
但生成模型真正要学习的不是“到某一个固定点 z 的路径”,而是“到整个数据分布 pdata 的路径”。这一步通过把 z 也看成随机变量完成:
z∼pdata,x∼pt(⋅∣z).
由这个两步采样过程得到的 x 的分布,记作 pt:
z∼pdata,x∼pt(⋅∣z)⟹x∼pt.
如果写成密度,就是
pt(x)=∫pt(x∣z)pdata(z)dz.
这里有一个细节很重要:我们可以从 pt 中采样,但通常不能计算 pt(x) 的具体数值。原因是上面的积分需要对所有可能的数据点 z 做积分,而真实的 pdata 本来就是未知的。
因此:
sampling from pt is easy; evaluating pt(x) is hard.
采样很简单,因为只需要:
- 从数据集中取一个样本 z;
- 从 conditional path pt(⋅∣z) 中采一个 x。
但计算密度值
pt(x)
需要完成不可行的积分。
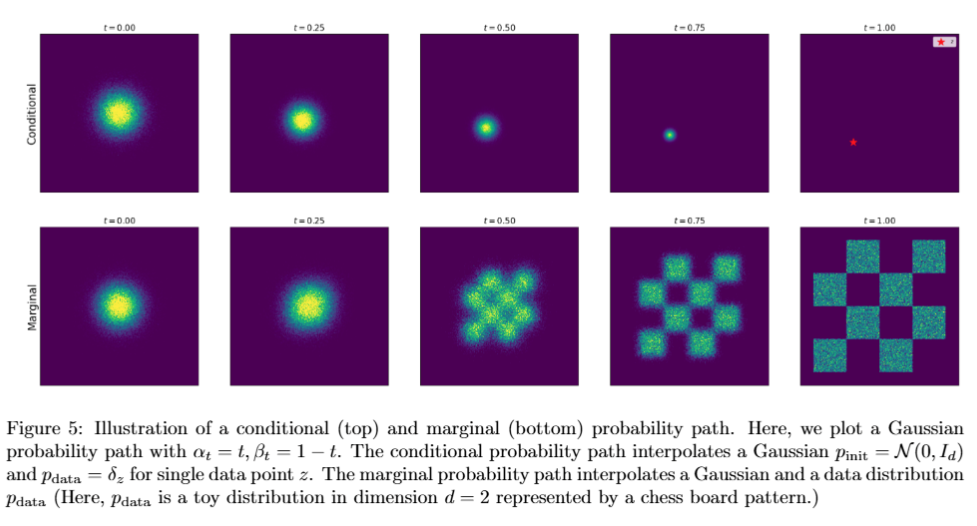
图 5 正好展示了这个区别。上排是 conditional path:目标数据点 z 固定,所以分布从高斯噪声逐渐收缩到一个点。下排是 marginal path:每次先随机选一个数据点 z∼pdata,再沿着对应的 conditional path 采样;所有这些 conditional paths 混合起来,就形成了从噪声分布到整个数据分布的路径。
由于每个 conditional path 都满足
p0(⋅∣z)=pinit,p1(⋅∣z)=δz,
因此 marginal path 自动满足
p0=pinit,p1=pdata.
这正是生成模型需要的分布级别路径。
Gaussian conditional probability path
最重要的一类 probability path 是 Gaussian path。它也是许多大规模生成模型中使用的基本形式。
先选择两个随时间变化的 scheduler:
αt, βt.
它们满足边界条件:
α0=0,α1=1,
β0=1,β1=0.
也就是说,αt 从 0 增加到 1,βt 从 1 减小到 0。然后定义
pt(⋅∣z)=N(αtz,βt2Id).
这个公式的含义很清楚:在时间 t,样本分布是一个高斯分布,它的均值是 αtz,方差尺度是 βt2。
当 t=0 时,
p0(⋅∣z)=N(α0z,β02Id)=N(0,Id)=pinit.
当 t=1 时,
p1(⋅∣z)=N(α1z,β12Id)=N(z,0)=δz.
所以 Gaussian path 正好满足 conditional probability path 的要求。
从这个分布采样也非常简单。令
ϵ∼N(0,Id),
则
xt=αtz+βtϵ
满足
xt∼pt(⋅∣z).
这个公式以后会反复出现。它是 diffusion 和 flow matching 训练中最基本的“加噪”形式:用 αt 保留数据,用 βt 注入噪声。
一个最简单的选择是
αt=t,βt=1−t.
于是
xt=tz+(1−t)ϵ.
这时 xt 就是数据 z 和噪声 ϵ 的线性插值:t=0 时是纯噪声,t=1 时是纯数据。
这一页的重点可以概括为:
Conditional path 连接噪声和单个数据点;marginal path 把所有 conditional paths 按 z∼pdata 混合起来,因此连接噪声分布和整个数据分布。
3.2 Conditional and Marginal Vector Fields
Gaussian path 给出了一个非常方便的采样公式:
z∼pdata,ϵ∼N(0,Id),
xt=αtz+βtϵ.
于是
xt∼pt.
这里 pt 是 marginal probability path。直观上,t 越小,βt 越大,样本里噪声成分越多;t 越接近 1,αt 越大,样本越接近真实数据。
到这里,probability path 只规定了一个愿望:
Xt∼pt.
也就是说,我们希望 ODE 的粒子在每个时间 t 的分布等于 pt。但是仅仅指定分布路径还不够,因为生成时真正要模拟的是 ODE:
dtdXt=ut(Xt).
因此新的问题变成:
能不能找到一个速度场 ut,使得沿着这个 ODE 运动的样本,在每个时间 t 都服从我们指定的 pt?
Flow Matching 的核心就是构造这样的速度场。
先固定一个数据点 z。如果存在一个 conditional vector field
uttarget(x∣z),
使得
X0∼pinit,dtdXt=uttarget(Xt∣z)
能够推出
Xt∼pt(⋅∣z),0≤t≤1,
那么这个 uttarget(x∣z) 就是 conditional vector field。它的作用是把初始噪声分布按照指定的 conditional path 推到某个固定的数据点 z。
乍看起来,这个对象似乎没有什么生成意义。因为如果 z 固定,那么所有终点都会塌缩到
X1=z.
这只是“生成已知样本 z”,不是从 pdata 中生成新样本。但它的价值在于:conditional vector field 是构造 marginal vector field 的 building block。
Theorem 9: Marginalization Trick
如果已经有 conditional vector field
uttarget(x∣z),
那么可以定义 marginal vector field:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz.
这个公式看起来复杂,但它其实就是一个条件期望:
uttarget(x)=E[uttarget(x∣z)∣xt=x].
其中
pt(x)pt(x∣z)pdata(z)
就是在给定当前 noisy sample x 的情况下,数据点 z 的 posterior 权重。换句话说:如果当前看到的是 x,那么不同的 z 都可能是它背后的 clean data,公式会按照这些可能性给对应的 conditional velocity 加权平均。
定理说,用这个 marginal vector field 模拟 ODE:
X0∼pinit,dtdXt=uttarget(Xt),
就会得到
Xt∼pt,0≤t≤1.
特别地,
X1∼pdata.
所以 uttarget(x) 才是真正意义上的生成速度场:它把噪声分布推到整个数据分布。
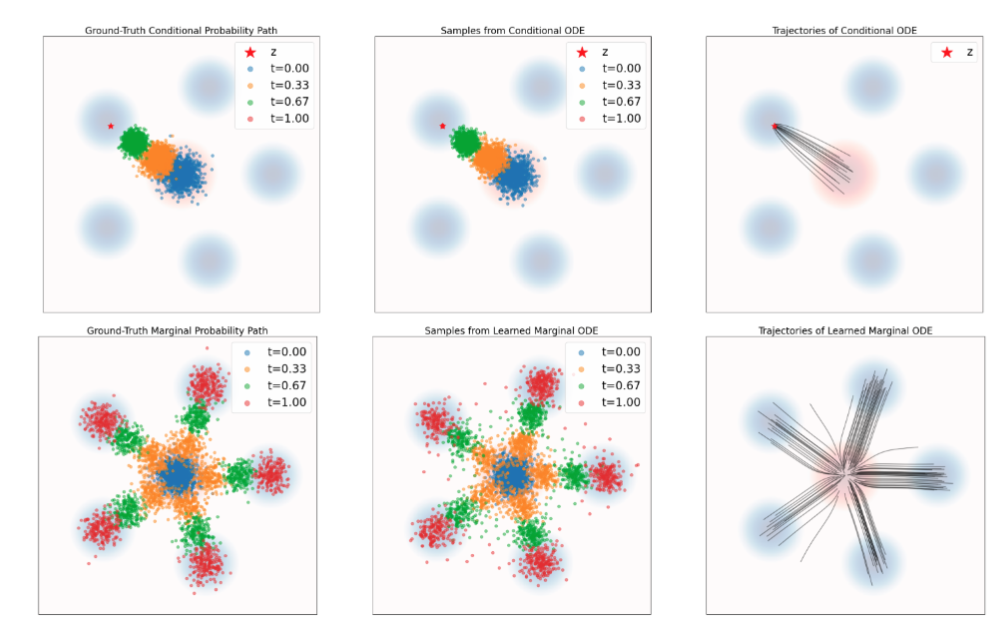
图 6 展示了这个定理的含义。上排固定一个数据点 z,conditional vector field 让样本沿着 conditional path 走,最后收缩到这个点。下排把所有 z 的影响混合起来,marginal vector field 让样本分布沿着 marginal path 演化,最后形成整个数据分布。
这一页非常关键,因为它解释了 Flow Matching 的基本策略:
- 先构造容易写出来的 conditional vector field;
- 理论上存在一个 posterior average 后的 marginal vector field;
- 真正生成时需要的是 marginal vector field;
- 后面训练神经网络时,会用 conditional vector field 作为可计算 target,却学到 marginal vector field。
最后一句是之后 Theorem 12 的核心,也是 Flow Matching 为什么能训练的根本原因。
Gaussian path 的 conditional velocity
现在要把 Gaussian conditional path 的速度场算出来。我们已经定义了:
pt(⋅∣z)=N(αtz,βt2Id).
等价地,从这个 path 采样可以写成
Xt=αtz+βtX0,X0∼N(0,Id).
这已经暗示了一个自然的 flow:
ψttarget(x∣z)=αtz+βtx.
如果初始点是 x,那么时间 t 的位置就是 αtz+βtx。当 x 本身来自标准高斯时,
Xt=ψttarget(X0∣z)=αtz+βtX0∼N(αtz,βt2Id).
这就说明这个 flow 的样本分布正好等于我们指定的 conditional probability path。
接下来从 flow 中提取 vector field。按定义,flow 和 vector field 满足:
dtdψttarget(x∣z)=uttarget(ψttarget(x∣z)∣z).
左边直接对时间求导:
dtd(αtz+βtx)=α˙tz+β˙tx.
因此
uttarget(αtz+βtx∣z)=α˙tz+β˙tx.
现在要把右边的初始噪声变量 x 换成当前位置。设当前位置为
y=αtz+βtx.
则
x=βty−αtz.
代回去:
uttarget(y∣z)=α˙tz+β˙tβty−αtz.
整理得到
uttarget(y∣z)=(α˙t−βtβ˙tαt)z+βtβ˙ty.
把当前位置重新记成 x,就得到:
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx.
这个公式可以这样理解:速度由两部分组成。一部分依赖目标数据点 z,负责把样本往目标方向拉;另一部分依赖当前位置 x,负责处理当前噪声尺度随时间缩小的影响。
如果使用最简单的 CondOT path:
αt=t,βt=1−t,
那么
xt=tz+(1−t)ϵ.
把这个选择代入一般公式,先得到的是“当前位置 x 处的速度场”:
α˙t=1,β˙t=−1.
因此
uttarget(x∣z)=(1−1−t−1t)z−1−t1x=1−tz−x.
这个式子里的 x 是任意当前位置。若当前位置正好位于 Gaussian path 上,
x=xt=tz+(1−t)ϵ,
则
uttarget(xt∣z)=1−tz−(tz+(1−t)ϵ)=z−ϵ.
这和直接对路径
xt=tz+(1−t)ϵ
求导得到的结果一致:
dtdxt=z−ϵ.
所以这个特殊情况下,conditional vector field 在训练样本 xt 处的 target 会变得非常简单:
uttarget(xt∣z)=z−ϵ.
这也是后面 Algorithm 3 里 Flow Matching loss 的核心 target。
这一段的意义在于:对于 Gaussian path,我们不仅能指定中间分布,还能显式写出让 ODE 跟随这条 path 的 conditional velocity。后面训练神经网络时,就可以把这个可计算的 velocity 当作监督信号。
Continuity equation 与 marginalization trick 的证明
前面已经写出了 marginalization trick:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz.
现在需要解释为什么这个速度场真的能让 ODE 的分布沿着 marginal path pt 走。这里用到的工具是 continuity equation。
考虑一个 flow model:
X0∼pinit=p0,dtdXt=uttarget(Xt).
如果这个 ODE 在每个时间 t 的样本分布都是 pt,也就是
Xt∼pt,
那么 pt 和速度场之间必须满足
∂tpt(x)=−div(ptuttarget)(x).
这就是 continuity equation。
这个公式可以从概率质量守恒来理解。左边
∂tpt(x)
表示位置 x 处的概率密度随时间怎么变化。右边的 divergence 描述概率质量的流出程度:
div(ptut)(x)
可以理解成在位置 x 附近,概率质量沿着速度场向外流走的净量。因此前面加负号:
−div(ptut)(x)
表示净流入。某处密度增加,是因为流入大于流出;某处密度减少,是因为流出大于流入。
所以 continuity equation 说的就是:
概率密度的时间变化 = 概率质量的净流入。
这和流体力学里的质量守恒是同一个思想,只是这里流动的是概率质量。
有了这个方程,就可以证明 Theorem 9。marginal path 的密度是
pt(x)=∫pt(x∣z)pdata(z)dz.
对时间求导:
∂tpt(x)=∂t∫pt(x∣z)pdata(z)dz=∫∂tpt(x∣z)pdata(z)dz.
因为 conditional vector field 能实现 conditional path,所以每个 pt(x∣z) 都满足自己的 continuity equation:
∂tpt(x∣z)=−div(pt(⋅∣z)uttarget(⋅∣z))(x).
代入上式:
∂tpt(x)=∫−div(pt(⋅∣z)uttarget(⋅∣z))(x)pdata(z)dz.
把 divergence 和积分交换,就得到
∂tpt(x)=−div(∫pt(x∣z)uttarget(x∣z)pdata(z)dz).
而 marginal vector field 的定义正是
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz.
两边乘上 pt(x):
pt(x)uttarget(x)=∫pt(x∣z)uttarget(x∣z)pdata(z)dz.
因此
∂tpt(x)=−div(ptuttarget)(x).
这说明 marginal vector field 满足 continuity equation,所以它确实会让 ODE 的样本分布沿着 marginal path pt 演化。
这个证明的核心并不是复杂计算,而是一个很干净的结构:
- 每个 conditional path 都有自己的速度场;
- 每个 conditional path 都满足 continuity equation;
- marginal path 是 conditional paths 的混合;
- conditional velocities 按 posterior 权重平均后,得到的 marginal velocity 正好让混合分布也满足 continuity equation。
到这里,Flow Matching 的理论目标已经清楚了:如果能学到
uttarget(x),
那么从噪声出发模拟 ODE,就能得到数据分布。下一步的问题是训练:这个 marginal vector field 里面有不可计算的积分,神经网络怎样学到它?
3.3 Learning the Marginal Vector Field
现在目标已经明确:训练一个神经网络
utθ(x)
去逼近真正的 marginal vector field
uttarget(x).
如果能够做到
utθ(x)≈uttarget(x),
那么模拟
dXt=utθ(Xt)dt,X0∼pinit
就会得到近似满足
X1∼pdata
的生成模型。
最直接的想法是用均方误差:
LFM(θ)=Et∼Unif, x∼pt[utθ(x)−uttarget(x)2].
这个 loss 的含义很自然:随机取一个时间 t,再从对应的 marginal path pt 里取一个点 x,让网络输出的速度接近真正的 marginal velocity。
由于从 pt 采样可以通过 conditional path 完成,
z∼pdata,x∼pt(⋅∣z),
所以同一个 loss 也可以写成
LFM(θ)=Et∼Unif, z∼pdata, x∼pt(⋅∣z)[utθ(x)−uttarget(x)2].
问题在于,这个 loss 仍然不可计算。困难不在采样 x,而在 target:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz.
这个 target 是对所有可能数据点 z 的 posterior average,里面有不可计算的积分,也包含未知的 pt(x)。
Flow Matching 的关键转折是:不用直接回归 marginal target,而是回归 conditional target:
LCFM(θ)=Et∼Unif, z∼pdata, x∼pt(⋅∣z)[utθ(x)−uttarget(x∣z)2].
这个 loss 是可计算的,因为 uttarget(x∣z) 对我们选择的 probability path 通常有解析公式。比如 Gaussian path 中,上一节已经算出:
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx.
现在看起来有一个矛盾:我们真正想学的是 marginal vector field
uttarget(x),
但训练时却让网络拟合 conditional vector field
uttarget(x∣z).
Theorem 12 正是 Flow Matching 的核心。它说:
LFM(θ)=LCFM(θ)+C,
其中 C 与 θ 无关。因此
∇θLFM(θ)=∇θLCFM(θ).
也就是说,优化可计算的 LCFM,等价于优化不可计算的 LFM。如果模型表达能力足够强,最优的网络会学到 marginal vector field:
utθ(x)=uttarget(x).
这个结论的直觉其实就是均方误差的条件期望性质。对于固定的 noisy point x,conditional target
uttarget(x∣z)
会随着背后的 z 改变。均方误差下,最好的预测不是某一个具体 z 对应的速度,而是这些可能速度的条件平均:
E[uttarget(x∣z)∣x].
而这个条件平均正是 marginal vector field:
uttarget(x).
Theorem 12 的证明思路
证明不需要神秘技巧,只是展开平方项。先从 marginal loss 开始:
LFM(θ)=Et,x[utθ(x)−uttarget(x)2].
用
∥a−b∥2=∥a∥2−2a⊤b+∥b∥2
展开:
LFM(θ)=Et,x[∥utθ(x)∥2]−2Et,x[utθ(x)⊤uttarget(x)]+C1.
其中
C1=Et,x[∥uttarget(x)∥2]
不依赖 θ,所以对训练梯度来说只是常数。
第一项
Et,x∼pt[∥utθ(x)∥2]
可以直接改写成 conditional sampling:
Et,z,x∼pt(⋅∣z)[∥utθ(x)∥2].
关键是第二个内积项:
Et,x∼pt[utθ(x)⊤uttarget(x)].
把 marginal vector field 的定义代入:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz.
于是
Et,x∼pt[utθ(x)⊤uttarget(x)]=Et,z,x∼pt(⋅∣z)[utθ(x)⊤uttarget(x∣z)].
这一步是证明里最重要的一步:marginal target 出现在内积里时,可以换成 conditional target。
代回展开式后,再补上并减去
uttarget(x∣z)2,
就得到
LFM(θ)=LCFM(θ)+C,
其中 C 不依赖 θ。
这说明 Flow Matching 的训练可以完全避免显式计算 marginal vector field。训练时只需要:
- 采样时间 t;
- 采样数据 z;
- 从 pt(⋅∣z) 采样 noisy point x;
- 让网络预测 conditional velocity uttarget(x∣z)。
整个训练过程不需要模拟 ODE。也就是说,训练是 simulation-free 的。ODE 只在训练完成之后、生成样本时才需要模拟。
这就是 Flow Matching 简洁且适合大规模训练的原因:它把生成模型的训练变成了一个普通的监督回归问题。
Theorem 12 的更细证明
先固定一个时间 t。为了不让符号太重,暂时把 t 省略掉,最后再把对 t 的期望加回来。
训练时的采样过程是:
z∼pdata,x∼pt(⋅∣z).
这实际上定义了一个关于 (x,z) 的联合分布:
qt(x,z)=pt(x∣z)pdata(z).
它的 x-marginal 是:
pt(x)=∫pt(x∣z)pdata(z)dz.
因此 posterior 是:
qt(z∣x)=pt(x)pt(x∣z)pdata(z).
现在把 conditional target 记成
vt(x,z)=uttarget(x∣z).
marginal target 就是它在给定 x 后的条件平均:
vˉt(x)=uttarget(x)=E[vt(x,z)∣x].
也就是
vˉt(x)=∫vt(x,z)qt(z∣x)dz.
神经网络输出记成
Ut(x)=utθ(x).
于是两个 loss 可以写成:
LFM=Et,x[∥Ut(x)−vˉt(x)∥2],
LCFM=Et,x,z[∥Ut(x)−vt(x,z)∥2].
注意这两个期望里的 x 的 marginal 都是 pt(x)。区别只在 target:一个用条件平均 vˉt(x),另一个用具体的 vt(x,z)。
现在展开 LFM:
LFM=Et,x[∥Ut(x)∥2−2Ut(x)⊤vˉt(x)+∥vˉt(x)∥2].
也就是
LFM=Et,x[∥Ut(x)∥2]−2Et,x[Ut(x)⊤vˉt(x)]+Et,x[∥vˉt(x)∥2].
再展开 LCFM:
LCFM=Et,x,z[∥Ut(x)∥2−2Ut(x)⊤vt(x,z)+∥vt(x,z)∥2].
也就是
LCFM=Et,x,z[∥Ut(x)∥2]−2Et,x,z[Ut(x)⊤vt(x,z)]+Et,x,z[∥vt(x,z)∥2].
现在逐项比较。
第一项相同,因为 Ut(x) 只依赖 x,而两边的 x-marginal 都是 pt(x):
Et,x,z[∥Ut(x)∥2]=Et,x[∥Ut(x)∥2].
第二项也相同。先看 LCFM 里的交叉项:
Et,x,z[Ut(x)⊤vt(x,z)].
对给定的 t,x,Ut(x) 已经固定,不再依赖 z,所以可以先对 z∣x 取条件期望:
Ez∣x[Ut(x)⊤vt(x,z)]=Ut(x)⊤Ez∣x[vt(x,z)].
但根据 marginal target 的定义:
Ez∣x[vt(x,z)]=vˉt(x).
所以
Et,x,z[Ut(x)⊤vt(x,z)]=Et,x[Ut(x)⊤vˉt(x)].
这就是证明里最关键的一步:conditional target 在和网络输出做内积后,平均起来等于 marginal target。
第三项不相同:
Et,x[∥vˉt(x)∥2]
和
Et,x,z[∥vt(x,z)∥2]
一般不是同一个数。但是它们都不含 θ,因为它们只由我们构造的 target 决定,与神经网络参数无关。
因此两个 loss 的差只来自这两个不依赖 θ 的项:
LFM(θ)−LCFM(θ)=Et,x[∥vˉt(x)∥2]−Et,x,z[∥vt(x,z)∥2].
右边是一个常数,记成 C:
LFM(θ)=LCFM(θ)+C.
所以
∇θLFM(θ)=∇θLCFM(θ).
这就是 Theorem 12。
也可以用一句更短的统计语言理解:在均方误差下,如果 target 是随机变量 vt(x,z),而模型只能看到 x,那么最优预测就是条件期望
E[vt(x,z)∣x],
也就是 marginal vector field。
Algorithm 3 与 Gaussian Flow Matching loss
Theorem 12 之后,训练流程就变得非常直接。以最常用的 Gaussian CondOT path 为例:
αt=t,βt=1−t.
这时 conditional path 是
pt(x∣z)=N(tz,(1−t)2Id).
采样形式为
ϵ∼N(0,Id),x=tz+(1−t)ϵ.
对应的 conditional velocity target 是
uttarget(x∣z)=z−ϵ.
因此训练就是:

每个 mini-batch 中:
- 从数据集中采样一个真实样本
z∼pdata.
- 采样一个随机时间
t∼Unif[0,1].
- 采样标准高斯噪声
ϵ∼N(0,Id).
- 构造中间点
x=tz+(1−t)ϵ.
- 让网络预测这个点处的 velocity:
utθ(x).
- 用均方误差回归 target:
L(θ)=utθ(x)−(z−ϵ)2.
这就是 CondOT path 下的 Flow Matching loss。
这个训练循环有一个很重要的特点:训练时完全不需要模拟 ODE。每一步的训练样本 x 都是直接由
x=tz+(1−t)ϵ
构造出来的。ODE solver 只在训练完成后、真正采样生成时才使用。
因此 Flow Matching 是 simulation-free training。它不是一边训练一边从 t=0 rollout 到 t=1,而是随机抽一个时间 t,直接构造那个时间的 noisy sample,然后做监督回归。
Gaussian path 下的一般 Flow Matching loss
CondOT 是最简单的 path,但 Gaussian probability path 可以更一般。设
pt(x∣z)=N(αtz,βt2Id).
采样形式是
ϵ∼N(0,Id),xt=αtz+βtϵ.
前面已经推导过,这个 path 的 conditional vector field 是
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx.
如果把训练点
xt=αtz+βtϵ
代入这个速度场,会得到一个更简单的 target:
uttarget(xt∣z)=α˙tz+β˙tϵ.
因为沿着 path 本身求导就是
dtdxt=dtd(αtz+βtϵ)=α˙tz+β˙tϵ.
于是一般 Gaussian path 的 conditional flow matching loss 可以写成
LCFM(θ)=Et,z,ϵ[utθ(αtz+βtϵ)−(α˙tz+β˙tϵ)2],
其中
t∼Unif[0,1],z∼pdata,ϵ∼N(0,Id).
CondOT 只是把
αt=t,βt=1−t
代进去。此时
α˙t=1,β˙t=−1,
所以 target 变成
α˙tz+β˙tϵ=z−ϵ.
因此 CondOT loss 是
LCFM(θ)=Et,z,ϵ[utθ(tz+(1−t)ϵ)−(z−ϵ)2].
这个公式几乎就是 Flow Matching 最常见的训练形式。它只有三个随机量:数据 z、噪声 ϵ、时间 t。然后构造 xt,让网络预测从噪声指向数据的速度。
训练后的 ODE 与本节总结
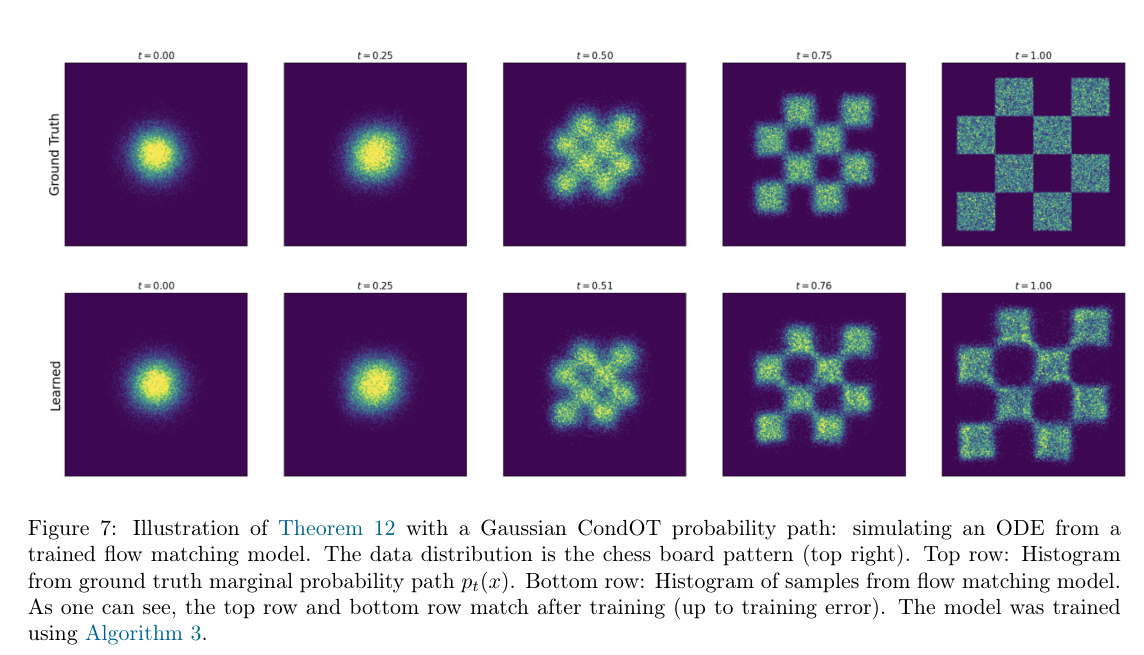
Figure 7 用一个二维棋盘分布展示 Theorem 12 的效果。上排是 ground-truth marginal probability path,也就是我们希望的 pt。下排是训练好的 Flow Matching model 通过模拟 ODE 得到的样本分布。
如果训练成功,那么下排应该和上排匹配。图里可以看到:
- t=0 时,两者都是近似高斯噪声;
- 中间时间,样本逐渐从中心扩散并形成棋盘结构;
- t=1 时,模型生成的分布接近目标数据分布。
这张图说明:虽然训练时网络回归的是 conditional velocity,
uttarget(x∣z),
但最终模拟 ODE 时,网络学到的行为接近 marginal velocity,
uttarget(x).
这正是 Theorem 12 的实际效果。
Summary 14:Flow Matching 的完整结构
Flow Matching 到这里形成了一个完整闭环。

第一步,选择 conditional probability path:
pt(x∣z),
满足
p0(⋅∣z)=pinit,p1(⋅∣z)=δz.
它描述如何从噪声分布走到某个固定数据点 z。
第二步,找到对应的 conditional vector field:
uttarget(x∣z),
使得
X0∼pinit,dXt=uttarget(Xt∣z)dt
推出
Xt∼pt(⋅∣z).
第三步,把 conditional vector field 做 posterior average,得到 marginal vector field:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz.
这个速度场满足
X0∼pinit,dXt=uttarget(Xt)dt⟹Xt∼pt.
因此终点满足
X1∼pdata.
第四步,训练神经网络。虽然 marginal vector field 不可直接计算,但 Theorem 12 说明,只需要最小化 conditional flow matching loss:
LCFM(θ)=Et,z,x∼pt(⋅∣z)[utθ(x)−uttarget(x∣z)2].
优化这个 loss 等价于学习 marginal vector field。
Gaussian path 的最终公式
最常用的例子是 Gaussian probability path:

它的 conditional path 是
pt(x∣z)=N(x;αtz,βt2Id).
conditional vector field 是
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx.
训练 loss 可以写成
LCFM(θ)=Et,z,ϵ[utθ(αtz+βtϵ)−(α˙tz+β˙tϵ)2].
其中 scheduler 满足
α0=0,α1=1,β0=1,β1=0.
CondOT 是最简单的特例:
αt=t,βt=1−t.
于是
xt=tz+(1−t)ϵ,uttarget(xt∣z)=z−ϵ.
训练目标就是
utθ(tz+(1−t)ϵ)−(z−ϵ)2.
到这里,Flow Matching 这一节的主线已经完成:
选择一条从噪声到数据的 probability path,写出 conditional velocity,用它训练网络;虽然训练 target 是 conditional 的,MSE 最优解却是 marginal velocity,因此训练好的 ODE 可以从噪声生成数据。
4. Score Functions and Score Matching:从速度场到 score
Flow Matching 中的核心对象是 vector field:
ut(x).
它告诉我们在时间 t、位置 x,样本应该朝哪个方向移动。Diffusion models 常常使用另一种语言:score function。
给定一个概率密度 q(x),它的 score function 定义为
∇logq(x).
这个对象的含义很直接:它指向让 log-density 增长最快的方向。也就是说,如果当前位置是 x,那么沿着
∇logq(x)
走一小步,会最有效地进入 q 认为更高概率的区域。
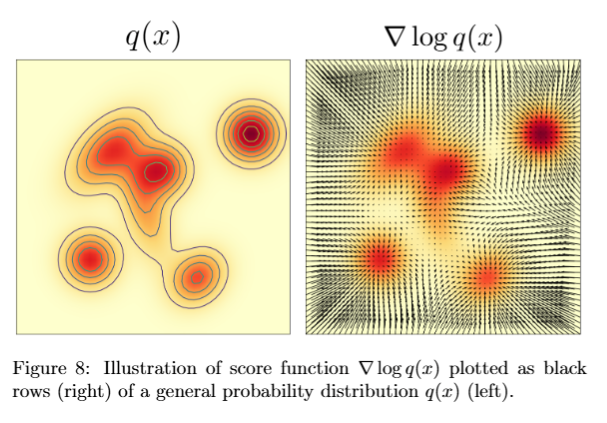
图 8 左边是一块概率密度,右边的箭头就是 score field。箭头一般会指向高密度区域;在低密度区域,score 会告诉你“往哪里走更像这个分布”。
这和生成模型的直觉很接近。生成时,样本一开始是噪声,处在数据分布的低概率区域。score 提供了一个方向:怎样把样本往更高概率、更像数据的地方推。
4.1 Conditional and Marginal Score Functions
回到 probability path。固定一个 clean data z 时,有 conditional density
pt(x∣z).
混合所有可能的 z∼pdata 后,有 marginal density
pt(x)=∫pt(x∣z)pdata(z)dz.
因此有两种 score:
∇xlogpt(x∣z)
和
∇xlogpt(x).
前者知道当前 noisy sample x 是围绕哪个 clean data z 生成的;后者不知道 z,只知道当前看到的是 x。
和 marginal vector field 一样,marginal score 也可以写成 conditional score 的 posterior average:
∇logpt(x)=∫∇logpt(x∣z)pt(x)pt(x∣z)pdata(z)dz.
其中
pt(x)pt(x∣z)pdata(z)
就是 Bayes posterior:
pt(z∣x).
所以这个公式也可以写成更直观的形式:
∇logpt(x)=Ez∣x[∇logpt(x∣z)].
意思是:当前 noisy sample 是 x,它可能来自很多不同的 clean data z;每个 z 都给出一个 conditional score,marginal score 是这些 conditional score 的 posterior average。
这个公式从 score 的定义直接推出。首先
∇logpt(x)=pt(x)∇pt(x).
代入 marginal density:
∇logpt(x)=pt(x)∇∫pt(x∣z)pdata(z)dz.
把梯度放进积分:
∇logpt(x)=pt(x)∫∇pt(x∣z)pdata(z)dz.
再使用恒等式
∇pt(x∣z)=pt(x∣z)∇logpt(x∣z),
就得到 posterior average 形式。
Gaussian path 的 score
对 Gaussian probability path,
pt(x∣z)=N(αtz,βt2Id).
它的均值是 αtz,协方差是 βt2Id。log-density 中和 x 有关的部分为
logpt(x∣z)=−2βt21∥x−αtz∥2+const.
对 x 求梯度。因为
∇x∥x−αtz∥2=2(x−αtz),
所以
∇xlogpt(x∣z)=−βt2x−αtz=βt2αtz−x.
这个 score 指向均值 αtz。如果 x 偏离均值,score 会把它往均值方向拉;βt 越小,分布越尖锐,同样偏离下 score 的幅度越大。
如果使用采样形式
xt=αtz+βtϵ,ϵ∼N(0,Id),
那么
∇xlogpt(xt∣z)=−βtϵ.
这说明,在 Gaussian path 上,conditional score 和噪声 ϵ 是同一信息的不同缩放。这也是后面 diffusion 训练可以做 noise prediction 的原因。
Gaussian path 下 score 与 velocity 的转换
Gaussian path 的 conditional velocity 已经在 Flow Matching 中算过:
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx.
而 conditional score 是
∇logpt(x∣z)=βt2αtz−x.
这两个对象都是 x,z 的线性函数,所以可以互相转换。定义
at=βt2αtα˙t−β˙tβt,bt=αtα˙t.
那么
uttarget(x∣z)=at∇logpt(x∣z)+btx.
验证这个公式只需要代入 score:
at∇logpt(x∣z)+btx=atβt2αtz−x+btx.
把它按 z 和 x 分组:
=βt2atαtz+(bt−βt2at)x.
由 at,bt 的定义,
βt2atαt=α˙t−βtβ˙tαt,
并且
bt−βt2at=βtβ˙t.
所以右边正好变回
uttarget(x∣z).
同样的转换对 marginal 版本也成立:
uttarget(x)=at∇logpt(x)+btx.
原因是 conditional 公式两边对 z∣x 做 posterior average 后,左边变成 marginal velocity,右边的 conditional score 变成 marginal score,而 btx 不依赖 z。
这一步是本节的关键桥梁:在 Gaussian probability path 下,Flow Matching 的 velocity 和 diffusion 的 score 不是两套无关对象,而是同一信息的两种线性参数化。
Denoiser 参数化
除了 velocity 和 score,还有一种常见参数化:denoiser。conditional denoiser 定义为
Dt(x∣z)=z.
marginal denoiser 是 posterior mean:
Dt(x)=E[z∣x]=∫zpt(x)pt(x∣z)pdata(z)dz.
它表示:给定 noisy sample x 后,对背后的 clean data z 的平均估计。
因此,在 Gaussian path 下,velocity、score、denoiser、noise prediction 都在表达同一件事:给定 noisy sample x,恢复或利用它背后的 clean data 信息。Diffusion models 常学习 score 或 noise;Flow Matching 常学习 velocity;denoising models 常学习 denoiser。
4.2 Sampling with SDEs
到目前为止,我们知道如何用 ODE 沿着 probability path 采样。只要有 marginal vector field
uttarget(x),
模拟
dXt=uttarget(Xt)dt
就能保证
Xt∼pt.
这对应的是 flow model。Diffusion model 还需要处理 SDE,也就是在动力系统里加入随机噪声:
dXt=ut(Xt)dt+σtdWt.
问题在于,直接往 ODE 里加 Brownian noise 会改变样本分布。噪声会把概率质量扩散开,原来的 probability path 不会自动保持不变。Theorem 17 给出的结论是:可以加噪声,但要同时加上一项由 score 控制的 drift,用来抵消噪声对 marginal distribution 的影响。
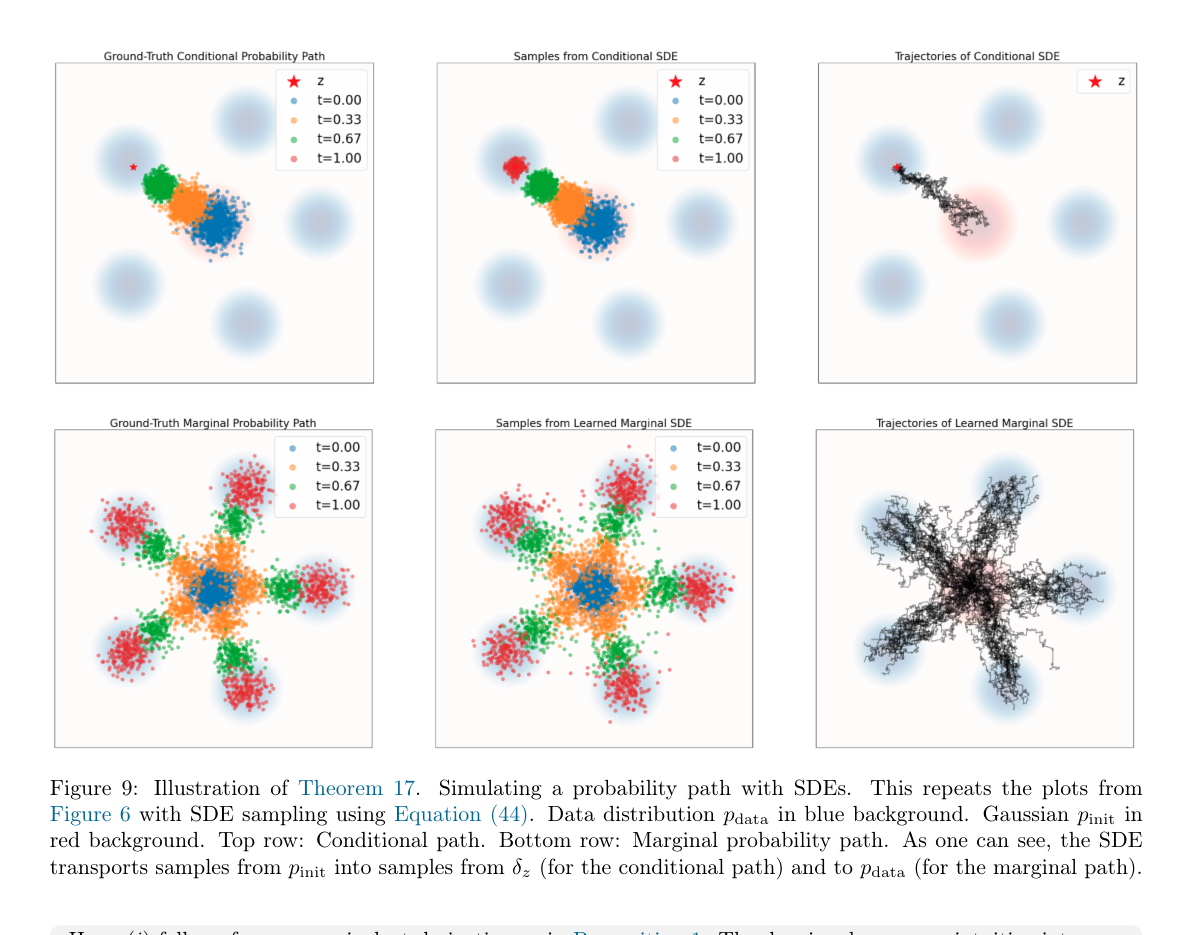
Figure 9 和前面 Figure 6 很像,但现在轨迹变成了 SDE 轨迹。右边的轨迹不再平滑,而是带有随机抖动。关键是:虽然单条轨迹变随机了,不再由初始点完全决定,但每个时间 t 的样本分布仍然沿着同一条 probability path。
Theorem 17: SDE Extension Trick
设原来的 marginal vector field 是
uttarget(x),
并且它对应的 ODE 可以让样本分布满足
Xt∼pt.
那么对任意 diffusion coefficient
σt≥0,
可以构造下面这个 SDE:
dXt=[uttarget(Xt)+2σt2∇logpt(Xt)]dt+σtdWt.
这个 SDE 仍然满足
Xt∼pt,0≤t≤1.
特别地,
X1∼pdata.
这条公式里有两部分 drift:
uttarget(Xt)
是原来 flow 的速度场,负责沿着 probability path 往前推进;
2σt2∇logpt(Xt)
是新增的 score drift。它的作用是配合 Brownian noise,使加噪后的过程仍然保持正确的 marginal distribution。
如果只加
σtdWt,
分布会被扩散项摊开;score drift 会把样本往高密度区域拉回来。两者配合后,SDE 的 marginal 仍然是 pt。
因此 Theorem 17 可以这样理解:
在同一条 probability path 上,不只有一条 ODE 可以实现它;也可以有一族 SDE 实现它。σt 控制轨迹有多随机,score term 负责让随机性不破坏目标 marginal path。
当
σt=0
时,SDE 退化回原来的 ODE:
dXt=uttarget(Xt)dt.
所以 flow sampling 是 SDE sampling 的特殊情况。
Gaussian path 下的 SDE 写法
对 Gaussian probability path,我们已经知道 velocity 和 score 可以互相转换:
uttarget(x)=at∇logpt(x)+btx.
因此 Theorem 17 的 SDE 可以写成纯 score 形式:
dXt=[(at+2σt2)∇logpt(Xt)+btXt]dt+σtdWt.
这说明一旦学到了 score,就可以用不同的 σt 构造不同的 SDE sampler。理论上任意 σt≥0 都能保持同一个 marginal path;实践中因为神经网络有误差、数值模拟也有误差,σt 的选择会影响采样效果。
这也解释了为什么 diffusion sampling 有很多 sampler 变体:它们常常对应不同的 SDE/ODE 采样方式,但背后使用的是同一个 score 或与 score 等价的参数化。
Fokker-Planck equation
Fokker-Planck equation 是把“单个粒子的 SDE”翻译成“一群粒子的密度演化”的方程。
SDE 描述的是一条随机轨迹:
dXt=ut(Xt)dt+σtdWt.
如果只看一个粒子,看到的是它在速度场和随机噪声共同作用下怎么走。但生成模型关心的是很多粒子的整体分布。假设有一大群粒子都按这个 SDE 运动,它们在时间 t 的空间密度记作
pt(x).
Fokker-Planck equation 说的就是:这些粒子的密度 pt(x) 会怎样随时间变化。
对于 SDE
dXt=ut(Xt)dt+σtdWt,
如果
Xt∼pt,
那么 pt 满足
∂tpt(x)=−div(ptut)(x)+2σt2Δpt(x).
右边有两种机制。
第一项
−div(ptut)(x)
是 drift / transport 项。它描述速度场 ut 如何搬运概率质量。可以把它想成水流推动墨水:墨水本身没有凭空产生或消失,只是被流场搬到别的位置。
如果没有 Brownian noise,也就是 σt=0,Fokker-Planck equation 退化成 continuity equation:
∂tpt(x)=−div(ptut)(x).
第二项
2σt2Δpt(x).
是 diffusion 项。它来自 Brownian noise,描述随机碰撞如何把概率质量向周围摊开。物理上可以把它想成热扩散或墨水在静止水里慢慢散开:高密度区域会被抹平,低密度区域会被填起来。
因此 Fokker-Planck equation 的物理本质是:
单个粒子的随机运动规则,诱导出整体粒子密度的演化规律。
简洁地说:
SDE: 一个粒子怎么动
Fokker-Planck: 一群粒子的密度怎么变
Theorem 17 的证明思路
原来的 ODE 已经满足 continuity equation:
∂tpt(x)=−div(ptuttarget)(x).
现在希望构造一个 SDE drift:
u~t(x)=uttarget(x)+2σt2∇logpt(x).
需要证明它满足 Fokker-Planck equation:
∂tpt(x)=−div(ptu~t)(x)+2σt2Δpt(x).
从 continuity equation 出发:
∂tpt(x)=−div(ptuttarget)(x).
加上再减去同一个扩散项:
∂tpt(x)=−div(ptuttarget)(x)−2σt2Δpt(x)+2σt2Δpt(x).
利用
Δpt=div(∇pt),
以及
∇pt=pt∇logpt,
中间的负扩散项可以写成
−2σt2Δpt=−div(pt2σt2∇logpt).
于是
∂tpt(x)=−div(pt[uttarget+2σt2∇logpt])(x)+2σt2Δpt(x).
这正是 SDE drift
uttarget+2σt2∇logpt
对应的 Fokker-Planck equation。因此这个 SDE 的 marginal distribution 仍然是 pt。
Langevin dynamics
Theorem 17 有一个重要特例。如果 probability path 不随时间变化,也就是
pt=p,
并且取
uttarget=0,
那么 Theorem 17 给出:
dXt=2σt2∇logp(Xt)dt+σtdWt.
这就是 Langevin dynamics。
Langevin dynamics 可以看成一种物理平衡机制:粒子一边被随机噪声推动,一边被 score field 拉向目标分布的高密度区域。
如果只有噪声项
dXt=σtdWt,
粒子会不断扩散,分布越来越摊开。
如果只有 score drift
dXt=2σt2∇logp(Xt)dt,
粒子会沿着 log-density 上升方向移动,趋向高概率区域,但缺少随机探索。
Langevin dynamics 把两者放在一起:
Brownian noise 负责探索
score drift 负责拉回高概率区域
当这两种作用达到平衡时,目标分布 p 就成为 stationary distribution。
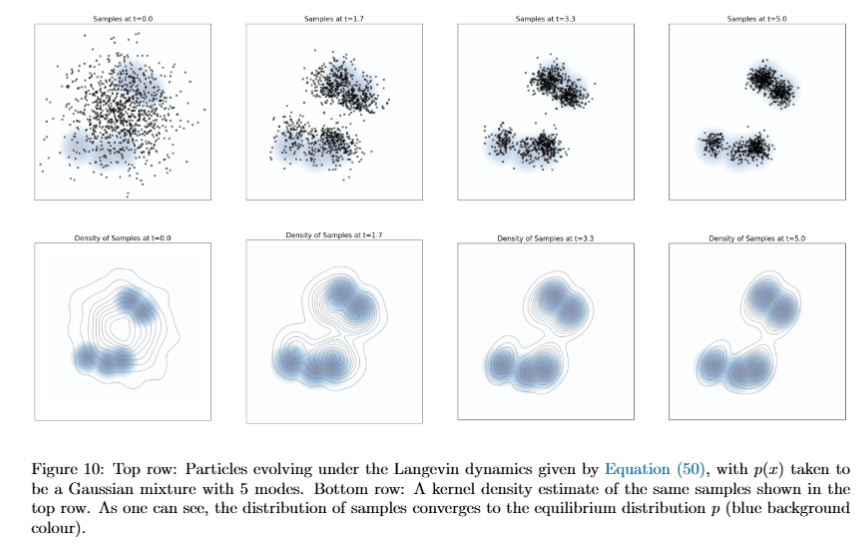
Figure 10 中,目标分布 p(x) 是一个有 5 个 mode 的 Gaussian mixture。上排黑点是 Langevin dynamics 中的粒子,底排是这些粒子的密度估计。最开始粒子比较分散,随着时间推进,粒子逐渐集中到蓝色高密度区域附近。
这张图体现了 Langevin dynamics 的两个作用:
- Brownian noise 让粒子能够探索空间,而不是只沿着确定性路径走;
- score term ∇logp(x) 把粒子推向目标分布的高密度区域。
当这两个作用达到平衡时,p 就成为 stationary distribution。也就是说,如果一开始
X0∼p,
那么 Langevin dynamics 会保持
Xt∼p.
如果一开始不是 p,在一定条件下样本分布也会逐渐靠近 p。
这也是它和 diffusion models 的连接。Diffusion sampling 不是简单地“沿着 score 爬坡”,也不是简单地“加噪声乱走”,而是在随机探索和 score 引导之间保持平衡,让整体分布按照我们想要的路径演化。
这一小节可以收成一句话:
ODE 用 velocity 沿着 probability path 推动样本;SDE 可以在此基础上加入 Brownian noise,但必须同时加入 score drift,才能让每个时间的 marginal distribution 仍然等于指定的 pt。
4.3 Score Matching
4.2 说明了如果知道 marginal score
∇logpt(x),
就可以把它放进 SDE sampler:
dXt=[uttarget(Xt)+2σt2∇logpt(Xt)]dt+σtdWt.
现在剩下的问题是:这个 marginal score 怎么学?
和 Flow Matching 一样,理想目标是直接回归 marginal object。定义 score network:
stθ:Rd×[0,1]→Rd.
它希望近似
stθ(x)≈∇logpt(x).
最直接的 score matching loss 是
LSM(θ)=Et∼Unif, z∼pdata, x∼pt(⋅∣z)[stθ(x)−∇logpt(x)2].
这里虽然采样 x 没有问题,但 target
∇logpt(x)
不可直接计算,因为它是 marginal score,需要对所有可能的 z 做 posterior average。
于是定义 conditional score matching loss:
LCSM(θ)=Et,z,x∼pt(⋅∣z)[stθ(x)−∇logpt(x∣z)2].
这个 loss 可计算,因为 conditional score 由我们选择的 probability path 决定,通常有解析形式。
Theorem 22 说:
LSM(θ)=LCSM(θ)+C,
其中 C 与 θ 无关,因此
∇θLSM(θ)=∇θLCSM(θ).
这个结论和 Theorem 12 完全平行。原因是
∇logpt(x)=Ez∣x[∇logpt(x∣z)].
也就是说,conditional score 的 posterior average 就是 marginal score。用 MSE 训练时,网络只能看到 x,所以最优预测就是对所有可能 z 的条件平均。
因此:
回归可计算的 conditional score,等价于学习不可直接计算的 marginal score。
Gaussian path 下的 denoising score matching
对 Gaussian probability path:
pt(x∣z)=N(αtz,βt2Id),
4.1 已经算出 conditional score:
∇logpt(x∣z)=−βt2x−αtz.
把它代入 conditional score matching loss:
LCSM(θ)=E[stθ(x)+βt2x−αtz2].
现在用 Gaussian path 的采样形式:
xt=αtz+βtϵ,ϵ∼N(0,Id).
则
xt−αtz=βtϵ.
所以 conditional score 是
∇logpt(xt∣z)=−βtϵ.
于是 loss 变成
LCSM(θ)=Et,z,ϵ[stθ(αtz+βtϵ)+βtϵ2].
这就是 denoising score matching。它的名字来自这里:我们先用噪声 ϵ 污染数据 z,得到 xt;然后训练网络从 noisy sample 中恢复与噪声相关的信息。
Noise prediction 参数化
上面的 score target 是
−βtϵ.
当 βt 很小时,这个量会变得很大,训练可能不稳定。早期 DDPM 的做法是改成 noise prediction。定义噪声预测网络
ϵtθ(x)=−βtstθ(x).
如果
stθ(xt)≈−βtϵ,
那么
ϵtθ(xt)=−βtstθ(xt)≈ϵ.
因此可以直接训练网络预测加进去的噪声:
LDDPM(θ)=Et,z,ϵ[ϵtθ(αtz+βtϵ)−ϵ2].
这个形式就是 diffusion models 中非常常见的噪声预测 loss。它和 score matching 的目标等价,只是参数化更稳定。

Algorithm 4 的训练流程可以读成:
- 采样真实数据
z∼pdata.
- 采样时间
t∼Unif[0,1].
- 采样噪声
ϵ∼N(0,Id).
- 构造 noisy sample
xt=αtz+βtϵ.
- 可以训练 score network:
stθ(xt)+βtϵ2.
也可以训练 noise predictor:
ϵtθ(xt)−ϵ2.
Summary 24:Score matching 与 stochastic sampling


这一节可以收成三个结论。
第一,conditional score 和 marginal score 分别是
∇logpt(x∣z),∇logpt(x).
第二,如果知道 marginal vector field 和 marginal score,那么对任意 σt≥0,SDE
dXt=[uttarget(Xt)+2σt2∇logpt(Xt)]dt+σtdWt
都会沿着同一条 probability path:
Xt∼pt.
第三,marginal score 可以通过 denoising score matching 学到:
LCSM(θ)=Ez,t,x∼pt(⋅∣z)[stθ(x)−∇logpt(x∣z)2].
对 Gaussian path,还可以在 score 和 velocity 之间转换:
utθ(x)=atstθ(x)+btx.
因此学 score、学 velocity、学 noise,在 Gaussian path 下都是同一个模型能力的不同表达。训练完成后,可以选择 ODE sampler,也可以选择 SDE sampler。
5. Guidance: How To Condition on a Prompt
前面讨论的生成模型都是 unguided:模型从
pdata(z)
中采样,也就是生成某个来自数据分布的对象。但实际使用生成模型时,我们通常不想生成“任意图片”,而是想生成满足某个条件的对象。例如给定文本 prompt
y=“corgi dog”,
希望生成符合这个 prompt 的图像。
数学上,目标从无条件采样变成条件采样:
z∼pdata(⋅∣y).
这里使用 guided 这个词,而不是 conditional。原因是前面已经用 conditional probability path / conditional vector field 表示“给定数据点 z”的对象。为了避免混淆,这一节把“给定 prompt 或 label y”称为 guided generation。
5.1 Vanilla Guidance
最直接的 guided model 做法很简单:把 prompt 或 label y 作为网络输入的一部分。
在 unguided diffusion model 里,神经网络是
uθ:Rd×[0,1]→Rd,(x,t)↦utθ(x).
guided diffusion model 则变成
uθ:Rd×Y×[0,1]→Rd,
也就是
(x,y,t)↦utθ(x∣y).
这里 Y 是条件变量所在的空间。如果 y 是文本 prompt,那么 Y 是所有文本的集合;如果 y 是类别标签,那么 Y 是离散标签集合。
采样时,给定某个 prompt y,从简单噪声初始化:
X0∼pinit,
然后模拟 guided SDE:
dXt=utθ(Xt∣y)dt+σtdWt.
目标是
X1∼pdata(⋅∣y).
如果
σt=0,
则得到 guided flow model:
dXt=utθ(Xt∣y)dt.
为了让记号更简洁,这里主要用 flow matching 来说明,但同样思想也适用于 diffusion / score matching。
Guided flow matching objective
训练 guided flow model 时,数据不再只是
z∼pdata,
而是成对样本:
(z,y)∼pdata(z,y).
例如图像和文字描述,或者图像和类别标签。
如果固定某个 y,目标分布就是
pdata(z∣y).
此时可以像无条件 flow matching 一样训练:
Ez∼pdata(⋅∣y), x∼pt(⋅∣z)[utθ(x∣y)−uttarget(x∣z)2].
把所有可能的 y 一起考虑,就得到 guided conditional flow matching objective:
LCFMguided(θ)=E(z,y)∼pdata(z,y), t∼Unif[0,1], x∼pt(⋅∣z)[utθ(x∣y)−uttarget(x∣z)2].
这个公式和无条件版本的区别只有一个:网络输入多了 y,训练数据从单个 z 变成 pair
(z,y).
注意,conditional probability path
pt(⋅∣z)
以及 conditional vector field
uttarget(x∣z)
通常不需要依赖 y。因为 z 已经是具体数据样本,路径描述的是如何从噪声走到这个 z。y 的作用主要是告诉神经网络:在看到 noisy sample x 时,应该使用哪种条件下的 vector field。
PyTorch 实现上,这意味着 dataloader 不再只返回 images / latents:
z
而是返回 paired batch:
(z, y)
然后模型调用从
u_theta(x, t)
变成
u_theta(x, y, t)
Vanilla guidance 的局限
理论上,vanilla guidance 应该可以学到
pdata(⋅∣y).
但实际图像生成中,人们发现这种方式生成的样本有时并不够符合 prompt。Figure 11 展示了这个问题。

左边是 vanilla guidance 生成的样本,prompt/class 是 “corgi dog”,但有些图像并不像 corgi。右边使用了更强的 guidance 后,样本明显更符合 prompt。
出现这个问题有很多原因:
- 模型可能没有完全学到真实的 guided vector field;
- 数据中的图文配对可能有噪声;
- prompt 对应的语义可能比较弱,模型容易生成“看起来合理但不够贴合条件”的样本。
因此,仅仅把 y 输入网络通常还不够。下一节要解决的问题是:如何人为强化 prompt 的影响,让生成结果更贴合 y。这就是 classifier-free guidance 的动机。
5.2 Classifier-Free Guidance
Vanilla guidance 只是把 y 输入网络,让模型学习
uttarget(x∣y).
理论上这应该能采样
pdata(⋅∣y),
但实践中 prompt adherence 往往不够强。Classifier-free guidance 的目的,就是在采样时人为放大“和 prompt 有关的那部分方向”。

Figure 12 画出了两种思路。上排是 classifier guidance:把 guided vector field 拆成 unguided part 和 classifier 提供的 prompt-dependent part,然后放大后者。下排是 classifier-free guidance:不训练额外 classifier,而是用 guided vector field 和 unguided vector field 的差来表示 prompt-dependent part,再把这个差放大。
Classifier guidance:先看 prompt-dependent part 从哪里来
先考虑 Gaussian probability path。上一节已经知道,guided vector field 可以用 guided score 写成
uttarget(x∣y)=at∇logpt(x∣y)+btx.
这里的 pt(x∣y) 是在条件 y 下,时间 t 的 noisy sample 分布。
用 Bayes’ rule:
pt(x∣y)=pt(y)pt(x)pt(y∣x).
对 x 取 ∇log:
∇logpt(x∣y)=∇logpt(x)+∇logpt(y∣x).
这里没有 ∇logpt(y),因为梯度是对 x 求的,而 pt(y) 不依赖 x。
代回 guided vector field:
uttarget(x∣y)=btx+at(∇logpt(x)+∇logpt(y∣x)).
而 unguided vector field 是
uttarget(x)=at∇logpt(x)+btx.
所以
uttarget(x∣y)=uttarget(x)+at∇logpt(y∣x).
这个公式很有解释力:
- uttarget(x) 是不看 prompt 的生成方向;
- at∇logpt(y∣x) 是和 prompt 相关的修正方向。
其中 pt(y∣x) 可以理解成一个 classifier:给定 noisy sample x,判断它属于 prompt / class y 的可能性。因此
∇logpt(y∣x)
就是“怎样移动 x,能让它更像 label y”的方向。
如果 vanilla guidance 对 prompt 的响应不够强,一个自然想法是把这部分放大:
u~t(x∣y)=uttarget(x)+wat∇logpt(y∣x),w>1.
这里 w 叫 guidance scale。w=1 时回到普通 guided vector field;w>1 时,prompt-dependent part 被放大。
这就是 classifier guidance。问题是它需要额外训练一个 classifier 来估计
pt(y∣x),
并且如果 y 是文本 prompt,而不是简单类别标签,这个 classifier 会很难训练。
Classifier-free guidance:不用 classifier 也能放大 prompt
Classifier-free guidance 的关键是把 classifier term 消掉。
从刚才的分解:
uttarget(x∣y)=uttarget(x)+at∇logpt(y∣x).
因此
at∇logpt(y∣x)=uttarget(x∣y)−uttarget(x).
也就是说,prompt-dependent part 可以直接看成:
guided vector field−unguided vector field.
把这个差放大:
u~t(x∣y)=uttarget(x)+w(uttarget(x∣y)−uttarget(x)).
整理:
u~t(x∣y)=(1−w)uttarget(x)+wuttarget(x∣y).
这就是 classifier-free guidance 的核心公式。
它的意思是:
用 guided vector field 减去 unguided vector field 得到 prompt-dependent part,然后把这部分放大。
当 w=1:
u~t(x∣y)=uttarget(x∣y).
当 w>1 时,采样方向会比普通 guided model 更强调 y。这通常会提高 prompt adherence,但也可能降低多样性,甚至让样本变得过度刻板。
需要注意:当 w=1 时,
u~t(x∣y)
不再是严格意义上的真实 guided vector field。它是一个经验上非常有效的 heuristic。
一个模型同时学 guided 和 unguided
公式里需要两个对象:
uttarget(x∣y)
和
uttarget(x).
如果分别训练两个模型,成本会很高。CFG 的做法是引入一个特殊空条件:
∅.
把 unguided vector field 写成
uttarget(x)=uttarget(x∣∅).
这样一个网络
utθ(x∣y)
既能在输入真实 y 时学习 guided vector field,也能在输入 ∅ 时学习 unguided vector field。
训练时,随机把一部分 label 丢掉:
y←∅.
丢 label 的概率记作
η.
于是训练目标为
LCFMCFG(θ)=E[utθ(x∣y)−uttarget(x∣z)2],
其中采样过程是:
(z,y)∼pdata(z,y),t∼Unif[0,1],x∼pt(⋅∣z),
并且以概率 η 把 y 替换成 ∅。

对 Gaussian path:
x=αtz+βtϵ,
target 是
α˙tz+β˙tϵ.
所以 Algorithm 5 就是:
- 采样 paired data (z,y);
- 采样时间 t;
- 采样噪声 ϵ;
- 构造 x=αtz+βtϵ;
- 以概率 η 丢掉 label,令 y=∅;
- 训练
utθ(x∣y)−(α˙tz+β˙tϵ)2.
推理时怎么用 CFG
训练完成后,采样时给定真实 prompt y。每一步都计算两个网络输出:

utθ(x∣y)
和
utθ(x∣∅).
然后组合成 CFG vector field:
u~tθ(x∣y)=(1−w)utθ(x∣∅)+wutθ(x∣y).
也常写成:
u~tθ(x∣y)=utθ(x∣∅)+w(utθ(x∣y)−utθ(x∣∅)).
第二种写法更直观:从 unguided direction 出发,加上放大后的 prompt-dependent difference。
然后用这个 u~tθ 模拟 ODE:
dXt=u~tθ(Xt∣y)dt.
如果是 diffusion model,也可以把原来的 vector field 替换成 u~tθ,再用 SDE sampler。
Guidance scale 的效果

Figure 13 展示了不同 guidance scale w 的效果。w=1 时就是普通 guided model;w=2、w=4 时,类别条件被更强地强调,生成结果更贴近目标数字类别。
但 w 不是越大越好。一般来说:
- w 小:多样性更高,但可能不够贴合 prompt;
- w 大:prompt adherence 更强,但可能牺牲多样性和自然度。
现代图像/视频生成模型大量依赖 CFG。它不是严格保持
X1∼pdata(⋅∣y)
的精确采样方法,而是一个经验效果极好的 prompt reinforcement heuristic。
本节可以收成一句话:
Classifier-free guidance 通过同时学习 conditional 和 unconditional vector fields,在采样时放大二者的差,从而强化 prompt 对生成方向的影响。
6. Building Large-Scale Image or Video Generators
前面几节已经把生成模型的数学核心搭起来了。无论是 flow matching 还是 diffusion,训练出来的对象都可以写成一个带参数的向量场:
utθ(x∣y).
它接收三个东西:
x∈Rd,t∈[0,1],y∈Y,
输出一个和 x 同维度的向量:
utθ(x∣y)∈Rd.
这个向量就是采样时要沿着走的方向。对低维 toy examples 来说,把 x,t,y 拼起来喂给一个 MLP 就够了;但图像、视频、蛋白质这样的数据有很强的结构,维度也极高,直接用普通 MLP 基本不可行。
第 6 节讨论的是:在真实的大规模图像和视频生成模型里,这个 utθ(x∣y) 到底怎么实现。
它分成三件事:
- 怎样把原始条件输入变成模型能处理的向量表示,例如时间 t、类别 label、文本 prompt;
- 怎样设计真正的 neural network architecture,例如 Diffusion Transformer 和 U-Net;
- 为什么现代模型几乎都不直接在像素空间生成,而是在 autoencoder 的 latent space 里生成。
这一节的重点不是改变前面学过的数学目标,而是把数学目标落到可扩展的网络结构上。
6.1 Neural Network Architectures
模型输入和输出的形状
对 guided generation,网络形式是:
utθ(x∣y).
其中:
x∈Rd
是当前带噪样本,或者当前 latent;
t∈[0,1]
表示现在处在 probability path 的哪一个时间点;
y∈Y
是条件变量,例如类别、文本 prompt、图像条件、视频条件等。
网络输出:
utθ(x∣y)∈Rd
必须和 x 的形状一致。因为采样时要做的是:
dXt=utθ(Xt∣y)dt,
或者在 diffusion model 里:
dXt=utθ(Xt∣y)dt+σtdWt.
因此网络不是输出一个类别概率,也不是输出一句话,而是输出“每个像素/latent 维度下一步该怎么动”。
如果 x 是图像,通常写成:
x∈RC×H×W.
其中 C 是通道数,RGB 图像里通常 C=3,H,W 是图像高和宽。网络输出也必须是:
utθ(x∣y)∈RC×H×W.
这就是为什么图像生成模型需要 U-Net、DiT 这类能保留空间结构的 architecture,而不是普通全连接网络。
6.1.1 Embedding the Conditioning Variables
模型需要吃进去的条件变量有三类:时间、类别、文本。它们原本的形式差别很大,因此第一步是把它们都变成连续向量。
Embedding time.
时间 t 是一个标量。但模型需要知道的不是“一个数字”,而是这个数字在 denoising / transport 过程中代表的阶段。早期噪声很大,后期细节更多,不同时间段的行为差异可以很剧烈。
这里容易困惑的是:为什么时间 embedding 会突然和“频率”联系起来?
这里的频率不是说 diffusion 过程里真的有某个物理量在振动。它只是一个表示时间的数学工具。做法是把时间 t 放进很多个正弦、余弦函数里:
cos(2πwt),sin(2πwt).
其中 w 就叫频率。令
ϕ(t)=2πwt.
当 t 从 0 走到 1 时,ϕ(t) 从 0 走到 2πw。因此:
- w=1:这对 sin/cos 在 [0,1] 上转一圈;
- w=2:转两圈;
- w=10:转十圈。
w 越大,这个特征对 t 的变化越敏感。两个很接近的时间点,在高频特征下也可能变得容易区分。
这里采用 Fourier features:
TimeEmb(t)=d2cos(2πw1t)⋮cos(2πwd/2t)sin(2πw1t)⋮sin(2πwd/2t)∈Rd.
频率 wi 取为:
wi=wmin(wminwmax)d/2−1i−1,i=1,…,d/2.
这组频率从低到高覆盖不同时间尺度。低频让模型感知粗粒度阶段,高频让模型区分很接近的时间点。可以把每一对
(cos(2πwit),sin(2πwit))
想成一个在圆上转动的指针;不同的 wi 是不同转速的指针。模型拿到的不是单一时间坐标,而是一组不同分辨率的时间坐标。
这一步的意义是让网络更容易学习复杂的时间依赖。若直接输入 t,网络需要自己从一个标量里构造出复杂的非线性时间函数;Fourier features 先提供一组基础波形,后面的 MLP 或 Transformer 层只需要组合它们,就能表达更丰富的时间变化。
前面的系数
d2
让 embedding 的范数保持稳定。因为对每个频率都有
cos2(2πwit)+sin2(2πwit)=1,
所以整体 embedding 不会因为维度变大而尺度失控。
直观地说,time embedding 不是为了机械地记录 t 的数值,而是把 t 展开成一组不同尺度的时间信号,让网络更容易表达随时间变化的向量场:
t⟼utθ(x∣y).
Embedding class labels.
如果 yraw 是离散类别,比如 MNIST 里的
yraw∈{0,1,…,9},
最自然的做法是为每个类别学习一个 embedding vector:
y=ClassEmb(yraw)∈Rd.
这些 embedding 是模型参数的一部分,会和 utθ 一起训练。它的意义和 NLP 里的 word embedding 类似:类别编号本身没有几何意义,但训练后的向量会变成模型可使用的条件信息。
Embedding textual input.
如果 yraw 是文本 prompt,情况更复杂。文本不是一个固定维度的类别,而是一个 token sequence,并且语言里有语义、顺序、修饰关系。
现代图像生成模型通常不从零开始学习文本理解,而是使用 frozen pretrained text encoder。例如 CLIP 会把图像和文本放到同一个 embedding space 中训练:匹配的图像-文本对靠近,不匹配的对远离。
因此可以写成:
y=CLIP(yraw)∈RdCLIP.
但把整个 prompt 压成一个向量有时不够。比如 prompt 里有多个对象、属性、空间关系,一个单向量可能丢失 token-level 的细节。因此很多模型会使用 transformer text encoder,保留一串 token embeddings:
PromptEmbed(yraw)∈RS×k.
这里 S 是文本 token 数,k 是每个 token embedding 的维度。这样图像 token 可以通过 attention 去看 prompt 里的不同 token。
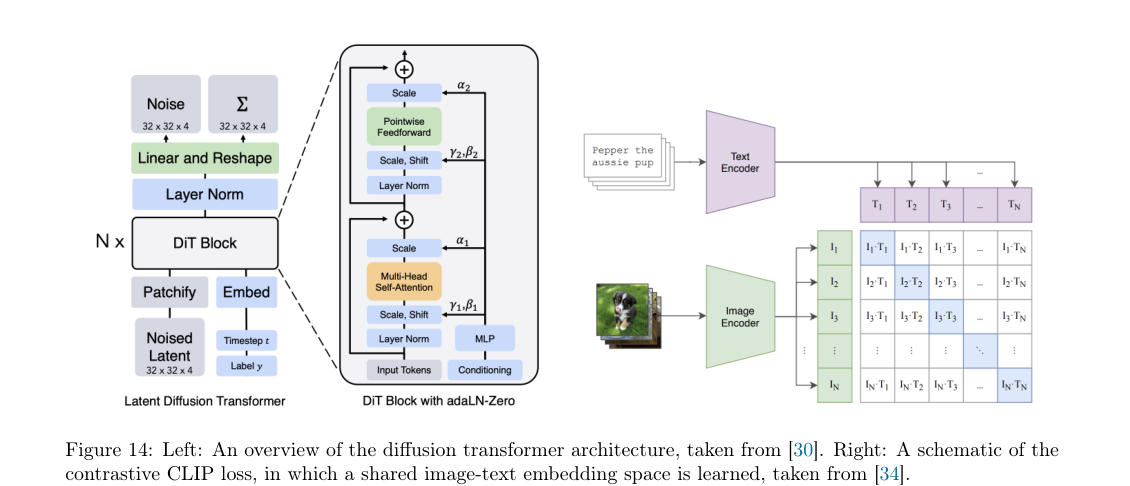
Figure 14 右边展示的就是 CLIP 的思想:图像 encoder 和文本 encoder 被训练到同一个空间里,使匹配的 image-text pair 相似度更高,不匹配的 pair 相似度更低。这个 embedding 后面就可以作为生成模型的条件输入。
Diffusion Transformer,简称 DiT,可以理解为把 Vision Transformer 的思路放进 diffusion / flow model 里。
一张图像写成:
x∈RC×H×W.
Transformer 擅长处理 token sequence,所以第一步要把图像切成 patch。设 patch size 是 P,则每个 patch 包含
C′=CP2
个数值。patch 的数量是:
N=PH⋅PW.
于是 patchify 操作把图像变成:
Patchify(x)∈RN×C′.
接着用一个可学习矩阵 W∈RC′×d 把每个 patch 投影到 transformer hidden dimension:
PatchEmb(x)=Patchify(x)W∈RN×d.
现在,模型的三个输入都变成了 transformer 能处理的形式:
t~=TimeEmb(t)∈Rd,
y~=PromptEmbed(y)∈RS×d,
x~0=PatchEmb(x)∈RN×d.
然后 DiT 用 L 层 transformer block 反复更新图像 patch tokens:
x~i+1=DiTBlock(x~i,t~,y~),i=0,…,L−1.
最后再把 token sequence 转回图像形状:
u=Depatchify(x~LW~)∈RC×H×W,
其中
W~∈Rd×C′.
这个 u 就是模型预测的向量场:
u=utθ(x∣y).
DiT block 里有三类核心操作。
第一类是 patch self-attention。每个图像 patch 可以看其他 patch,从而建模全局结构。比如左上角的物体边缘可能和右下角的阴影相关,attention 可以直接建立远距离关系。
如果当前 patch tokens 是
x∈RN×d,
普通 self-attention 可以写成:
SelfAttn(x)=MultiHeadAttention(x,x).
这里两个 x 的含义是:queries 来自图像 patch,keys 和 values 也来自图像 patch。因此每个 patch 都在图像内部寻找相关信息。
第二类是 cross-attention。图像 patch tokens 作为 queries,文本 tokens 作为 keys 和 values,使每个图像区域可以选择性地关注 prompt 的不同部分。
如果文本 embedding 是
y∈RS×d,
cross-attention 可以写成:
CrossAttn(x,y)=MultiHeadAttention(x,y).
这里 queries 来自图像 patch,keys 和 values 来自文本 tokens。直观地说,每个图像区域都可以根据自己当前的状态去 prompt 里找相关词。prompt 里的 “red car on the beach” 不会被压成一个单一标签,而是以 token sequence 的形式被图像 patches 反复读取。
第三类是 time conditioning。时间 t 不只是额外输入,而是会调制每一层的归一化或残差强度。这一点是 DiT block 里最重要、也最容易被忽略的部分。
普通 Transformer block 通常会先做 LayerNorm:
LN(x).
LayerNorm 的作用是把每个 token 的 hidden features 归一化,让训练更稳定。可是 diffusion / flow model 有一个额外要求:同一个图像 token 在不同时间点应该被不同地处理。t 靠近噪声端时,网络更偏向粗结构;t 靠近数据端时,网络更偏向细节修正。
AdaLN 的想法是:先正常归一化,再让时间 embedding 决定这一层如何缩放和平移归一化后的特征。
(γ,β)=g(t~),
AdaNormt~(x)=(1+γ)⊙Norm(x)+β.
其中 g 是一个小 MLP,输入是 time embedding:
t~=TimeEmb(t).
输出的 γ,β∈Rd 会广播到所有 patch tokens 上。也就是说,它们不是改变某一个 patch,而是改变这一层处理全部 patch 的方式。
所以 AdaLN 的物理直觉是:
时间 t 不是一个被动附加的标签,而是在控制网络每一层的工作模式。
当 t 不同时,同一个 block 里的 attention 和 MLP 会接收到不同调制后的输入。于是同一个 DiT block 可以在不同时间段表现出不同功能。
把这些操作放在一起,一个简化的 DiT block 可以写成:
x←x+SelfAttn(AdaLNt~(x)),
x←x+CrossAttn(AdaLNt~(x),y),
x←x+MLP(AdaLNt~(x)).
Figure 14 里的 adaLN-Zero 还多了 gate。更接近图里的写法是:
x←x+αattn(t~)⊙SelfAttn(AdaLNt~(x)),
x←x+αmlp(t~)⊙MLP(AdaLNt~(x)).
这里 αattn(t~) 和 αmlp(t~) 也是由 time embedding 产生的门控系数。它们决定这一层的 self-attention 和 MLP 输出到底加多少回残差流里。
“Zero” 通常指这些调制或 gate 在初始化时接近零,使 block 一开始接近恒等映射:
x←x.
这对深层 diffusion transformer 很有用。模型刚开始训练时不会让每一层都大幅扰动输入,而是逐渐学会在不同时间点打开哪些层、打开多少。
因此 DiT block 的完整直觉是:
- self-attention 负责图像 patch 之间的信息交换;
- cross-attention 负责让图像 patch 读取 prompt;
- AdaLN 负责让时间 t 调节每一层的工作方式;
- gate 负责控制每个子模块对残差流的贡献强度。
Figure 14 左边展示了 DiT 的整体流程:noised latent 先被 patchify,加入 timestep 和 label conditioning,然后经过多层 DiT block,最后 reshape 回原来的 latent/image 形状。
6.1.3 U-Net
U-Net 是另一类非常重要的 diffusion architecture。它原本来自图像分割,后来在 diffusion models 里被广泛使用。
U-Net 的核心特点是:输入和输出都保持图像形状。对生成模型来说,这正好对应:
xt⟼utθ(xt∣y).
举一个形状例子。如果输入是:
xtinput∈R3×256×256,
encoder 会逐步降低空间分辨率、增加通道数:
xtlatent=E(xtinput)∈R512×32×32.
然后 midcoder 在低分辨率、高通道的表示上处理全局信息:
xtlatent=M(xtlatent)∈R512×32×32.
最后 decoder 再把表示恢复到原始图像大小:
xtoutput=D(xtlatent)∈R3×256×256.
这个输出就是:
utθ(xt∣y).
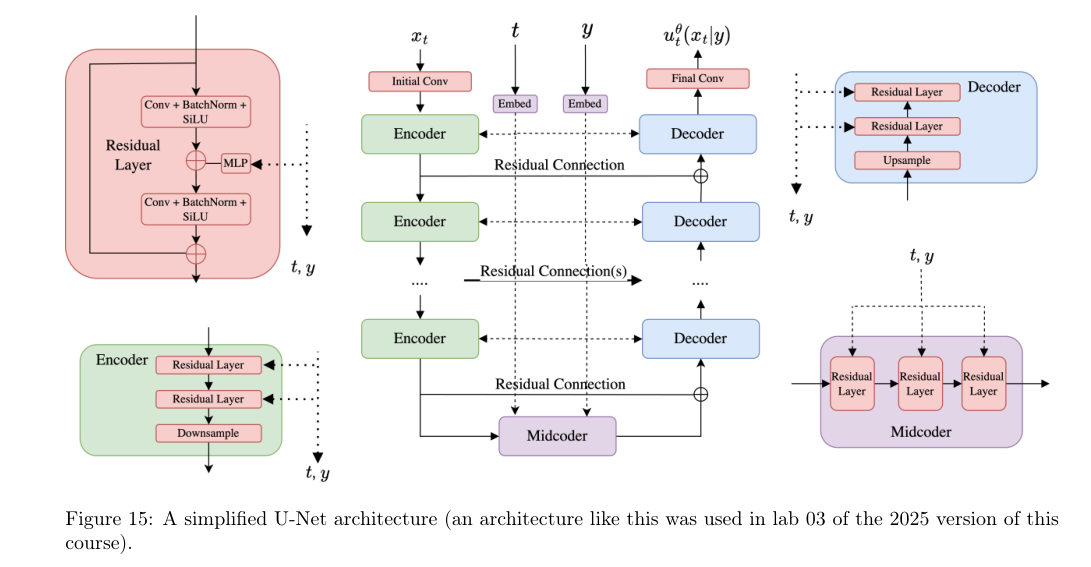
Figure 15 里间的主干就是 U 形结构:左边 encoder 不断下采样,右边 decoder 不断上采样,中间是 midcoder。虚线 residual connections 把 encoder 的中间特征传给对应尺度的 decoder。
这些 skip connections 很关键。原因是:encoder 压缩图像时会丢掉一些局部细节,而 decoder 要恢复像素级输出。如果只靠最底部的 latent,恢复细节会很困难;skip connections 让 decoder 能直接拿到高分辨率特征。
时间 t 和条件 y 也会被 embedding 后注入到 U-Net 的不同模块里。图里虚线标出的 t,y 表示这些条件不会只在输入层出现一次,而是会影响网络的多个层级。这样模型才能在不同空间尺度上都知道:现在是哪个 denoising 时间点,以及要生成什么条件下的样本。
从功能上看,DiT 和 U-Net 都是在实现同一个数学对象:
utθ(x∣y).
差别在于它们处理图像结构的方式不同:
- U-Net 依赖卷积、下采样、上采样和 skip connections,天然保留局部空间结构;
- DiT 把图像变成 patch tokens,用 attention 建模全局关系,并且更容易接入文本 token conditioning。
第 6.1 节的要点可以收成一句话:
大规模 diffusion / flow model 的网络部分,就是把 x,t,y 分别变成合适的表示,再用 U-Net 或 DiT 这样的结构预测与 x 同形状的 vector field。
6.2 Working in Latent Space: (Variational) Autoencoders
6.1 讨论的是网络结构本身。现在的问题是:即使用了 U-Net 或 DiT,直接在高分辨率像素空间里建模仍然很贵。
一张 RGB 图像如果大小是 1024×1024,那么它的维度是:
d=3×1024×1024≈3×106.
如果是视频,还要再乘上帧数 T:
x∈RT×C×H×W.
flow / diffusion model 和分类模型不同。分类模型可以把图像逐步压缩,最后输出一个很小的类别向量;但生成模型要输出和输入同形状的向量场:
utθ(x)∈Rd.
所以如果直接在像素空间训练,模型每一步都要处理一个极大的对象。现代图像生成模型的关键做法是:不在原始像素空间生成,而是在一个压缩后的 latent space 里生成。
6.2.1 Standard Autoencoders
autoencoder 的想法很直接:用一个 encoder 把图像压缩成 latent,再用一个 decoder 把 latent 还原成图像。
设原始数据是:
x∈Rd.
encoder 是:
μϕ:Rd→Rk,
decoder 是:
μθ:Rk→Rd,
其中
k≪d.
编码得到:
z=μϕ(x)∈Rk.
再解码得到:
x^=μθ(z)=μθ(μϕ(x)).
训练 autoencoder 的基本目标是 reconstruction loss:
LRecon(ϕ,θ)=Ex∼pdata[∥μθ(μϕ(x))−x∥2].
这个目标只要求“压缩后还能还原”。如果只为了压缩和重建,这已经很自然。
但我们这里不是只想做压缩。我们最终想在 latent space 里训练一个生成模型。也就是说,我们希望:
- 把真实图像编码成 latent:
z=μϕ(x),x∼pdata.
- 在 latent space 里学习 latent distribution:
platent(z).
- 采样 latent,再 decode 回图像:
z∼platent,x=μθ(z).
问题在于,普通 autoencoder 没有约束 platent(z) 的形状。它可能很扭曲、很碎、很难学。换句话说,autoencoder 虽然把像素空间压缩了,但可能把原来的数据分布变成了另一个很难建模的 latent distribution。
因此需要一个额外要求:
latent 不仅要能重建图像,还要形成一个适合生成模型学习的分布。
这就是 VAE 要解决的问题。
6.2.2 Variational Autoencoders
VAE 把 deterministic autoencoder 改成 probabilistic autoencoder。
普通 autoencoder 的 encoder 是一个确定函数:
z=μϕ(x).
VAE 的 encoder 变成一个条件分布:
qϕ(z∣x).
decoder 也变成一个条件分布:
pθ(x∣z).
最常见的 Gaussian 设定是:
qϕ(z∣x)=N(z;μϕ(x),diag(σϕ2(x))),
pθ(x∣z)=N(x;μθ(z),σθ2(z)Id).
这时 encoder 不再输出一个 latent 点,而是输出一个 Gaussian distribution 的参数:
μϕ(x),σϕ2(x).
编码时从这个分布里采样:
z∼qϕ(⋅∣x).
解码时也可以理解为从 decoder distribution 采样:
x∼pθ(⋅∣z).
如果方差都退化成 0,VAE 就回到了普通 autoencoder。因此 VAE 不是完全不同的东西,而是 autoencoder 的概率版本。
Reconstruction loss: 现在重建的是概率
普通 autoencoder 用 squared error:
∥x−μθ(μϕ(x))∥2.
VAE 里 z 是随机采样的,所以 reconstruction loss 写成 negative log-likelihood:
LVAE-Recon(ϕ,θ)=−Ex∼pdata,z∼qϕ(⋅∣x)[logpθ(x∣z)].
这句话的意思是:从 x 编码出一个 latent z,再问 decoder 给原始 x 的概率有多高。概率越高,loss 越小。
在 Gaussian decoder 下,代入正态分布密度,可以得到:
LVAE-Recon(ϕ,θ)=Ex,z[2σθ2(z)1∥x−μθ(z)∥2+2dlogσθ2(z)]+const.
如果把 decoder variance 固定成常数 σ2,这基本就退化成加权 MSE:
LVAE-Recon(ϕ,θ)=Ex,z[2σ21∥x−μθ(z)∥2]+const.
所以 VAE 的 reconstruction term 并不神秘。它仍然在要求 decode 后接近原图,只是现在要对 encoder 采样出来的所有可能 latent 做平均。
Prior loss: 让 latent distribution 变得好学
VAE 还会指定一个理想的 latent prior:
pprior(z)=N(0,Ik).
这个 prior 表示:我们希望每个数据点编码出来的 latent distribution 不要乱跑,而是接近标准 Gaussian。于是加入 KL loss:
LVAE-Prior(ϕ)=Ex∼pdata[DKL(qϕ(⋅∣x)∥pprior)].
KL divergence 衡量两个分布有多不同:
DKL(q∥p)=∫q(z)logp(z)q(z)dz.
它满足:
DKL(q∥p)≥0,
并且当且仅当 q=p 时为 0。
所以这个 prior loss 的直觉是:
每张图像的 encoder distribution 都应该尽量像 N(0,Ik),这样整体 latent space 会更规整,更适合后面训练 flow / diffusion model。
最终 VAE 目标是:
LVAE(ϕ,θ)=LVAE-Recon(ϕ,θ)+βLVAE-Prior(ϕ).
也就是:
LVAE(ϕ,θ)=−Ex,z[logpθ(x∣z)]+βEx[DKL(qϕ(⋅∣x)∥pprior)].
这里 β 控制两件事的权衡:
- β 小:更重视重建质量,latent 可能不够规整;
- β 大:更强迫 latent 接近 Gaussian,但可能牺牲重建细节。
Gaussian encoder 下的 KL 项
若
qϕ(z∣x)=N(μϕ(x),diag(σϕ2(x))),
并且
pprior(z)=N(0,Ik),
则 KL 项有闭式解:
DKL(qϕ(⋅∣x)∥N(0,Ik))=21j=1∑k(μϕ,j2(x)+σϕ,j2(x)−logσϕ,j2(x)−1).
这四项也很直观:
- μϕ,j2(x) 惩罚 mean 偏离 0;
- σϕ,j2(x)−logσϕ,j2(x)−1 惩罚 variance 偏离 1。
因此 KL 项把 encoder distribution 往标准 Gaussian 拉。
Reparameterization trick
VAE 训练还有一个技术点:我们需要从
z∼qϕ(z∣x)
里采样,但这个采样分布依赖参数 ϕ。如果直接采样,梯度不好传。
reparameterization trick 把随机性单独拿出来:
ϵ∼N(0,Ik),
z=μϕ(x)+σϕ(x)⊙ϵ.
这样仍然有:
z∼qϕ(⋅∣x),
但随机性来自 ϵ,它的分布不依赖 ϕ。而 μϕ(x) 和 σϕ(x) 都在计算图里,梯度可以正常反传。
这一步的直觉是:
不要让“从一个依赖参数的分布里采样”挡住梯度;把采样写成“固定噪声经过可微变换”。
Algorithm 6: β-VAE training
Algorithm 6 把前面的 VAE 训练过程写成 mini-batch 算法:

每个 batch 中,对每张图像 xi:
- encoder 输出:
μi=μϕ(xi),logσi2=logσϕ2(xi).
- 采样标准 Gaussian noise:
ϵi∼N(0,Ik).
- 用 reparameterization trick 得到 latent:
zi=μi+σi⊙ϵi.
其中:
σi=exp(21logσi2).
- decoder 输出 reconstruction mean:
x^i=μθ(zi).
- reconstruction loss:
Lrecon=B1i=1∑B2σ~21∥xi−x^i∥2.
- KL loss:
LKL=B1i=1∑B21j=1∑k(μi,j2+σi,j2−logσi,j2−1).
- total loss:
L=Lrecon+βLKL.
然后对 encoder 参数 ϕ 和 decoder 参数 θ 做梯度更新。
为什么这对 diffusion / flow 有用
VAE 训练完成后,生成模型不再直接学习像素空间分布:
pdata(x).
而是学习 latent space 里的分布:
platent(z),z∼qϕ(z∣x),x∼pdata.
训练 latent flow / diffusion 时,把 latent z 当成数据点来用:
z∈Rk.
模型学会从简单分布生成 latent:
Z1∼platent.
最后再用 decoder 回到图像:
x=μθ(Z1).
这就是 latent diffusion / latent flow 的基本结构:
noise⟶latent generative model⟶z⟶decoder⟶x.
本节的核心可以收成一句话:
VAE 先把高维图像压缩到规整的 latent space,flow / diffusion model 再在这个更小、更好学的 latent space 里做生成。
6.3 不再引入新的数学框架,而是把前面几节的部件拼起来,看真实大模型大概怎样落地。
到这里,图像/视频生成模型的主要积木已经有了:
- 用 flow matching 或 diffusion 学一个生成过程;
- 用 CFG 强化 prompt condition;
- 用 text encoder 把 prompt 变成 embedding;
- 用 VAE / autoencoder 把像素压到 latent space;
- 用 DiT 或 U-Net 参数化
utθ(x∣y).
Stable Diffusion 3 和 Movie Gen Video 的共同点是:它们都不是只靠一个单独技巧,而是把这些部件规模化组合起来。
6.3.1 Stable Diffusion 3
Stable Diffusion 3 是一个 text-to-image model。它的目标可以写成:
x∼pdata(⋅∣y),
其中 y 是文本 prompt,x 是图像。
但它并不直接在像素空间里建模,而是在 autoencoder 的 latent space 里做生成。也就是说,真实图像先经过一个 pretrained autoencoder encoder:
ximage⟼zlatent.
生成模型学的是 latent 上的条件分布:
platent(z∣y).
采样结束后,再用 decoder 得到图像:
z⟼ximage.
因此 Stable Diffusion 3 里真正的 vector field 更准确地说是在 latent space 上:
utθ(zt∣y).
Stable Diffusion 3 使用的是 conditional flow matching 目标。也就是我们前面学过的逻辑:构造从简单分布到数据分布的 probability path,然后训练网络匹配对应的 velocity field。
它还使用 classifier-free guidance。训练时随机丢掉 prompt condition,使同一个模型同时学会:
utθ(zt∣y)
和
utθ(zt∣∅).
采样时再组合:
u~tθ(zt∣y)=utθ(zt∣∅)+w(utθ(zt∣y)−utθ(zt∣∅)).
这里 w 是 guidance scale。SD3 采样时通常用 Euler simulation,约 50 个 steps,CFG weight 大约在 2.0 到 5.0 之间。
文本条件:为什么要多个 text encoders
Stable Diffusion 3 的一个重要设计是使用多个文本 embedding。它使用三类 text embeddings,包括 CLIP embeddings 和 Google T5-XXL encoder 的 sequential outputs。
可以这样理解:
CLIP embedding 擅长提供整体语义。比如 prompt 是:
a corgi dog wearing sunglasses on the beach
CLIP 会给出一个比较全局的 text-image semantic representation。它告诉模型:这句话整体上描述的是怎样的图像。
T5 这类 transformer text encoder 则更擅长保留 token-level 信息。它不会只给出一个整体向量,而是输出一串 token embeddings:
y=PromptEmbed(yraw)∈RS×d.
这对复杂 prompt 很重要。因为图像里不同区域可能需要关注不同词:
- 某些 patch 关注 “corgi”;
- 某些 patch 关注 “sunglasses”;
- 背景 patch 关注 “beach”。
这也是为什么 MM-DiT 需要让 image tokens 和 text tokens 更细粒度地交互。
你给的 Figure 16 对应 MM-DiT 架构:
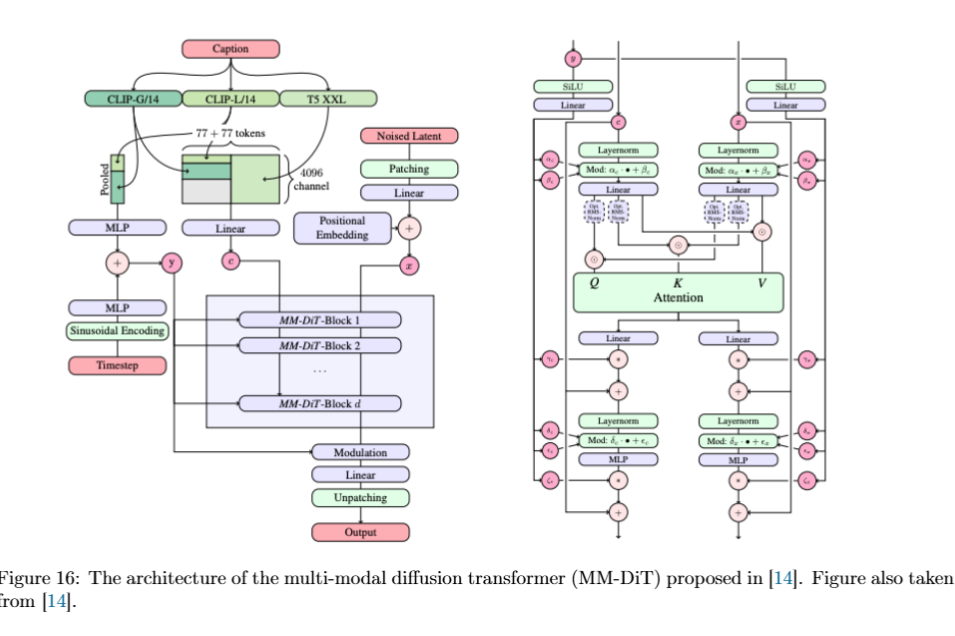
图左边是整体流程,右边是一个 MM-DiT block 的结构。
整体输入有三类:
- noised latent:
zt;
- timestep:
t;
- caption / prompt:
yraw.
noised latent 先被 patching:
zt⟼z~t∈RN×d.
文本 prompt 经过多个 text encoders,例如 CLIP-G/14、CLIP-L/14、T5-XXL,得到 text tokens:
y~∈RS×d.
timestep 经过 sinusoidal encoding 和 MLP,得到 time embedding:
t~=TimeEmb(t).
然后这些信息进入一系列 MM-DiT blocks。
普通 DiT 可以理解为主要更新 image patch tokens;MM-DiT 的关键变化是:文本 token 和图像 token 都进入 transformer 交互。这样 prompt 不是作为一个外部条件轻轻加一下,而是参与每一层的多模态 attention。
一种直观写法是,把 image tokens 和 text tokens 看成两个 token streams:
zi∈RN×d,yi∈RS×d.
每一层做联合更新:
(zi+1,yi+1)=MM-DiTBlock(zi,yi,t~).
这样图像 tokens 可以读文本,文本 tokens 也可以被当前生成状态影响。最后只取 image stream,经过 modulation、linear、unpatching,得到和 latent 同形状的输出:
utθ(zt∣y).
Figure 16 右边的 block 里,LayerNorm 后面有 Mod,也就是前面 6.1 讲过的 time-conditioned modulation。这里的时间 embedding 仍然在控制每一层如何处理 tokens。
因此 SD3 的结构可以概括为:
text promptCLIP/T5text tokens,
noised latentpatchingimage tokens,
(text tokens,image tokens,t)MM-DiTutθ(zt∣y).
Stable Diffusion 3 最大模型有约 8B parameters。这个数字本身不是核心,核心是:当模型规模上去以后,architecture 必须能同时处理高维 latent、长 prompt、多模态条件和时间调制。
Movie Gen Video 是 text-to-video model。它和 Stable Diffusion 3 的框架很像,但数据从图像变成视频。
图像 latent 可以写成:
z∈RC×H×W.
视频多了时间维度:
x∈RT×C×H×W.
这里 T 是帧数。这个维度让问题明显更贵,因为模型不仅要生成每一帧,还要保持帧与帧之间的时间一致性。
Movie Gen Video 同样使用 conditional flow matching,并采用 straight-line Gaussian path:
αt=t,σt=1−t.
也就是我们前面熟悉的:
xt=tz+(1−t)ϵ.
对应 target velocity 是:
uttarget(xt∣z)=z−ϵ.
不过这里的 z 不是单张图像,而是视频 latent。
视频为什么更需要 latent space
视频如果直接在像素空间建模,维度是:
T×C×H×W.
比图像还要大很多。因此 Movie Gen Video 使用 frozen pretrained temporal autoencoder。它把原始视频:
x′∈RT′×3×H′×W′
压缩成 latent video:
x∈RT×C×H×W.
压缩比例大致满足:
TT′=HH′=WW′=8.
这表示 autoencoder 不只在空间上压缩 H,W,也在时间维度上压缩 T。这就是 temporal autoencoder 的意义:它不是逐帧压缩图片,而是把视频作为带时间结构的对象来压缩。
对于长视频,还可以使用 temporal tiling:把视频切成多个时间片段,分别 encode,再把 latent 拼起来。这样可以降低显存压力。
Movie Gen 的 DiT-like backbone
Movie Gen 的生成模型仍然是 DiT-like backbone。但这里的 patch 不只是二维图像 patch,而是同时沿时间和空间 patchify。
可以把视频 latent 看成一个三维网格:
T×H×W.
patchify 后得到一串 spatio-temporal tokens。每个 token 对应某一段时间和某一块空间区域。
Transformer 需要建模两类关系:
- 空间关系:同一帧内不同区域如何协调;
- 时间关系:不同帧之间如何保持运动连续。
文本 conditioning 也类似 SD3,通过 text embeddings 和 cross-attention 注入。Movie Gen 使用 UL2、ByT5、MetaCLIP 三类 embeddings:
- UL2 更偏向一般语言理解;
- ByT5 关注字符级细节,例如 prompt 要求画面里出现具体文字;
- MetaCLIP 提供 text-image shared embedding space。
最大 Movie Gen Video 模型约 30B parameters。这里的规模比 SD3 更大,并不奇怪,因为视频生成比图像生成多了时间维度,需要模型同时解决画面质量和运动一致性。
6.3 的总结构
Stable Diffusion 3 和 Movie Gen Video 都可以放回同一个框架里:
raw dataautoencoderlatent data,
prompttext encoderstext embeddings,
(noised latent,t,text embeddings)DiT / MM-DiTutθ(⋅∣y),
simulate ODE/SDE⟶generated latentdecoderimage or video.
第 6 节的总要点是:大规模生成模型并没有换掉前面学过的 flow matching / diffusion 原理;它们主要是在三个地方做工程和架构放大:
- 更强的 conditioning:多个 text encoders、CFG、多模态 attention;
- 更省的表示空间:autoencoder / latent diffusion;
- 更可扩展的主干网络:U-Net、DiT、MM-DiT、video DiT。
因此可以把这一节收成一句话:
Stable Diffusion 3 和 Movie Gen Video 是前面数学框架的规模化实现:在 latent space 里,用带时间调制和文本条件的 transformer 学习 conditional vector field。