本文将结合学习笔记中的核心思想,将强化学习 Reinforcement Learning 的底层数学原理进行直观的推导和总结。
1. 强化学习的基础概念:马尔可夫决策过程 MDP
强化学习的系统抽象为一个核心数学模型——马尔可夫决策过程 Markov Decision Process, MDP。 马尔可夫决策过程主要由以下几部分组成:
- 集合 Sets:包括状态空间 、动作空间 以及奖励空间 。
- 概率分布 Probability distribution:包括状态转移概率 和奖励概率。其中的核心是马尔可夫性 Markov property,即“无记忆性”——未来的状态只依赖于当前状态和动作,与过去的历史无关。
- 策略 Policy:,即在状态 下采取动作 的概率分布。需要深刻理解的是:一旦具体给出了策略,系统就不再有决策 decision 过程了,而是退化成了一个马尔可夫奖励过程。
奖励与回报
- 奖励 Reward:这是人机交互接口 human-machine interface,我们利用它来优化策略。奖励只依赖于当前状态和动作,与下一个状态无关,即 。
- 回报 Return:用来评价一个策略究竟好不好,是我们评估轨迹、优化动作的根本目标: 在这里引入折扣因子 Discount rate 的目的是把无限长的累加和 infinite sum 变成有限的 finite,使其在数学上收敛。
- 对于连续或者回合制任务 Episode tasks:通过把“到达目标点”后视作进入一个能够不断获得 0(或正)奖励的吸收状态 absorbing state,我们可以统一处理连续任务和周期任务。
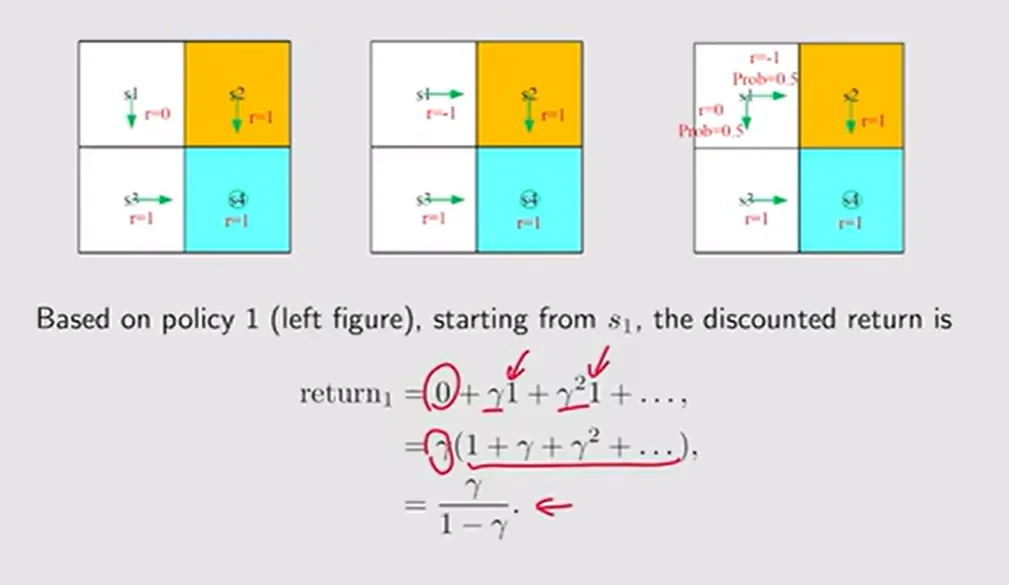
【回报概念例题分析】:在这个简单的网格世界中,可以看到不同策略带来的不同回报。如果智能体每前进一步会获得负奖励(如 -1 的碰撞或者前进一步的惩罚),那么折扣因子加上这样的奖励模型,本质上是在驱使智能体“用最短的路径到达目标”。回报的大小直观反映了某个轨迹走向目标的高效程度,从而让我们能去甄别什么才是“好策略”。
2. 贝尔曼方程 Bellman Equation 的详细剖析
为什么我们需要考察回报?因为每个轨迹的回报能够揭示策略的优劣,而状态价值 State value本质上就是多条轨迹可能产生的回报的数学期望。
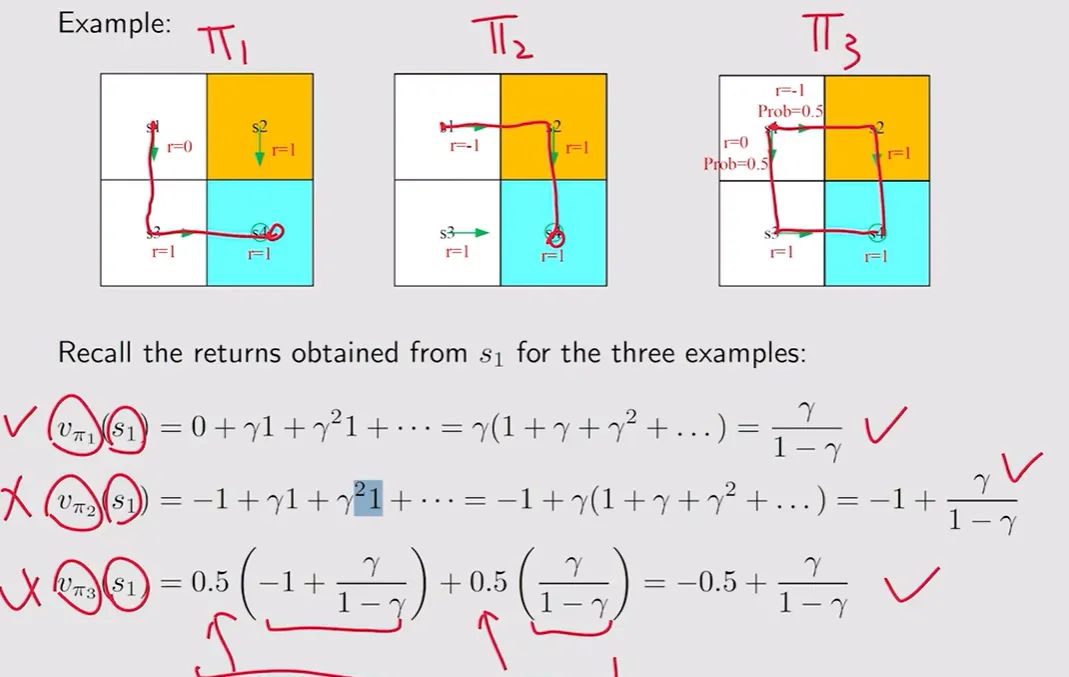
【状态价值与回报的区别例题分析】:这道题很直观地指出,如果起点动作或转移具有随机性(即可能走到不同的轨迹路径),那么在状态 下就不只有一个回报。我们需要将各条轨迹对应的回报乘上对应动作和转移的概率(加权平均)才能算作 真正意义上的状态价值 。但如果在某个状态时,接下来的动作与转移完全确切 deterministic case(如例题中概率都是1的情形),此时期望就退化为普通数值:在这个例子中,确切的一条轨迹下,状态价值就完美等于该轨迹直接算出的回报。
贝尔曼公式的推导 Derivation
我们可以从单步出发,一步步拆解对 的期望。根据定义:
我们将 拆解为即时奖励和未来回报的折现和:
第一部分:即时奖励的期望 在状态 获得即时奖励的过程,取决于两个概率:一是策略 选择动作 的概率,二是环境产生对应奖励的概率 。
第二部分:未来回报的期望 由于环境具有马尔可夫无记忆性,它直接由下一个到达的状态 决定:
结合合并:(如果我们同时考虑 这个联合分布),贝尔曼方程就变成了最完整的形态:
深刻的思考:
- 自举法 Bootstrapping:通过推导我们看到,当前的状态值 是依赖于其他状态值 计算出来的。 这个“用估计值来估计自己”的方法是整个强化学习中最核心的思想(如后的 TD 算法也基于此)。
- 我们能得到上式的完美展开是因为我们假定了已知 ,这叫做基于模型 model-based的求解,上述推演不是无模型 model-free 的。
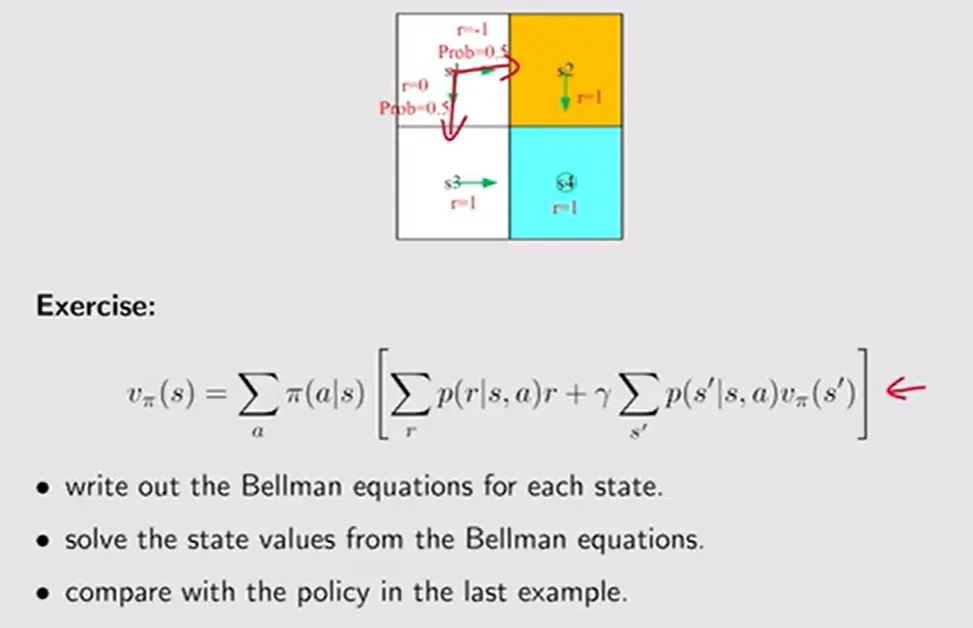

【计算贝尔曼期望例题分析】:图中的例子展示了最简单的确定性情况。如果环境完全稳定、当前策略也就选一个方向推进,那么方程中的连加号(Sum)就消失了,复杂的贝尔曼方程就变成了小学数学方程组:,。这个例子直接告诉我们,在确定性情况下,列出该方程组(有几个状态就能列几个)就能解出所有状态当前的 值,而解得的 值越大,印证此刻在这个格子上这套走法的策略越优秀。
矩阵向量形式 Matrix-Vector Form
当我们有有限个状态时,为了进行编程实现和理论分析,上述的单个非齐次线性方程可以合并书写。首先,重写单步转移概率与奖励项:
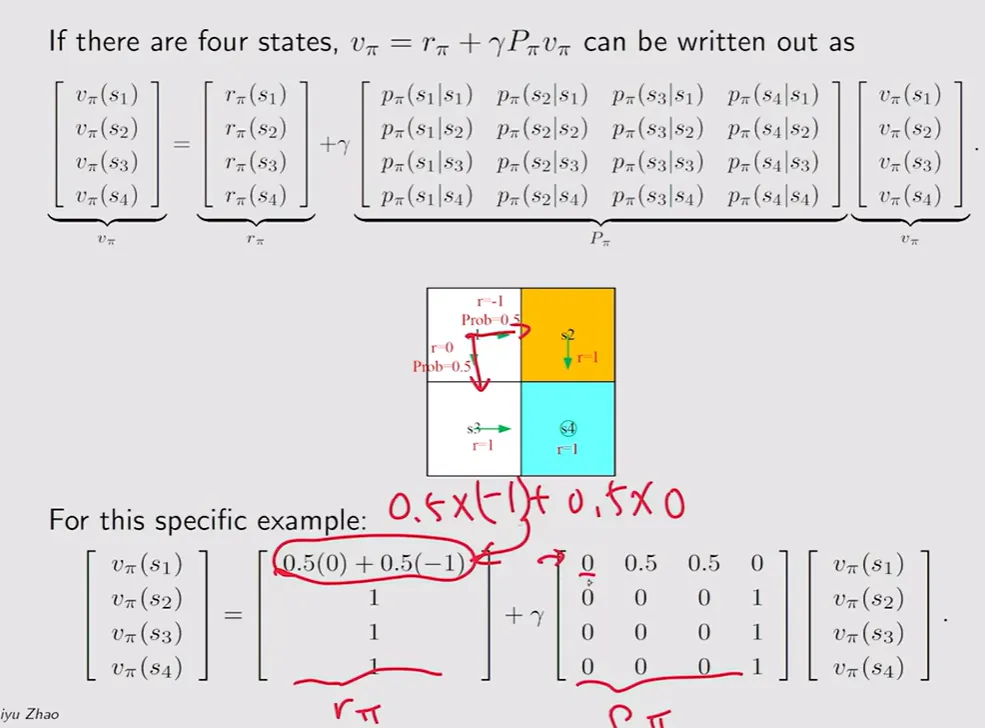
【矩阵重写网格例题分析】:在上面这个例子中,由于每个状态只能向固定的上下左右转移(或者根据策略分别占一定概率),对于具有 个格子的世界,本质上就是一套 元一次方程组。用线性代数 表达即为它的矩阵形式。
方程完美刻画了这种“互相依赖”的自举求解关系:
其中:
- 是状态价值列向量。
- 是当前策略下的期望即时奖励向量。
- 是当前策略引发的状态转移矩阵 State transition matrix。
矩阵形式直接告诉我们,如果要在已知环境概率(即白盒模型)下评估现有策略,只需通过移项求逆,便可得出理论上的解析解(因为矩阵 是可逆的):
计算出来的值代表在状态 下策略的前景,值越大代表该策略 越好。