在此前的章节中,值迭代和策略迭代有一个共同的前提:环境模型是已知的(Model-based)。即我们需要知道状态转移概率 。但在实际问题中,环境的运作机制往往是未知的。
本篇将介绍无模型 Model-free 强化学习。首先讨论如何利用经验数据评估策略的蒙特卡洛方法 (Monte Carlo, MC),随后介绍随机近似 Stochastic Approximation 与随机梯度下降 (SGD) 的数学基础,用于解决带有随机噪声的优化问题。
5. 无模型强化学习:蒙特卡洛方法 (Monte Carlo)
在没有环境模型的情况下,一个直观的思路是利用大数定律,通过对样本求平均来逼近期望值。这种基于采样数据进行计算的方法就是蒙特卡洛方法的核心。
MC 策略评估与广义策略迭代
由于缺乏状态转移概率,即使已知状态价值 ,也无法推断出应执行哪种动作。因此,无模型算法的评估目标通常转换为直接估计动作价值函数 (s,a)$$。
蒙特卡洛算法通过让智能体与环境交互,采样完整的轨迹(Episode)来进行评估。

【蒙特卡洛采样求期望解析】:如图所示,当需要计算状态动作对 的价值 (s,a)$$ 时,算法会从 开始,遵循当前策略 并且执行到回合结束,获得具体的累积回报 。通过收集多条经过 的轨迹,对这些回报 取平均值,就可以作为当前 值的估计。
蒙特卡洛优化过程也是广义策略迭代 (Generalized Policy Iteration) 的一种:
- 评估步:通过采样多个 Episode,计算平均值以估计 q。
- 提升步:在每个状态下,采用贪心策略选择当前估计 值最大的动作 作为新策略。
这种方法不依赖环境的概率模型,直接使用实际的反馈数据进行学习。不过由于需要等待回合结束才能计算回报,更新存在一定的延迟。
探索策略:Exploring Starts 与 ε-Greedy
要准确评估策略,必须保证所有的 组合都有机会被访问。理论分析中常使用“探索性出发 (Exploring Starts)”假设,即要求系统能够以随机的 作为每一个回合的起点。但这在实际应用中通常很难实现。
为了在不依赖该假设的情况下保证算法具有探索能力,通常引入软策略 (Soft Policy),其中最常用的是 epsilon-贪心(-greedy)策略。

【-贪心策略思想解析】:在每次选择动作时,不再以 100% 的概率执行当前预期回报最大的动作。而是保留一个较小的概率 ε,将其均匀分配给所有可能的动作,以此来包含一定的随机探索。
-greedy 策略在“利用已知信息 (Exploitation)”与“探索未知状态 (Exploration)”之间提供了一种平衡。它保证了算法在长期运行中能覆盖绝大部分状态。由于策略中包含了随机动作,其评估和优化出的是当前 -soft 设定下的较优策略。在实践中,通常会在训练初期设置较大的 以鼓励探索,随着训练的进行逐步减小 以逼近最优策略。
6. 参数优化与随机近似 Stochastic Approximation
在处理连续状态空间或利用函数逼近价值时,问题往往会转化为参数优化过程。而在强化学习中,环境反馈的数据通常含有随机噪声。如何在带有噪声的观测中进行优化,这是罗宾斯-蒙罗算法 (Robbins-Monro Algorithm,RM算法) 解决的核心问题。
RM 算法与求根问题
假设我们需要寻找某个未知函数 的根(使 = 0 的 w)。我们无法获得 的准确值,只能得到带有随机噪声 的观测值。
RM 算法给出了迭代更新公式,其在存在噪声的情况下依然能够收敛到真实的根,但步长序列 需要满足两个数学条件:
- 步长总和发散:这确保了不管初始值距离真实解多远,算法都有足够的步长累积量去接近解的位置。
- 步长平方和收敛:这意味着更新步长随着迭代次数增加会逐渐逼近于 0,保证在靠近最终解时,更新幅度足够小,从而减弱噪声带来的震荡,实现收敛。

从 RM 到随机梯度下降 (SGD)
上述求根方法同样能够应用于目标函数的极值优化。求目标函数 的极小值点,等价于求解其期望梯度为零的点。
传统的批量梯度下降 (BGD) 在每次更新时需要计算所有样本的期望梯度。为了降低计算复杂度,随机梯度下降 (SGD) 提出仅使用单个(或少量)样本计算得出的梯度方向来替代整体期望梯度。

【随机梯度的 RM 视角分析】:由于单样本梯度存在方差,可以将其看作真实期望梯度与随机噪声的叠加。因此,SGD 的更新形式与求解求根问题的 RM 算法是等价的。根据 RM 算法的收敛条件,只要学习率(步长)按照相应的法则衰减,使用带有随机误差的单样本梯度进行迭代,参数最终也能收敛到极值点。
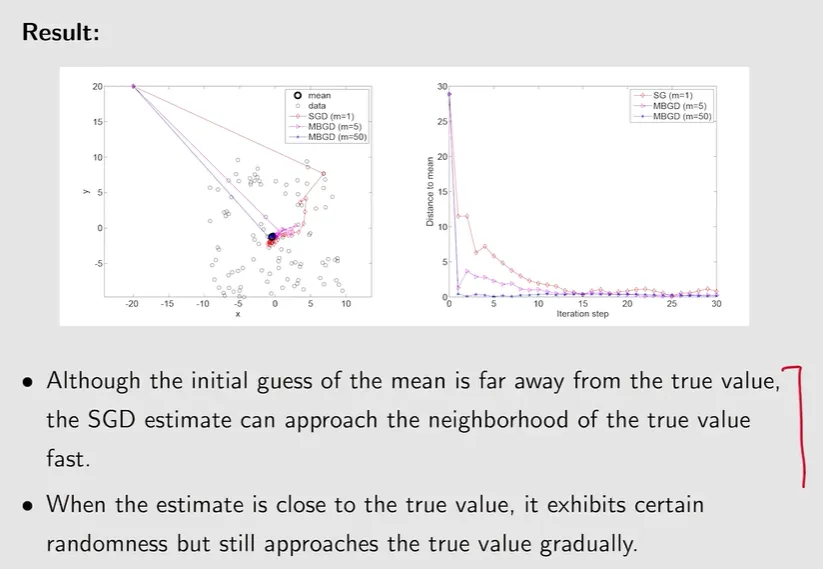
【相对误差与收敛现象分析】:SGD 在迭代过程中的行为可以通过相对误差(梯度噪声与真实梯度的比值)来分析。当当前参数距离最优解较远时,真实梯度的数值较大,引入的相对误差较小,此时参数能够相对稳定地向极小值点移动;而当参数接近最优解时,真实梯度趋近于零,此时单样本的随机噪声占据主导,导致更新轨迹在最优解附近表现出明显的随机波动。
理解随机近似算法和 SGD 的数学性质,是后续进一步学习时序差分 (TD) 算法和价值函数近似 (VFA) 等参数化强化学习方法的重要理论基础。