在上一篇中,我们引入了蒙特卡洛 MC 方法来解决无模型 Model-free 的问题,但其存在一个明显的局限性:必须等待完整的回合 Episode 结束后才能进行价值更新,这导致了反馈的滞后。
针对这一问题,时序差分学习 TD Learning 被提出。TD 方法结合了动态规划的自举 Bootstrapping 思想与 MC 的采样更新机制。此外,为了使强化学习能够处理状态空间巨大或连续的复杂问题,通常需要引入价值函数近似 Value Function Approximation, VFA。本篇将详细梳理这两个核心概念。
7. 时序差分学习 TD Learning
时序差分的核心思想在于利用相邻时间步的估计值差异进行单步更新,而无需等待整个回合结束。当智能体执行一步动作后,利用观测到的即时奖励及下一个状态的价值估计,即可计算出与当前状态价值估计之间的误差,并据此进行修正。
TD Error:时序差分误差
为了建立 时刻和 时刻价值估计之间的联系,TD 引入了以下定义:
- TD Target (目标):。即当前步获得的实际奖励与折扣后的下一状态估计价值之和。
- TD Error (误差):用新的目标值减去当前的估计值:

【TD Error的含义解析】:TD Error 反映了连续两个时间节点状态价值评估的差异。如果 ,说明实际情况好于当前预期;如果 ,说明实际情况差于当前预期。利用 ,我们可以在每一个单步立刻调整状态价值函数,使得 时刻的估计值逐步逼近 时刻的观测结果与估计值之和。
基于 RM/SGD 推导 TD 更新公式
如前文所述,无模型问题的更新过程本质上可以通过随机近似(RM算法)或随机梯度下降(SGD)的形式来表达。 将贝尔曼方程视为需要求解的等式,可以得到 TD 评估的更新法则:
利用这种增量式更新(步长为 ),只要状态被充分访问且步长满足特定的衰减条件,状态价值估计将在交互过程中持续更新并最终收敛。
价值更新算法:SARSA 与 Q-Learning
在策略求解阶段,我们需要将状态价值 转换为动作价值 进行评估与更新:
1. SARSA (State-Action-Reward-State-Action) 动作价值的贝尔曼期望方程为:
由此推导出其 TD 更新公式:

【同策略 On-policy 辨析】:在 SARSA 中,计算 TD Target 时使用的后续动作 是智能体实际执行的动作(例如基于 -greedy 策略采样的动作)。这种行为策略(Behavior policy)与目标策略(Target policy)一致的方法称为 同策略 On-policy,它评估的是智能体当前实际执行策略的价值。
2. Q-Learning 贝尔曼最优方程 BOE 包含了最大化操作:
对应的 TD 更新公式即为 Q-learning:

【离策略 Off-policy 辨析】:Q-Learning 的显著特点在于,更新时计算 TD Target 所使用的动作并不依赖于智能体实际选择的动作,而是直接使用下一状态中具有最大 Q 值的动作 。用于收集数据的行为策略与被评估/优化的目标策略是分离的,这种方法称为 离策略 Off-policy。它通过近似最优动作价值来直接逼近最优策略。
8. 价值函数近似 Value Function Approximation, VFA
传统的表格型 Tabular 强化学习算法需要为每一个状态或状态-动作对分配内存来存储 或 。但在处理连续状态空间或极大的离散状态空间时,会面临两个主要问题:
- 维度灾难:无法提供足够的内存来存储所有状态的价值。
- 缺乏泛化能力 Generalization:表格法将每个状态视为独立的实体,无法利用状态之间的相似性进行泛化学习。
为解决这些问题,引入了价值函数近似 VFA。该方法放弃了表格存储,转而使用一个参数化函数 或 来拟合价值。常见的近似函数包括线性函数或非线性的深度神经网络。

引入目标函数 Objective Function
在参数化表示下,求值问题转化为机器学习中的优化问题:寻找一组参数 ,使得近似函数的输出趋近于真实的价值。为此定义均方误差形式的目标函数:

【平稳分布加权分析】:公式中的 表示在当前策略下状态的平稳分布概率。在连续交互系统中,要求所有状态的拟合误差都最小是不切实际的。引入 的意义在于:赋予高频访问状态更高的拟合权重,而对罕见状态允许较大的误差。这使得有限的函数拟合能力能够集中于智能体交互轨迹上最相关的状态区域。
基于随机梯度下降 SGD 的参数更新
为了最小化目标函数 ,可采用随机梯度下降法。其参数更新法则为:
在实际算法中,需要将真实价值的估计项(Target)代入该公式:
- MC 方法中, 为完整回合的回报 。
- SARSA 方法中,。
- Q-Learning 方法中,。
线性近似与非线性近似
在线性近似(即将状态特征向量与权重 做内积)条件下,由 TD 算法引导的更新具备较好的数学收敛性(TD 定理表明其本质是在特征基底上的投影)。
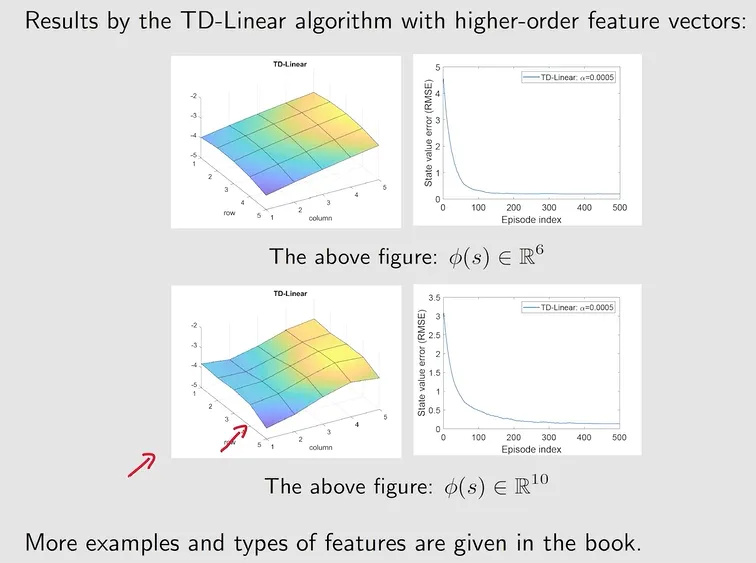
【特征提取与拟合效应分析】: 从不同函数的拟合对比可以看出,使用简单的线性平面拟合复杂的价值曲面往往存在较大的偏差;而采用非线性特征(如高斯径向基函数 RBF)或多层神经网络时,对复杂环境的价值曲面拟合能力显著提升。这为后续的深度 Q 网络 (Deep Q-Network, DQN) 提供了理论基础。
需要注意的是,采用非线性神经网络进行价值近似时,以往线性条件下的收敛性保证不再成立。此外,使用自举 Bootstrapping 构建的目标值往往会导致训练不稳定。因此,在深度强化学习中,通常需要引入“经验回放(Experience Replay)”与“目标网络(Target Network)”等机制来稳定训练过程。